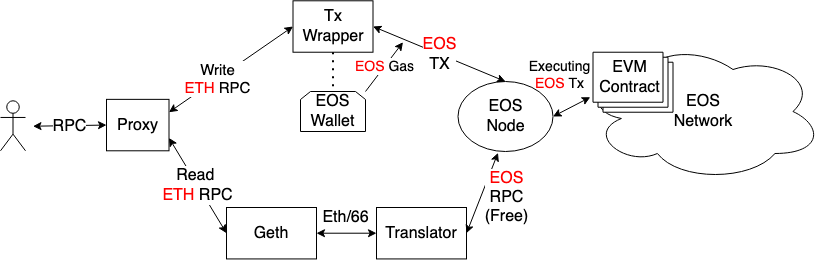
不知道是阅读量到了质变,还是后面引用的这篇文章太好,我终于对BFT-DPOS有了更深刻的理解
POS:
出块不再由算力说了算,由节点持有的stake说了算,解决了POW算力资源被大量无用消耗,但由于无条件信任代表,节点作恶非常容易 , 比如nothing at stake攻击
DPOS:
动态产生一定数量的代表比如21个节点代表,只由这21个节点生成区块,降低了作恶的概率,同时用事后惩罚限制节点代表作恶行为,但始终不够安全(怎么惩罚,使用抵押物?抵押物需要多少?作恶导致的失败交易的损失都是可以量化的吗?如果不能量化抵押物就没有意义),同时确认速度确实也慢(需要14个block)
BFT+DPOS:
一个区块生产后通过BFT协议立马确认,解决了DPOS确认慢问题,需要超过1/3节点才能作恶,相比POW 51%作恶条件,这个1/3值相对来说还是偏低了点,但是这是一个折中,也只能这样了
BFT + DPOS + 小块:
该协议是为了加快出块速度,该改进的核心思想是让同一个节点产生6个小块。这个能提升性能的核心原因是6个小块的产生没有等待确认的环节。在BFT+DPOS算法中,一个节点要创建新块,必须等上一个块被确认(或者超时),因为它不确定上一个节点是否作恶是否会被确认,所以它只能等。但是如果上一个块时也是该节点产生的,它自然不需要等上一块确认,因为它知道上一个块是真实的,不是作恶的块,最后肯定会被确认,所以安心生产下一块。
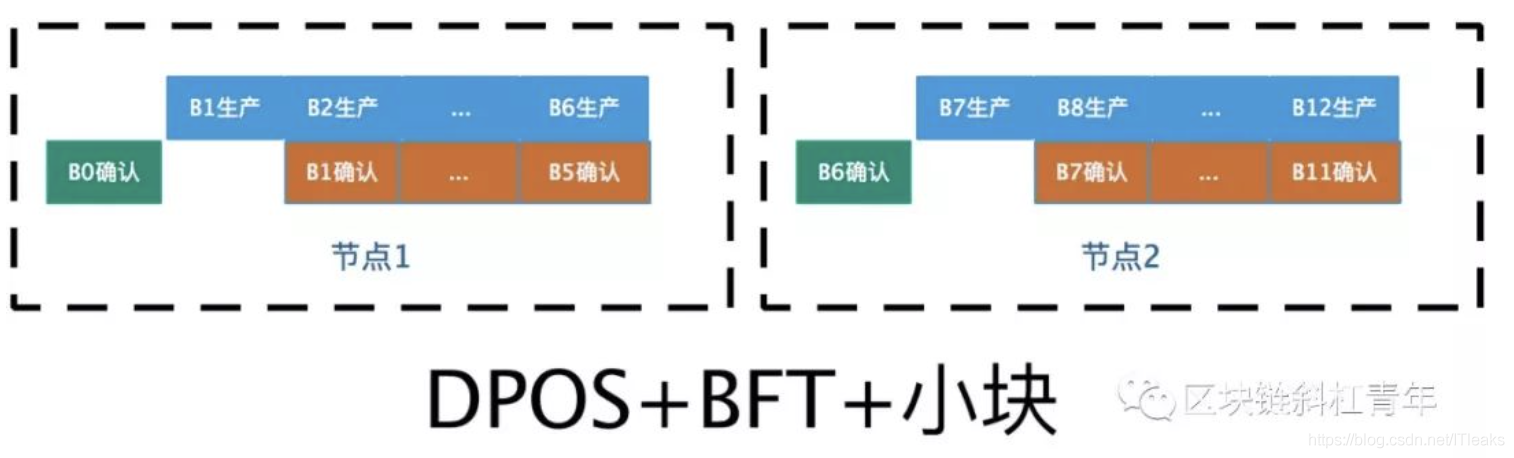
可见DPOS+BFT+小块机制中,区块生成和确认以pipeline的方式进行,是同时进行的,加快了出块速度。
何为作恶:
各种共识算法,节点基本都会进行数据检验功能,因而数据伪造作恶基本不可能。那真正的作恶是什么?
主动作恶:节点主动生产两个区块,给一部分节点发送新区块A,另外一部分节点发送区块A1,这样系统就产生分叉了。
被动作恶: 块传播因为网络延时或者中断,会导致一部分节点缺失该块的信息,进而会产生分叉,然后后续区块生产者发现分叉后,如果遵循只选择一个分支生产区块就会让分叉收敛(能收敛最后就能达成共识),但是如果继续保持并加重这个分叉,最后就会导致整个链变成一颗森林,最后节点就永远没法达成共识, 这是被动作恶。比如POS的noting at stake攻击,当系统出现分叉时,生产者基于自己的利益会在两个分叉区块上各自生成一个区块(这样不管哪个分叉获胜,自己都能获得收益),这其实间接助长和加重了分叉
因而要阻止这些作恶行为,有三种方法:
1)机制保证,让生产者没有时间来生成2个区块(POW)
2)利益保证,生成两个区块最后肯定没用(BFT算法, 大家最后只会认可一个快),生产者获取不了什么好处,自然没必要生产两个区块
3)事后惩罚,比如DPOS,这种方法其实没啥用,因为事后发现作恶节点后,系统没法回溯区块,只能惩罚作恶节点,但是这个作恶损失是不确定的(前面提到过),起不到惩罚作用,且抵押物模式是一种限制,不利于生态发展
引用原文
区块链中最重要的便是共识算法,比特币使用的是POW(Proof of Work,工作量证明),以太币使用的POS(Proof of Stake,股权证明)而EOS使用的是BFT-DPOS。
什么是BFT-DPOS呢?即拜占庭容错式的委任权益证明。
要想明白BFT-DPOS的运行机制,首先就要先明白什么是DPOS。
由于POW在比特币的共识算法中极大地消耗了算法的资源。而且会有算法集中的问题,所以在2014年的时候Dan Larimer提出了一个相较于POW来说更加高效,轻便的共识机制即DPOS。该共识机制一边能让网络成本小型化,另一方面有回复语每个持股人一定的投票权。
这些超级节点呢能够:供相关计算资源和网络资源,保证节点的正常运行;当轮到某超级节点拥有出块权时,超级节点收集该时段内的所有交易,并对交易验证后打包成区块广播至其他超级节点,其他节点验证后把区块添加到自己的数据库中。这种共识机制采用随机的见证人出块顺序,出块速度为 3 秒,交易不可逆需要45秒。为什么需要 45 秒呢?因为 DPoS 下,见证人生产一个新区块,才表示他对之前的整条区块链进行了确认,表明这个见证人认可目前的整条链。而一个交易要达到不可逆状态,需要 三分之二以上的见证人确认,在 EOS 里就是 14 个见证人。DPoS共识算法也有极强的抗分叉能力,因为区块添加到一条区块链分叉的速率与拥有该共识的超级节点比例是相关的。当一个超级节点设法在两条分叉上同时生产区块时,EOS的持有者会在下一轮投票中将该超级节点删掉,并且EOS社区会给予相关恶意节点一定的惩罚。因此,在一般情况下,使用DPoS的EOS都是很难经历分叉的。
其次,我们还要明白BFT所代表的的意义。
拜占庭容错技术(Byzantine Fault Tolerance,BFT)是一类分布式计算领域的容错技术。拜占庭假设是对现实世界的模型化,由于硬件错误、网络拥塞或中断以及遭到恶意攻击等原因,计算机和网络可能出现不可预料的行为。拜占庭容错技术被设计用来处理这些异常行为,并满足所要解决的问题的规范要求。
拜占庭容错技术来源于拜占庭将军问题。拜占庭将军问题是Leslie Lamport在20世纪80年代提出的一个假象问题。拜占庭是东罗马帝国的首都,由于时拜占庭罗马帝国国土辽阔,每支军队的驻地分隔很远,将军们只能靠信使传递消息发生战争时,将军们必须制订统一的行动计划。然而,这些将军中有叛徒,叛徒希望通过影响统一行动计划的制定与传播,破坏忠诚的将军们一致的行动计划。因此,将军们必须有一个预定的方法协议,使所有忠诚的将军能够达成一致,而且少数几个叛徒不能使忠诚的将军做出错误的计划。也就是说,拜占庭将军问题的实质就是要寻找一个方法,使得将军们能在一个有叛徒的非信任环境中建立对战斗计划的共识。在分布式系统中,特别是在区块链网络环境中,也和拜占庭将军的环境类似,有运行正常的服务器(类似忠诚的拜占庭将军),有故障的服务器还有破坏者的服务器(类似叛变的拜占庭将军)。共识算法的核心是在正常的节点间形成对网络状态的共识。
简单形容就是:通过在一群数量有限的节点中,使用轮换或者其他算法来筛选出某个节点作为主节点。并且赋予该节点出块的权利。在主节点是将该时段的交易打包成区块后用自己的私钥对该区块签名,并将其广播到所有节点。当主节点收到至少三分之二的不同节点的签名区块后,则该区块完成了所有节点的验证成为不可逆区块串联到区块链中。
BFT与DPOS二者相结合就诞生了BFT—DPOS共识算法。
、为了挖掘 EOS 系统的性能,Daniel Larimer 在以上基础上又进行了修改。首先,他将出块速度由 3 秒 缩短至 0.5 秒,理论上这样可以极大提升系统性能,但带来了网络延迟问题:0.5 秒的确认时间会导致下一个出块者还没有收到上一个出块者的区块,就该生产下一个区块了,那么下一个出块者会忽略上一个区块,导致区块链分叉(相同区块高度有两个区块)。比如:中国见证人后面可能就是美国见证人,中美网络延迟有时高达 300ms,很有可能到时美国见证人没有收到中国见证人的区块时,就该出块了,那么中国见证人的区块就会被略过。
为解决这个问题,Daniel Larimer 将原先的随机出块顺序改为由见证人商议后确定的出块顺序,这样网络连接延迟较低的见证人之间就可以相邻出块。比如:日本的见证人后面是中国的见证人,再后面是俄罗斯的见证人,再后面是英国的见证人,再后面是美国的见证人。这样可以大大降低见证人之间的网络延迟。使得 0.5 秒的出块速度有了理论上的可能。
为了保证万无一失,不让任何一个见证人因为网络延迟的意外而被跳过,Daniel Larimer 让每个见证人连续生产 6 个区块,也就是每个见证人还是负责 3 秒的区块生产,但是由最初的只生产 1 个变成生产 6 个。最恶劣的情况下,6 个区块中,最后一个或两个有可能因为网络延迟或其他意外被下一个见证人略过,但 6 个区块中的前几个会有足够的时间传递给下一个见证人。
再来讨论 BFT-DPoS 的交易确认时间问题:每个区块生产后立即进行全网广播,区块生产者一边等待 0.5 秒生产下一个区块,同时会接收其他见证人对于上一个区块的确认结果。新区块的生产和旧区块确认的接收同时进行。大部分的情况下,交易会在 1 秒之内确认(不可逆)。这其中包括了 0.5 秒的区块生产,和要求其他见证人确认的时间
使用上述BFT-DPoS协议就可以使得EOS的出块间隔从原来的3秒降低到500毫秒,这也使得跨链通信的时延大大缩短,单位时间内可确认的交易数量大大提升。笔者相信如果这样的机制在EOSIO1.0的正式版本中成功实现,那无疑是区块链技术向支持百万级别用户的目标迈出的巨大一步。
引用原文来自:金色财经
转载自:https://www.cxyzjd.com/article/ITleaks/80359033