多签名钱包常被缩写为 “Multisig wallet”,多签钱包最大的特点是需由多个私钥持有者的授权才能进行钱包交易。本文会为你详细介绍什么是多签钱包、多签钱包的应用场景、多签钱包的工作原理及Gnosis Safe 多签钱包的使用流程
什么是多签钱包?
多签名钱包常被缩写为 “Multisig wallet”,与多签钱包对应的是单签钱包,我们要往区块链上发送一笔转账交易,需要去用钱包去做一个签名,我们自己签好名把交易发送出去,交易执行成功转账就成功,这就是典型的单签钱包,也是我们平时使用最多的钱包。
多签钱包,顾名思义,就是需要多个人去签名执行某个操作的钱包。使用多签钱包进行转账,往往需要 >= 1 个人去签名发送交易之后,转账操作才真正完成。使用多签钱包时,我们可以指定 m/n 的签名模式,就是 n 个人里面有 m 个人签名即可完成操作。可以根据自己的需求设置多签规则,例如:
- 1/2多签模式:两个互相信任的朋友或自己的两个钱包,可以凭各自的私钥独立发起交易(类似于合伙账户)。
- 2/2多签模式:金库中的资金需要2个管理员均同意才能动用这笔资金(需要两个私钥才能转移资金)。
- 2/3多签模式:三个合伙人共同管理资金,为了规避私钥丢失的风险,其中两个私钥签名就可以转移资金。
当然,还有1/3多签、3/6多签、5/8多签不同规则的多签方案,规则是按需的。多签钱包最大的特点是需由多个私钥持有者的授权才能进行钱包交易。我们讲了这么多签名规则,那多签钱包的应用场景是什么呢?
多签钱包的应用场景
多签钱包最常见的应用场景是需求强安全性的个人,以及管理公共资产的投资机构、交易所以及项目方。
1. 资金安全
资金的安全也可以理解为私钥的安全,有一些常见的方案如使用硬件钱包来防止私钥泄露,使用助记词密盒来防止私钥遗忘等等,但依然存在“单点故障”的问题。
在单签钱包中,加密资产的所有权和管理员是在单人手中,一但私钥泄露或遗忘就意味着失去了对钱包的控制权,与之关联的加密资产将完全丢失。而多签钱包的存在,就很大程度上降低了资产损失的风险。以2/3多签模式为例,在全部的3个私钥中,只要有2个私钥完成签名授权就能完成加密资产的转移。
对于个人而言,可以通过一个多签钱包,关联多个钱包地址,分布在多处(类似异地多活、同城多机房),一个放在MetaMask浏览器扩展、一个安装在手机钱包App、一个在冷钱包,需要转移加密资产时只需要用其中的两个钱包共同签名即可。当然为了方便的话,可以使用1/3多签模式,这就类似于把同一个私钥记在三个助记词卡上放在多处一样,但这种方式仅仅是降低了密钥丢失的风险。
2. 资金共管
很多DeFi 协议/DAO 组织/区块链团队其实都有自己的金库,金库里的资产是不能由任何一个人直接动用的,每次动用都要经过多数人的同意或社区投票。这时使用多签钱包来保存金库资产是再合适不过了。
3. 多签操作
在目前这个发展阶段,很多去中心化协议其实都是有个管理员权限的,这个管理员权限往往可以更改协议的某些关键参数。行业普遍做法是把这个管理员权限交给一个多签钱包或时间锁,当需要更改参数时,需要多个人共同签署相关操作。
多签钱包的工作原理
上文中提到的n/m多签方式,多个私钥对应一个多签钱包,这个多签钱包是如何实现的呢?
我们常说的多签主要针对的是比特币和以太坊ERC-20标准代币。在比特币中有2种类型的地址,1开头的是P2PKH表示个人地址,3开头的是P2SH一般表示一个多签地址。普通的比特币地址是由公钥做哈希后得到的,而多重签名地址基于脚本哈希,所以能够实现复杂的交易逻辑。所以在原生上比特币就支持多签。而以太坊原生并不支持多签地址,通常需要依靠智能合约来实现这一机制。因此,比特币多签钱包技术上要更容易实现,也更常见。
在以太坊中,多签钱包往往是一个智能合约。我们以 Gnosis 的一个多签钱包地址的合约为例进行简要阐述,图中截取了核心流程的主要代码,详细可查看:0xcafE1A77e84698c83CA8931F54A755176eF75f2C (如果非开发者可以略过本章节继续往下看)
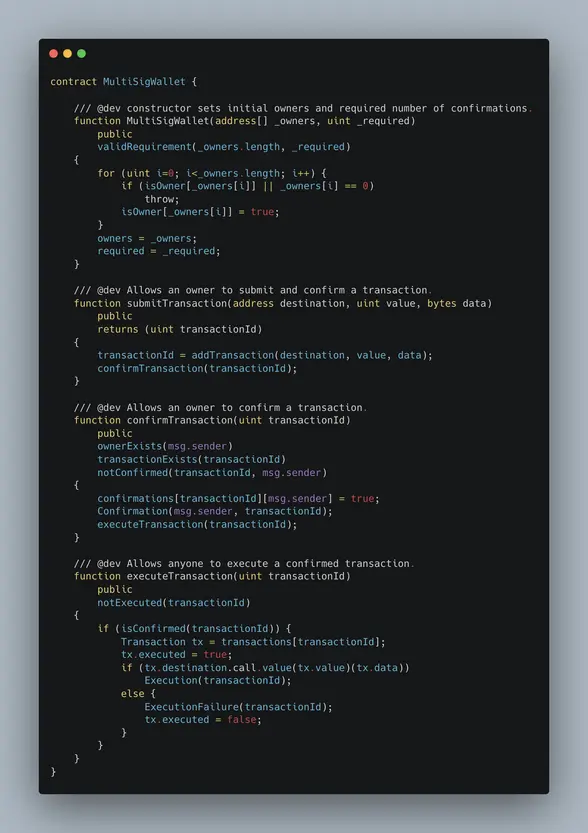
1. 构造多签合约的调用者权限
图中的 constructor 构造方法是合约创建时触发调用的,通过传入 onwers 参数传入授权的多个钱包地址,以及 required 参数表示最少签名人数。
即以M/N多签模式为例,N表示 owners.length ,N表示 required
2. 提交多签钱包交易申请
图中 submitTransaction 方法的作用是多签名人任一一方提交交易申请,返回一个交易号(transactionId 后面会用到)。参数 destination 是接受人的钱包地址,value 为转出的 ether 数量(以 wei 为单位),data 是该交易的数据。
前两个参数比较好理解,向某地址转出多少资产,data 参数可以传入任意数组来实现任意功能,比如如果转出ETH那么此参数是[] (空),如果转出ERC20代码(如USDT),则此参数是ERC20 transfer 方法的哈希和参数 ([0]:xxxxx [1]:xxxxx)。
3. 其余签名人对交易确认
图中的 confirmTransaction 方法的作用是其他参与签名的人发起确认以表示对某个交易执行的认可。参数就是 submitTransaction 流程里提交交易申请时产生的交易号。当然参与者也可以拒绝认可,还有一个 revokeConfirmation 方法来提供拒绝的行为在图中没有体现,可以去合约代码里查看。
4. 正式执行交易操作
当确认的人数达到最低(required)要求,executeTransaction 的内部逻辑将被触发,从而执行第一步用户所提交的逻辑。当 executeTransaction 内部逻辑被触发,即完成了多签合约的真正调用,如上图所述,value 和 data 可以控制多签执行任意逻辑(转移 ether 或 ERC20 代币等)。
常用的多签钱包有哪些?
这一章节并非做多签钱包的推荐,我只罗列出我用过的两个多签钱包,并通过使用流程的介绍来辅助理解合约代码中的逻辑。
- Gnosis Safe https://gnosis-safe.io/
- Ownbit https://ownbit.pro/
Gnosis Safe 是一款为钱包提供多签功能的智能合约。使用不同加密钱包的用户可以在Gnosis Safe 网页端创建一个多签账户,将需要共管的资产存入这一多签账户并进行相应的多签交易,Gnosis Safe本身并不掌握任何私钥。目前,Gnosis Safe支持以太坊网络、币安智能链网络以及Polygon网络等12个网络的多签,支持币种包括ETH、ERC20标准代币以及ERC721标准代币等。
Gnosis Safe的优点是多签参与者不用再额外注册统一的多签钱包,使用现有的加密钱包就可以完成多签步骤;缺点是该智能合约直接部署在区块链上,每一次交互都是链上的一次交易,即创建钱包、多签过程中的每一次签名授权都要支付一笔Gas费用。每次支付的费用都会根据当时的网络情况、参与人数、交易复杂程度发生变化。
接下来我以 Gnosis Safe 钱包来演示一下多签钱包的使用流程,作为有多签钱包需求读者的入门教程,使用过多签的读者可以略过。
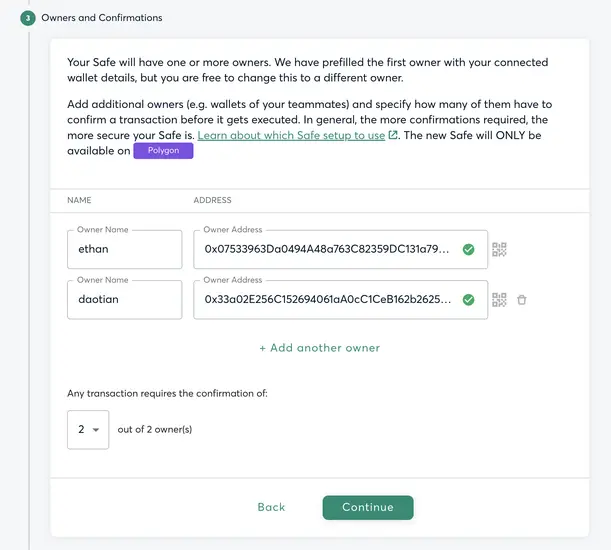
1. 创建多签钱包
创建多签钱包的过程很简单,输入钱包名称和参与签名的钱包地址即可,我在 Polygon 网络(以太坊侧链,Gas比较便宜)演示 2/2 签名模式,即多签钱包对应2个签名者,且两个签名者均同意才能转出资产。
对于新的用户需要额外说明的是,在我们创建普通钱包(或叫外部账户,以太坊的账户分为外部账户和合约账户)时,只是在钱包的客户端通过一定的加密算法在客户端本地生成的钱包地址(没有上链,只有产生了交易才会在链上有了关联),所以普通钱包是不需要支持Gas费的,而多签钱包本质上是一个部署在链上的智能合约,而部署合约就像发起转账一样会产生一笔交易,所以需要支出Gas费用来奖励旷工确认这笔交易。
创建多签合约时的交易:https://polygonscan.com/tx/0x78dee97d40ea5e45c4b2d08d878694d075be76bd34dfb01508afae9b9bf34f73
注意:从创建钱包,到付款和收款,均重点关注选择的网络(本示例为 Polygon 网络),一定注意!!

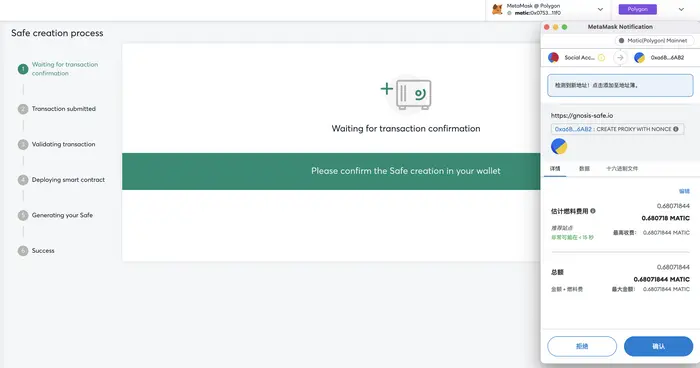
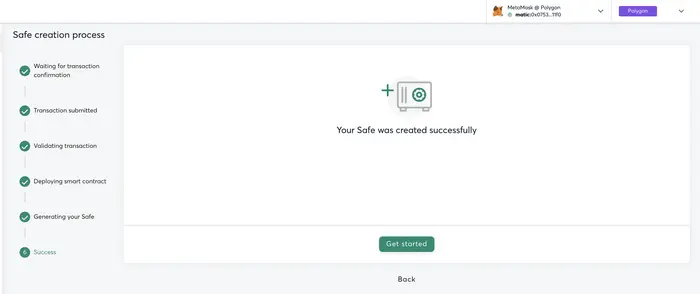
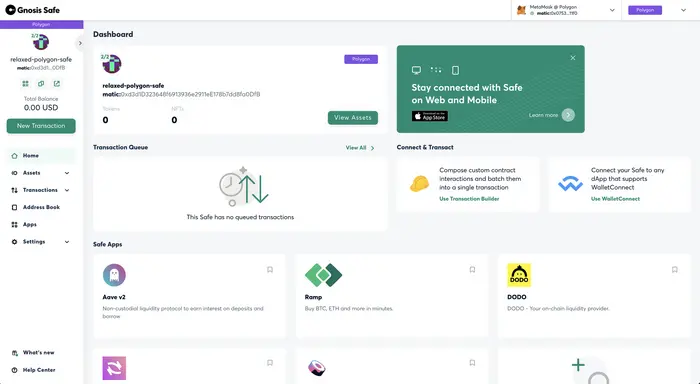
2. 通过多签钱包收款
这一步不做过多说明,多签钱包的合约和普通钱包一样具有收款的能力,只是在转出机制不同:
- 普通钱包地址是通过在钱包客户端本地对交易进行签名然后广播上链
- 合约地址是需要触发合约公开的方法通过合约执行交易行为
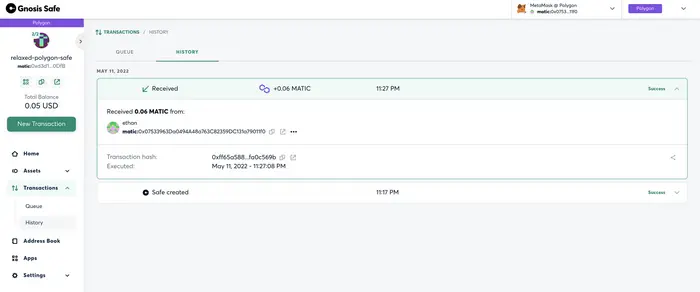
为了演示用多签钱包付款,这里先往里转入小额的 $MATIC:
https://polygonscan.com/tx/0xff65a58854d42610dc531b9a0f0efff22ca7e97def6e49f9eccd1011fa0c569b
3. 通过多签钱包付款
这是比较重要的步骤,感兴趣的读者可以结合上面的代码示例来理解
i. 任意签名人发起一笔转账申请
这一步对应到合约里的 submitTransaction 方法,发起一笔交易申请,但资产没有真正开始转移,需要其他的参与者进行确认这笔交易申请。
这一步的操作是 签名人A 在浏览器通过 MetaMask 钱包登录 Gnosis Safe,选择对应的网络,发起付款操作(填入转出的钱包地址和金额)
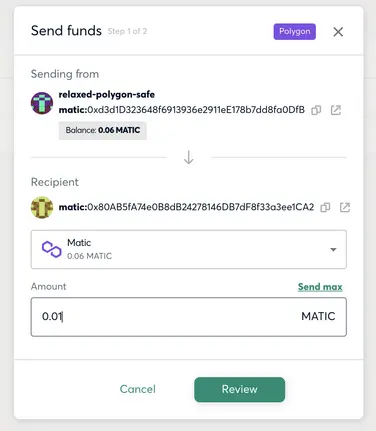
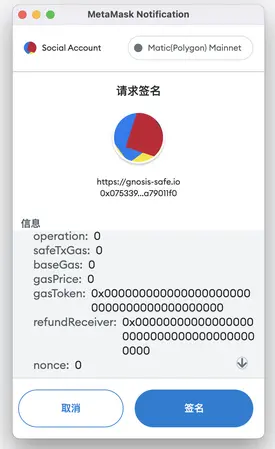
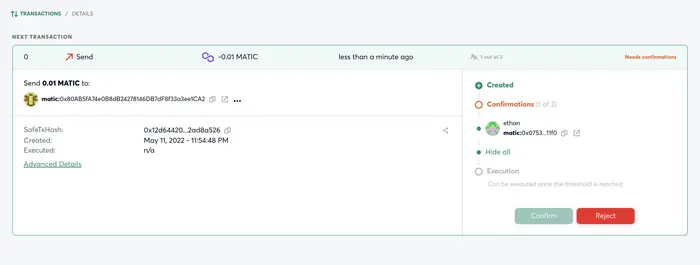
ii. 其他参与者对这笔转账申请进行确认
这一步会演示两个流程:参与确认、执行转账,对应到合约代码里的就是 confirmTransaction 和 executeTransaction 方法。
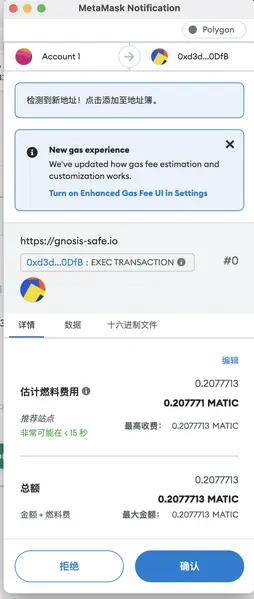
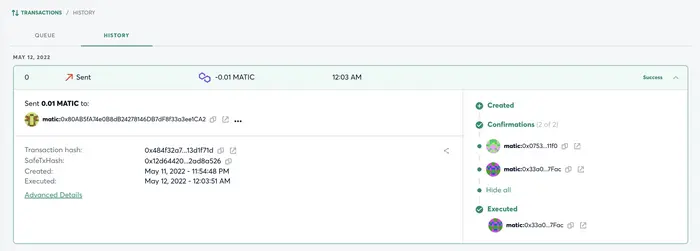
以这个 2/2 多签模式,上一步签名人A发起了一笔申请, 此时签名人B 在另外一个浏览器(模拟两个不同的参与人)同样通过 MetaMask 钱包登录 Gnosis Safe,会在交易中看到签名人A发起的待确认的交易,然后执行确认交易。此时因为已经两个人参与,达到了最少参与人的要求,所以参与人B在确认时就会触发真正的转账行为。
此时的确认操作即调用了合约发起转账(tx.destination.call.value(tx.value)(tx.data)),执行转账的方法(调用合约的写方法)会产生Gas的消耗,即最后的确认者需要支付本次交易的手续费(是不是有点冤)。
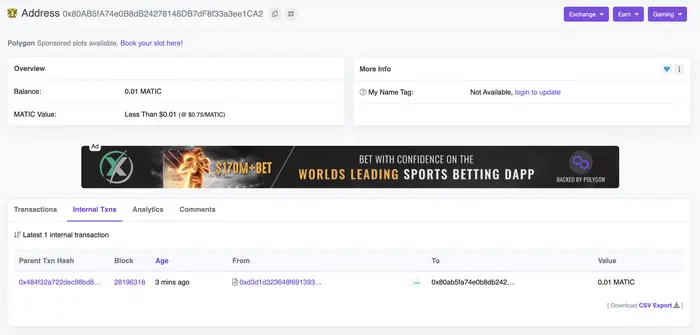
对应的链上交易:https://polygonscan.com/tx/0x484f32a722dec98bd8ca9ac508bc8c846a663a1ac5500fbbde38d53a13d1f71d

以上,就是多签钱包的介绍、使用场景、工作原理、操作流程的全部内容,感谢阅读。如果有问题交流,可以关注并私信我:微信(jingwentian)、Twitter(@0xDaotian)、微信公众号(北极之野)、Substack邮件订阅(文叔白话WEB3)。
转载:https://learnblockchain.cn/article/4077