前言
在Go语言中,可以使用关键字defer向函数注册退出调用,即主函数退出时,defer后的函数才被调用。defer语句的作用是不管程序是否出现异常,均在函数退出时自动执行相关代码。 所以,defer后面的函数通常又叫做延迟函数
defer规则
1.延迟函数的参数在defer语句出现时就已经确定下来了
func a() {
i := 0
defer fmt.Println(i)
i++
return
}返回结果:0
defer语句中打印的变量i在defer出现时就已经拷贝了一份过来,所以后面对变量i的值进行修改也不会影响defer语句的打印结果
注意:对于指针类型参数,规则仍然适用,只不过延迟函数的参数是一个地址值,在这种情况下,defer后面的语句对变量的修改可能会影响延迟函数
2.defer的执行顺序与声明顺序相反
简单理解就是:定义defer类似于入栈操作,执行defer类似于出栈操作,先进后出
3.defer可操作主函数返回值
defer语句中的函数会在return语句更新返回值后在执行。因为在函数中定义的匿名函数可以访问该函数包括返回值在内的所有变量。
func deferFuncReturn() (result int) {
i := 1
defer func() {
result++
}()
return i
}返回结果:2
所以上面函数实际返回i++值。
defer实现原理
注意:我会把源码中每个方法的作用都注释出来,可以参考注释进行理解。
数据结构
我们先来看下defer结构体src/src/runtime/runtime2.go:_defer
type _defer struct {
siz int32 //defer函数的参数大小
started bool
sp uintptr // sp at time of defer
pc uintptr //defer语句下一条语句的地址
fn *funcval //需要被延迟执行的函数
_panic *_panic //在执行 defer 的 panic 结构体
link *_defer //同一个goroutine所有被延迟执行的函数通过该成员链在一起形成一个链表
}我们知道,在每一个goroutine结构体中都有一个_defer 指针变量用来存放defer单链表。
如下图所示:
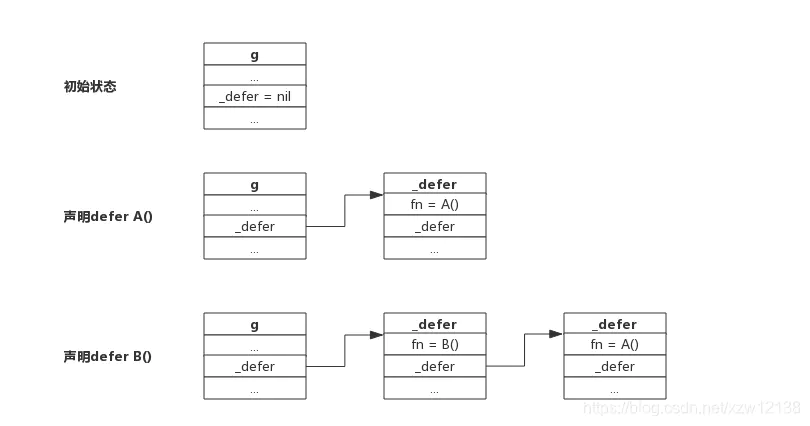
defer的创建与执行
我们先来看一下汇编是如何翻译defer关键字的
0x0082 00130 (test.go:16) CALL runtime.deferproc(SB)
0x0087 00135 (test.go:16) TESTL AX, AX
0x0089 00137 (test.go:16) JNE 155
0x008b 00139 (test.go:19) XCHGL AX, AX
0x008c 00140 (test.go:19) CALL runtime.deferreturn(SB)defer 被翻译两个过程,先执行 runtime.deferproc 生成 println 函数及其相关参数的描述结构体,然后将其挂载到当前 g 的 _defer 指针上。
我们先来看 deferproc 函数的实现
deferproc
// Create a new deferred function fn with siz bytes of arguments.
// The compiler turns a defer statement into a call to this.
//go:nosplit
func deferproc(siz int32, fn *funcval) { // arguments of fn follow fn
//用户goroutine才能使用defer
if getg().m.curg != getg() {
// go code on the system stack can't defer
throw("defer on system stack")
}
//也就是调用deferproc之前的rsp寄存器的值
sp := getcallersp()
// argp指向defer函数的第一个参数
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
// 存储的是 caller 中,call deferproc 的下一条指令的地址
// deferproc函数的返回地址
callerpc := getcallerpc()
//创建defer
d := newdefer(siz)
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
//需要延迟执行的函数
d.fn = fn
//记录deferproc函数的返回地址
d.pc = callerpc
//调用deferproc之前rsp寄存器的值
d.sp = sp
switch siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
//通过memmove拷贝defered函数的参数
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
// deferproc通常都会返回0
return0()
}比较关键的就是 newdefer
func newdefer(siz int32) *_defer {
var d *_defer
sc := deferclass(uintptr(siz))
//获取当前goroutine的g结构体对象
gp := getg()
if sc < uintptr(len(p{}.deferpool)) {
pp := gp.m.p.ptr()//与当前工作线程绑定的p
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {
// Take the slow path on the system stack so
// we don't grow newdefer's stack.
systemstack(func() {//切换到系统栈
lock(&sched.deferlock)
//从全局_defer对象池拿一些到p的本地_defer对象池
for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {
d := sched.deferpool[sc]
sched.deferpool[sc] = d.link
d.link = nil
pp.deferpool[sc] = append(pp.deferpool[sc], d)
}
unlock(&sched.deferlock)
})
}
if n := len(pp.deferpool[sc]); n > 0 {
d = pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
}
}
//如果p的缓存中没有可用的_defer结构体对象则从堆上分配
if d == nil {
// Allocate new defer+args.
//因为roundupsize以及mallocgc函数都不会处理扩栈,所以需要切换到系统栈执行
systemstack(func() {
total := roundupsize(totaldefersize(uintptr(siz)))
d = (*_defer)(mallocgc(total, deferType, true))
})
if debugCachedWork {
// Duplicate the tail below so if there's a
// crash in checkPut we can tell if d was just
// allocated or came from the pool.
d.siz = siz
//把新分配出来的d放入当前goroutine的_defer链表头
d.link = gp._defer
gp._defer = d
return d
}
}
d.siz = siz
d.link = gp._defer
//把新分配出来的d放入当前goroutine的_defer链表头
gp._defer = d
return d
}在函数deferproc中,
- 先获得调用
deferproc之前的rsp寄存器的值,后面进行deferreturn时会通过这个值去进行判断要执行的defer是否属于当前调用者 - 通过
newdefer函数分配一个_defer结构体对象并放入当前 goroutine 的_defer链表的表头 - 然后会将参数部分拷贝到紧挨着defer对象后面的地址:
deferArgs(d)=unsafe.Pointer(d)+unsafe.Sizeof(*d) - 执行
return0函数,正常情况下返回0,经过test %eax,%eax检测后继续执行业务逻辑。异常情况下会返回1,并且直接跳转到deferreturn
deferreturn
// 编译器会在调用过 defer 的函数的末尾插入对 deferreturn 的调用
// 如果有被 defer 的函数的话,这里会调用 runtime·jmpdefer 跳到对应的位置
// 实际效果是会一遍遍地调用 deferreturn 直到 _defer 链表被清空
// 这里不能进行栈分裂,因为我们要该函数的栈来调用 defer 函数
func deferreturn(arg0 uintptr) {
gp := getg()
// defer函数链表
// 也是第一个defer
d := gp._defer
if d == nil {
//由于是递归调用,
//递归终止
return
}
//获取调用deferreturn时的栈顶位置
sp := getcallersp()
// 判断当前栈顶位置是否和defer中保存的一致
if d.sp != sp {
//如果保存在_defer对象中的sp值与调用deferretuen时的栈顶位置不一样,直接返回
//因为sp不一样表示d代表的是在其他函数中通过defer注册的延迟调用函数,比如:
//a()->b()->c()它们都通过defer注册了延迟函数,那么当c()执行完时只能执行在c中注册的函数
return
}
//把保存在_defer对象中的fn函数需要用到的参数拷贝到栈上,准备调用fn
//注意fn的参数放在了调用调用者的栈帧中,而不是此函数的栈帧中
switch d.siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
fn := d.fn
d.fn = nil
// 指向 defer 链表下一个节点
gp._defer = d.link
// 进行释放,归还到相应的缓冲区或者让gc回收
freedefer(d)
//执行defer中的func
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}在函数deferreturn中
- 判断当前goroutine上是否还有绑定的defer,若没有,直接return。若有,则获取链表头部的defer
- 通过判断当前defer中存储的sp是否和调用者的sp一致,来证明当前defer不是在此调用函数中声明的。
- 将保存在_defer对象中的fn函数需要用到的参数拷贝到栈上,准备调用defer后的函数
- 释放defer
- 通过
jmpdefer函数执行defer后的func
总结
- 在编译在阶段,声明defer处插入了函数deferproc(),在函数return前插入了函数deferreturn()
- defer定义的延迟函数参数在defer语句出时就已经确定下来了
- defer定义顺序与实际执行顺序相反
- 对匿名函数采用defer机制,可以使其观察函数的返回值
转载自:https://www.jianshu.com/p/387ad32c6441
版权属于:区块链中文技术社区 / 转载原创者
本文链接:https://www.bcskill.com/index.php/archives/1272.html
相关技术文章仅限于相关区块链底层技术研究,禁止用于非法用途,后果自负!本站严格遵守一切相关法律政策!