以太坊源码分析:fetcher模块和区块传播
前言
这篇文章从区块传播策略入手,介绍新区块是如何传播到远端节点,以及新区块加入到远端节点本地链的过程,同时会介绍fetcher模块,fetcher的功能是处理Peer通知的区块信息。在介绍过程中,还会涉及到p2p,eth等模块,不会专门介绍,而是专注区块的传播和加入区块链的过程。
当前代码是以太坊Release 1.8,如果版本不同,代码上可能存在差异。
总体过程和传播策略
本节从宏观角度介绍,节点产生区块后,为了传播给远端节点做了啥,远端节点收到区块后又做了什么,每个节点都连接了很多Peer,它传播的策略是什么样的?
总体流程和策略可以总结为,传播给远端Peer节点,Peer验证区块无误后,加入到本地区块链,继续传播新区块信息。具体过程如下。
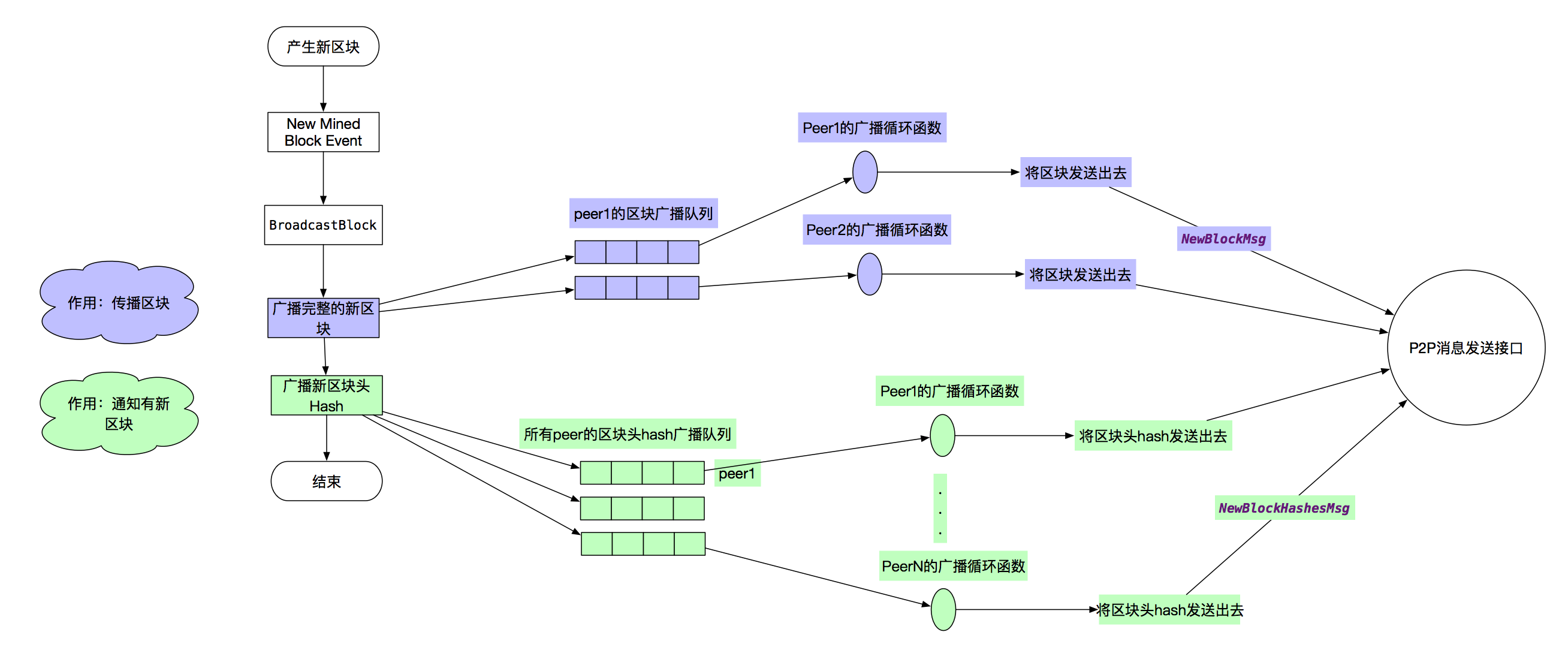
先看总体过程。产生区块后,miner模块会发布一个事件NewMinedBlockEvent,订阅事件的协程收到事件后,就会把新区块的消息,广播给它所有的peer,peer收到消息后,会交给自己的fetcher模块处理,fetcher进行基本的验证后,区块没问题,发现这个区块就是本地链需要的下一个区块,则交给blockChain进一步进行完整的验证,这个过程会执行区块所有的交易,无误后把区块加入到本地链,写入数据库,这个过程就是下面的流程图,图1。
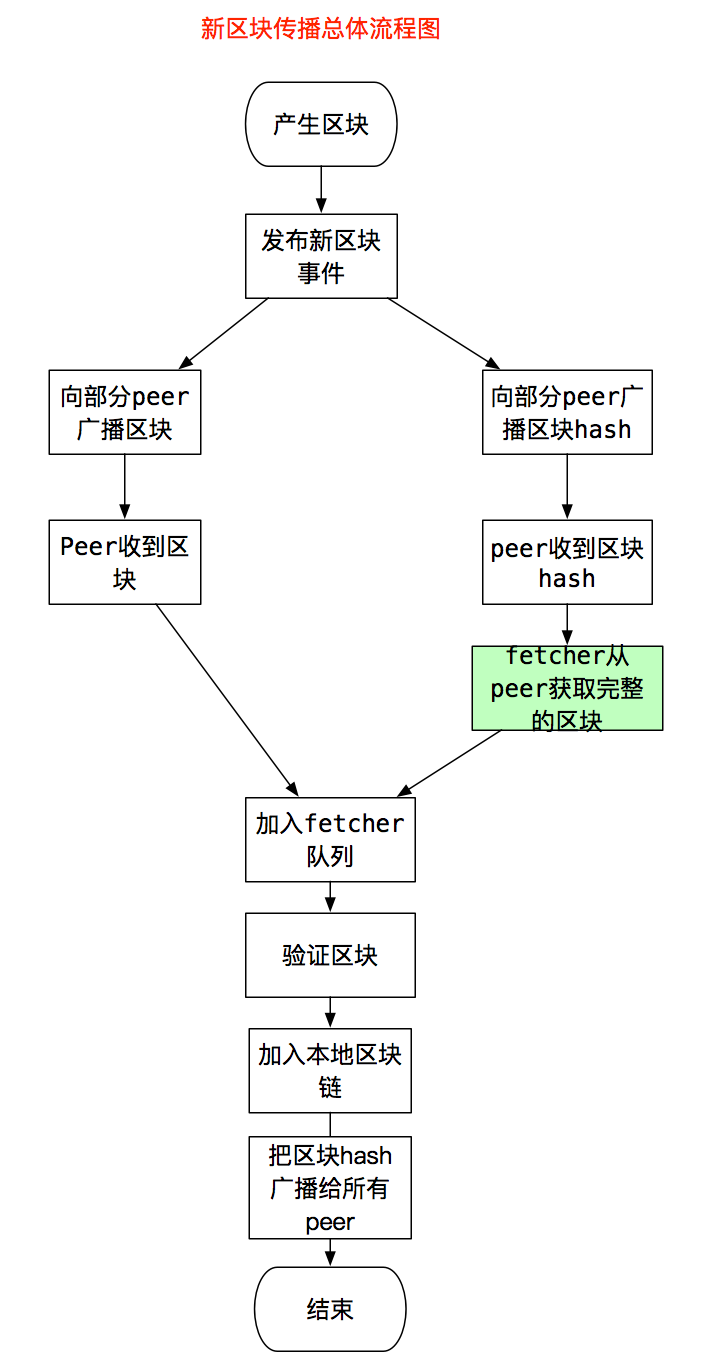
总体流程图,能看到有个分叉,是因为节点传播新区块是有策略的。它的传播策略为:
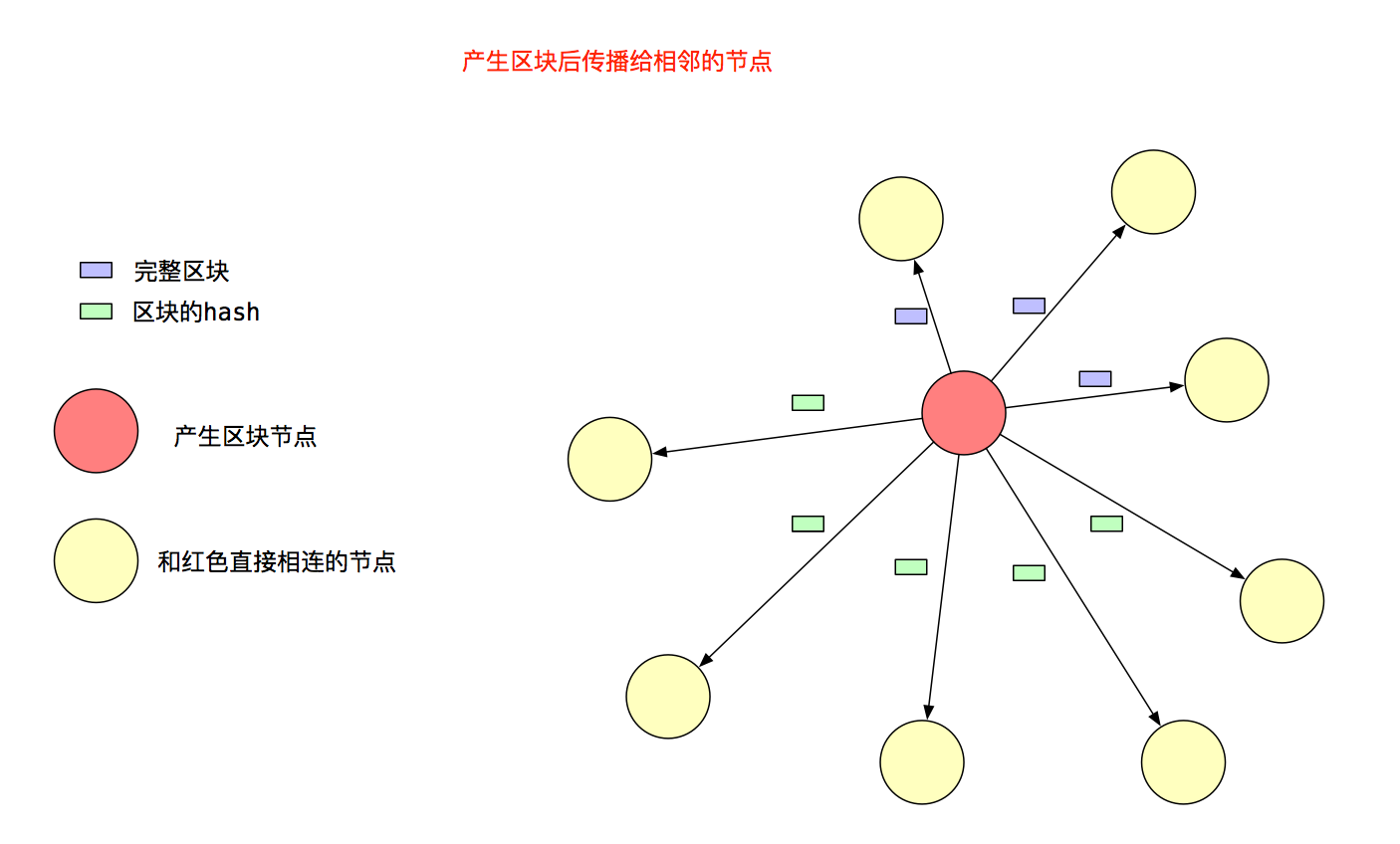
- 假如节点连接了N个Peer,它只向Peer列表的sqrt(N)个Peer广播完整的区块消息。
- 向所有的Peer广播只包含区块Hash的消息。
策略图的效果如图2,红色节点将区块传播给黄色节点:
收到区块Hash的节点,需要从发送给它消息的Peer那里获取对应的完整区块,获取区块后就会按照图1的流程,加入到fetcher队列,最终插入本地区块链后,将区块的Hash值广播给和它相连,但还不知道这个区块的Peer。非产生区块节点的策略图,如图3,黄色节点将区块Hash传播给青色节点:
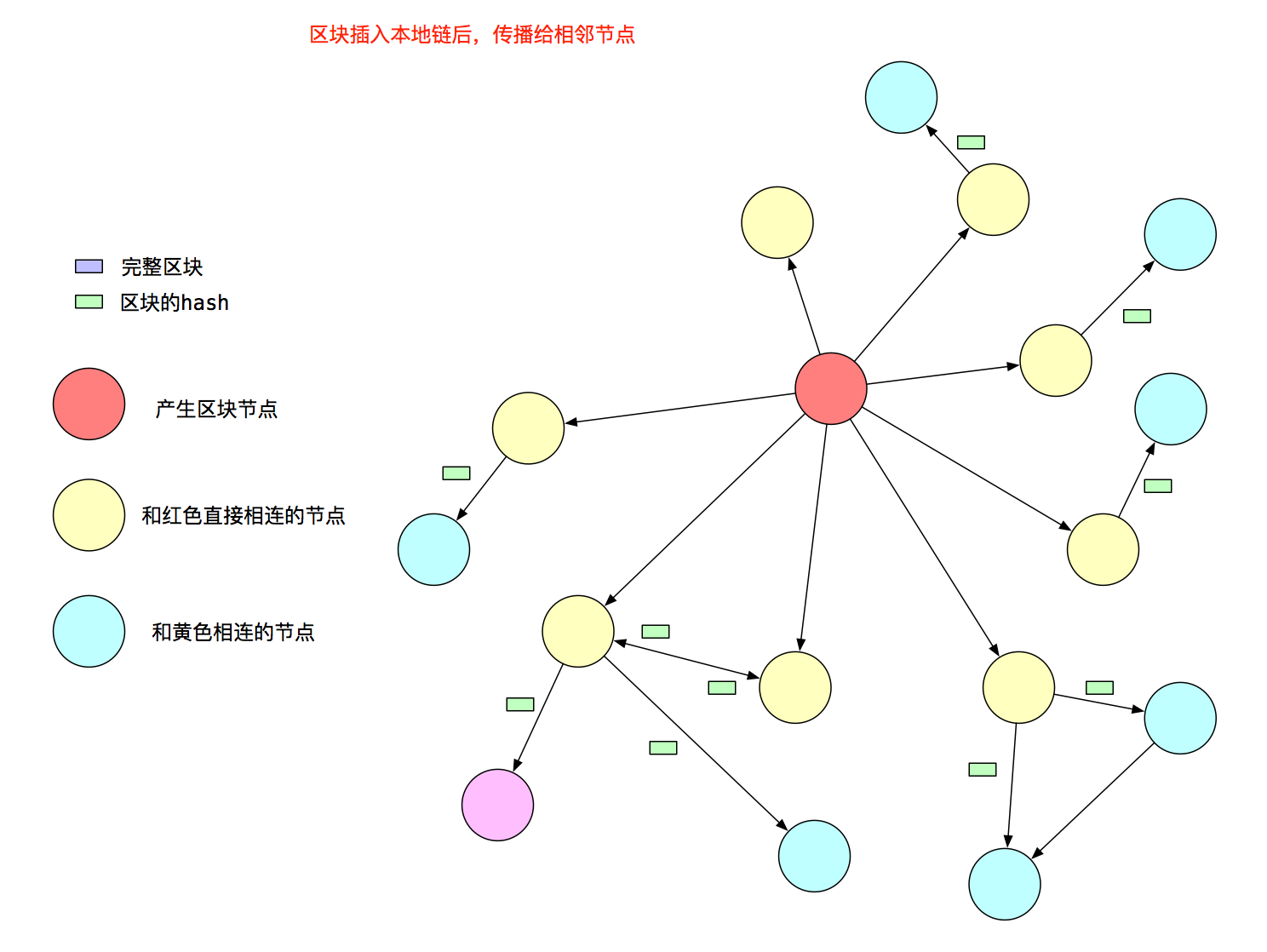
至此,可以看出以太坊采用以石击水的方式,像水纹一样,层层扩散新产生的区块。
Fetcher模块是干啥的
fetcher模块的功能,就是收集其他Peer通知它的区块信息:1)完整的区块2)区块Hash消息。根据通知的消息,获取完整的区块,然后传递给eth模块把区块插入区块链。
如果是完整区块,就可以传递给eth插入区块,如果只有区块Hash,则需要从其他的Peer获取此完整的区块,然后再传递给eth插入区块。
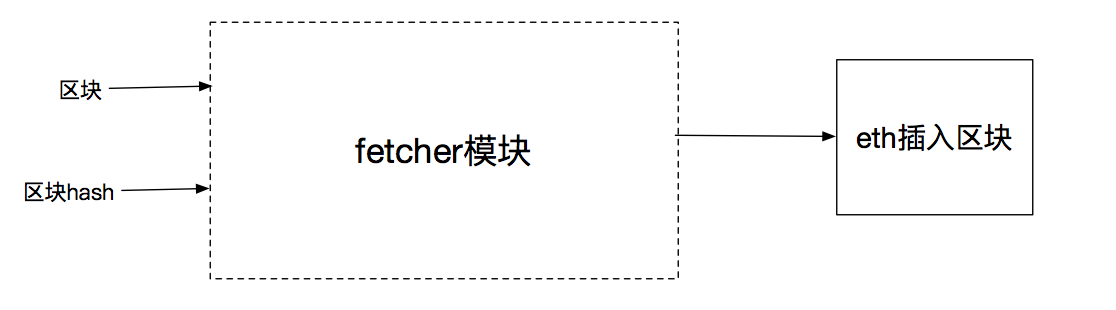
源码解读
本节介绍区块传播和处理的细节东西,方式仍然是先用图解释流程,再是代码流程。
产块节点的传播新区块
节点产生区块后,广播的流程可以表示为图4:
- 发布事件
- 事件处理函数选择要广播完整的Peer,然后将区块加入到它们的队列
- 事件处理函数把区块Hash添加到所有Peer的另外一个通知队列
- 每个Peer的广播处理函数,会遍历它的待广播区块队列和通知队列,把数据封装成消息,调用P2P接口发送出去
再看下代码上的细节。
-
worker.wait()函数发布事件NewMinedBlockEvent。
-
ProtocolManager.minedBroadcastLoop()是事件处理函数。它调用了2次pm.BroadcastBlock()。
// Mined broadcast loop func (pm *ProtocolManager) minedBroadcastLoop() { // automatically stops if unsubscribe for obj := range pm.minedBlockSub.Chan() { switch ev := obj.Data.(type) { case core.NewMinedBlockEvent: pm.BroadcastBlock(ev.Block, true) // First propagate block to peers pm.BroadcastBlock(ev.Block, false) // Only then announce to the rest } } } -
pm.BroadcastBlock()的入参propagate为真时,向部分Peer广播完整的区块,调用peer.AsyncSendNewBlock(),否则向所有Peer广播区块头,调用peer.AsyncSendNewBlockHash(),这2个函数就是把数据放入队列,此处不再放代码。
// BroadcastBlock will either propagate a block to a subset of it's peers, or // will only announce it's availability (depending what's requested). func (pm *ProtocolManager) BroadcastBlock(block *types.Block, propagate bool) { hash := block.Hash() peers := pm.peers.PeersWithoutBlock(hash) // If propagation is requested, send to a subset of the peer // 这种情况,要把区块广播给部分peer if propagate { // Calculate the TD of the block (it's not imported yet, so block.Td is not valid) // 计算新的总难度 var td *big.Int if parent := pm.blockchain.GetBlock(block.ParentHash(), block.NumberU64()-1); parent != nil { td = new(big.Int).Add(block.Difficulty(), pm.blockchain.GetTd(block.ParentHash(), block.NumberU64()-1)) } else { log.Error("Propagating dangling block", "number", block.Number(), "hash", hash) return } // Send the block to a subset of our peers // 广播区块给部分peer transfer := peers[:int(math.Sqrt(float64(len(peers))))] for _, peer := range transfer { peer.AsyncSendNewBlock(block, td) } log.Trace("Propagated block", "hash", hash, "recipients", len(transfer), "duration", common.PrettyDuration(time.Since(block.ReceivedAt))) return } // Otherwise if the block is indeed in out own chain, announce it // 把区块hash值广播给所有peer if pm.blockchain.HasBlock(hash, block.NumberU64()) { for _, peer := range peers { peer.AsyncSendNewBlockHash(block) } log.Trace("Announced block", "hash", hash, "recipients", len(peers), "duration", common.PrettyDuration(time.Since(block.ReceivedAt))) } } -
peer.broadcase()是每个Peer连接的广播函数,它只广播3种消息:交易、完整的区块、区块的Hash,这样表明了节点只会主动广播这3中类型的数据,剩余的数据同步,都是通过请求-响应的方式。
// broadcast is a write loop that multiplexes block propagations, announcements // and transaction broadcasts into the remote peer. The goal is to have an async // writer that does not lock up node internals. func (p *peer) broadcast() { for { select { // 广播交易 case txs := <-p.queuedTxs: if err := p.SendTransactions(txs); err != nil { return } p.Log().Trace("Broadcast transactions", "count", len(txs)) // 广播完整的新区块 case prop := <-p.queuedProps: if err := p.SendNewBlock(prop.block, prop.td); err != nil { return } p.Log().Trace("Propagated block", "number", prop.block.Number(), "hash", prop.block.Hash(), "td", prop.td) // 广播区块Hash case block := <-p.queuedAnns: if err := p.SendNewBlockHashes([]common.Hash{block.Hash()}, []uint64{block.NumberU64()}); err != nil { return } p.Log().Trace("Announced block", "number", block.Number(), "hash", block.Hash()) case <-p.term: return } } }Peer节点处理新区块
本节介绍远端节点收到2种区块同步消息的处理,其中NewBlockMsg的处理流程比较清晰,也简洁。NewBlockHashesMsg消息的处理就绕了2绕,从总体流程图1上能看出来,它需要先从给他发送消息Peer那里获取到完整的区块,剩下的流程和NewBlockMsg又一致了。
这部分涉及的模块多,画出来有种眼花缭乱的感觉,但只要抓住上面的主线,代码看起来还是很清晰的。通过图5先看下整体流程。
消息处理的起点是ProtocolManager.handleMsg,NewBlockMsg的处理流程是蓝色标记的区域,红色区域是单独的协程,是fetcher处理队列中区块的流程,如果从队列中取出的区块是当前链需要的,校验后,调用blockchian.InsertChain()把区块插入到区块链,最后写入数据库,这是黄色部分。最后,绿色部分是NewBlockHashesMsg的处理流程,代码流程上是比较复杂的,为了能通过图描述整体流程,我把它简化掉了。
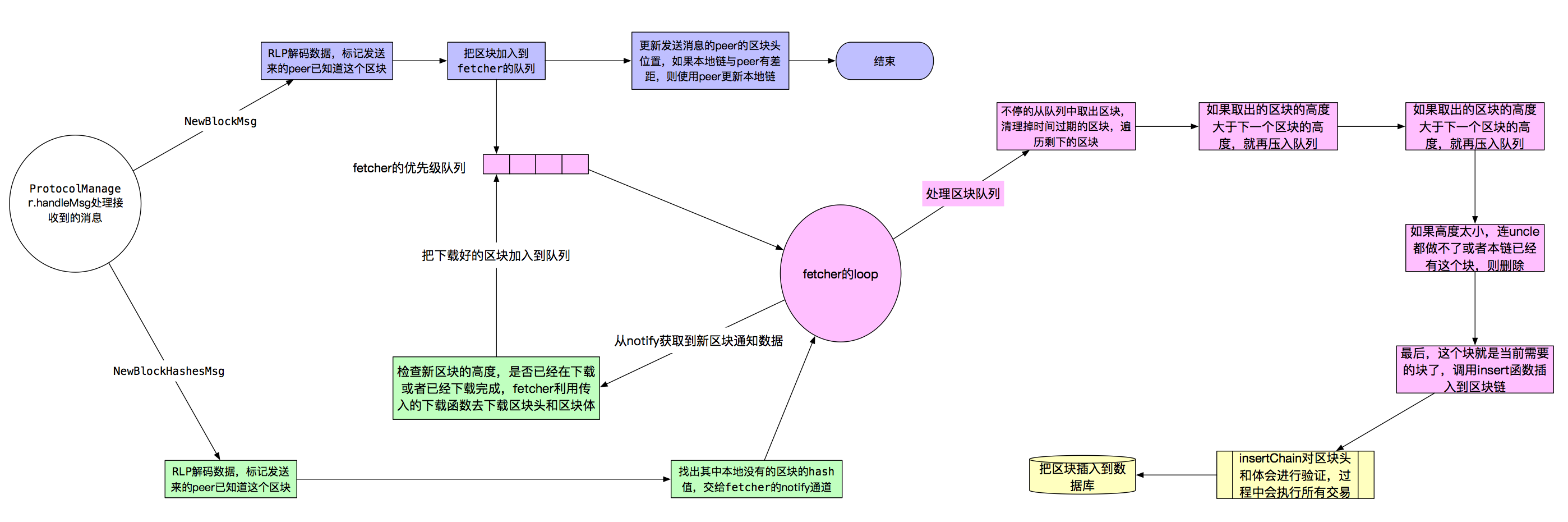
仔细看看这幅图,掌握整体的流程后,接下来看每个步骤的细节。
NewBlockMsg的处理
本节介绍节点收到完整区块的处理,流程如下:
- 首先进行RLP编解码,然后标记发送消息的Peer已经知道这个区块,这样本节点最后广播这个区块的Hash时,不会再发送给该Peer。
- 将区块存入到fetcher的队列,调用fetcher.Enqueue。
- 更新Peer的Head位置,然后判断本地链是否落后于Peer的链,如果是,则通过Peer更新本地链。
只看handle.Msg()的NewBlockMsg相关的部分。
case msg.Code == NewBlockMsg:
// Retrieve and decode the propagated block
// 收到新区块,解码,赋值接收数据
var request newBlockData
if err := msg.Decode(&request); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
request.Block.ReceivedAt = msg.ReceivedAt
request.Block.ReceivedFrom = p
// Mark the peer as owning the block and schedule it for import
// 标记peer知道这个区块
p.MarkBlock(request.Block.Hash())
// 为啥要如队列?已经得到完整的区块了
// 答:存入fetcher的优先级队列,fetcher会从队列中选取当前高度需要的块
pm.fetcher.Enqueue(p.id, request.Block)
// Assuming the block is importable by the peer, but possibly not yet done so,
// calculate the head hash and TD that the peer truly must have.
// 截止到parent区块的头和难度
var (
trueHead = request.Block.ParentHash()
trueTD = new(big.Int).Sub(request.TD, request.Block.Difficulty())
)
// Update the peers total difficulty if better than the previous
// 如果收到的块的难度大于peer之前的,以及自己本地的,就去和这个peer同步
// 问题:就只用了一下块里的hash值,为啥不直接使用这个块呢,如果这个块不能用,干嘛不少发送些数据,减少网络负载呢。
// 答案:实际上,这个块加入到了优先级队列中,当fetcher的loop检查到当前下一个区块的高度,正是队列中有的,则不再向peer请求
// 该区块,而是直接使用该区块,检查无误后交给block chain执行insertChain
if _, td := p.Head(); trueTD.Cmp(td) > 0 {
p.SetHead(trueHead, trueTD)
// Schedule a sync if above ours. Note, this will not fire a sync for a gap of
// a singe block (as the true TD is below the propagated block), however this
// scenario should easily be covered by the fetcher.
currentBlock := pm.blockchain.CurrentBlock()
if trueTD.Cmp(pm.blockchain.GetTd(currentBlock.Hash(), currentBlock.NumberU64())) > 0 {
go pm.synchronise(p)
}
}
//------------------------ 以上 handleMsg
// Enqueue tries to fill gaps the the fetcher's future import queue.
// 发给inject通道,当前协程在handleMsg,通过通道发送给fetcher的协程处理
func (f *Fetcher) Enqueue(peer string, block *types.Block) error {
op := &inject{
origin: peer,
block: block,
}
select {
case f.inject <- op:
return nil
case <-f.quit:
return errTerminated
}
}
//------------------------ 以下 fetcher.loop处理inject部分
case op := <-f.inject:
// A direct block insertion was requested, try and fill any pending gaps
// 区块加入队列,首先也填入未决的间距
propBroadcastInMeter.Mark(1)
f.enqueue(op.origin, op.block)
//------------------------ 如队列函数
// enqueue schedules a new future import operation, if the block to be imported
// has not yet been seen.
// 把导入的新区块加入到队列,主要操作queue, queues, queued这3个变量,quque用来保存要插入的区块,
// 按高度排序,queues记录了在队列中某个peer传来的区块的数量,用来做对抗DoS攻击,queued用来
// 判断某个区块是否已经在队列,防止2次插入,浪费时间
func (f *Fetcher) enqueue(peer string, block *types.Block) {
hash := block.Hash()
// Ensure the peer isn't DOSing us
// 防止peer的DOS攻击
count := f.queues[peer] + 1
if count > blockLimit {
log.Debug("Discarded propagated block, exceeded allowance", "peer", peer, "number", block.Number(), "hash", hash, "limit", blockLimit)
propBroadcastDOSMeter.Mark(1)
f.forgetHash(hash)
return
}
// Discard any past or too distant blocks
// 高度检查:未来太远的块丢弃
if dist := int64(block.NumberU64()) - int64(f.chainHeight()); dist < -maxUncleDist || dist > maxQueueDist {
log.Debug("Discarded propagated block, too far away", "peer", peer, "number", block.Number(), "hash", hash, "distance", dist)
propBroadcastDropMeter.Mark(1)
f.forgetHash(hash)
return
}
// Schedule the block for future importing
// 块先加入优先级队列,加入链之前,还有很多要做
if _, ok := f.queued[hash]; !ok {
op := &inject{
origin: peer,
block: block,
}
f.queues[peer] = count
f.queued[hash] = op
f.queue.Push(op, -float32(block.NumberU64()))
if f.queueChangeHook != nil {
f.queueChangeHook(op.block.Hash(), true)
}
log.Debug("Queued propagated block", "peer", peer, "number", block.Number(), "hash", hash, "queued", f.queue.Size())
}
}fetcher队列处理
本节我们看看,区块加入队列后,fetcher如何处理区块,为何不直接校验区块,插入到本地链?
由于以太坊又Uncle的机制,节点可能收到老一点的一些区块。另外,节点可能由于网络原因,落后了几个区块,所以可能收到“未来”的一些区块,这些区块都不能直接插入到本地链。
区块入的队列是一个优先级队列,高度低的区块会被优先取出来。fetcher.loop是单独协程,不断运转,清理fecther中的事务和事件。首先会清理正在fetching的区块,但已经超时。然后处理优先级队列中的区块,判断高度是否是下一个区块,如果是则调用f.insert()函数,校验后调用BlockChain.InsertChain(),成功插入后,广播新区块的Hash。
// Loop is the main fetcher loop, checking and processing various notification
// events.
func (f *Fetcher) loop() {
// Iterate the block fetching until a quit is requested
fetchTimer := time.NewTimer(0)
completeTimer := time.NewTimer(0)
for {
// Clean up any expired block fetches
// 清理过期的区块
for hash, announce := range f.fetching {
if time.Since(announce.time) > fetchTimeout {
f.forgetHash(hash)
}
}
// Import any queued blocks that could potentially fit
// 导入队列中合适的块
height := f.chainHeight()
for !f.queue.Empty() {
op := f.queue.PopItem().(*inject)
hash := op.block.Hash()
if f.queueChangeHook != nil {
f.queueChangeHook(hash, false)
}
// If too high up the chain or phase, continue later
// 块不是链需要的下一个块,再入优先级队列,停止循环
number := op.block.NumberU64()
if number > height+1 {
f.queue.Push(op, -float32(number))
if f.queueChangeHook != nil {
f.queueChangeHook(hash, true)
}
break
}
// Otherwise if fresh and still unknown, try and import
// 高度正好是我们想要的,并且链上也没有这个块
if number+maxUncleDist < height || f.getBlock(hash) != nil {
f.forgetBlock(hash)
continue
}
// 那么,块插入链
f.insert(op.origin, op.block)
}
//省略
}
}func (f *Fetcher) insert(peer string, block *types.Block) {
hash := block.Hash()
// Run the import on a new thread
log.Debug("Importing propagated block", "peer", peer, "number", block.Number(), "hash", hash)
go func() {
defer func() { f.done <- hash }()
// If the parent's unknown, abort insertion
parent := f.getBlock(block.ParentHash())
if parent == nil {
log.Debug("Unknown parent of propagated block", "peer", peer, "number", block.Number(), "hash", hash, "parent", block.ParentHash())
return
}
// Quickly validate the header and propagate the block if it passes
// 验证区块头,成功后广播区块
switch err := f.verifyHeader(block.Header()); err {
case nil:
// All ok, quickly propagate to our peers
propBroadcastOutTimer.UpdateSince(block.ReceivedAt)
go f.broadcastBlock(block, true)
case consensus.ErrFutureBlock:
// Weird future block, don't fail, but neither propagate
default:
// Something went very wrong, drop the peer
log.Debug("Propagated block verification failed", "peer", peer, "number", block.Number(), "hash", hash, "err", err)
f.dropPeer(peer)
return
}
// Run the actual import and log any issues
// 调用回调函数,实际是blockChain.insertChain
if _, err := f.insertChain(types.Blocks{block}); err != nil {
log.Debug("Propagated block import failed", "peer", peer, "number", block.Number(), "hash", hash, "err", err)
return
}
// If import succeeded, broadcast the block
propAnnounceOutTimer.UpdateSince(block.ReceivedAt)
go f.broadcastBlock(block, false)
// Invoke the testing hook if needed
if f.importedHook != nil {
f.importedHook(block)
}
}()
}NewBlockHashesMsg的处理
本节介绍NewBlockHashesMsg的处理,其实,消息处理是简单的,而复杂一点的是从Peer哪获取完整的区块,下节再看。
流程如下:
- 对消息进行RLP解码,然后标记Peer已经知道此区块。
- 寻找出本地区块链不存在的区块Hash值,把这些未知的Hash通知给fetcher。
- fetcher.Notify记录好通知信息,塞入notify通道,以便交给fetcher的协程。
- fetcher.loop()会对notify中的消息进行处理,确认区块并非DOS攻击,然后检查区块的高度,判断该区块是否已经在fetching或者comleting(代表已经下载区块头,在下载body),如果都没有,则加入到announced中,触发0s定时器,进行处理。
关于announced下节再介绍。
// handleMsg()部分
case msg.Code == NewBlockHashesMsg:
var announces newBlockHashesData
if err := msg.Decode(&announces); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
// Mark the hashes as present at the remote node
for _, block := range announces {
p.MarkBlock(block.Hash)
}
// Schedule all the unknown hashes for retrieval
// 把本地链没有的块hash找出来,交给fetcher去下载
unknown := make(newBlockHashesData, 0, len(announces))
for _, block := range announces {
if !pm.blockchain.HasBlock(block.Hash, block.Number) {
unknown = append(unknown, block)
}
}
for _, block := range unknown {
pm.fetcher.Notify(p.id, block.Hash, block.Number, time.Now(), p.RequestOneHeader, p.RequestBodies)
}// Notify announces the fetcher of the potential availability of a new block in
// the network.
// 通知fetcher(自己)有新块产生,没有块实体,有hash、高度等信息
func (f *Fetcher) Notify(peer string, hash common.Hash, number uint64, time time.Time,
headerFetcher headerRequesterFn, bodyFetcher bodyRequesterFn) error {
block := &announce{
hash: hash,
number: number,
time: time,
origin: peer,
fetchHeader: headerFetcher,
fetchBodies: bodyFetcher,
}
select {
case f.notify <- block:
return nil
case <-f.quit:
return errTerminated
}
}// fetcher.loop()的notify通道消息处理
case notification := <-f.notify:
// A block was announced, make sure the peer isn't DOSing us
propAnnounceInMeter.Mark(1)
count := f.announces[notification.origin] + 1
if count > hashLimit {
log.Debug("Peer exceeded outstanding announces", "peer", notification.origin, "limit", hashLimit)
propAnnounceDOSMeter.Mark(1)
break
}
// If we have a valid block number, check that it's potentially useful
// 高度检查
if notification.number > 0 {
if dist := int64(notification.number) - int64(f.chainHeight()); dist < -maxUncleDist || dist > maxQueueDist {
log.Debug("Peer discarded announcement", "peer", notification.origin, "number", notification.number, "hash", notification.hash, "distance", dist)
propAnnounceDropMeter.Mark(1)
break
}
}
// All is well, schedule the announce if block's not yet downloading
// 检查是否已经在下载,已下载则忽略
if _, ok := f.fetching[notification.hash]; ok {
break
}
if _, ok := f.completing[notification.hash]; ok {
break
}
// 更新peer已经通知给我们的区块数量
f.announces[notification.origin] = count
// 把通知信息加入到announced,供调度
f.announced[notification.hash] = append(f.announced[notification.hash], notification)
if f.announceChangeHook != nil && len(f.announced[notification.hash]) == 1 {
f.announceChangeHook(notification.hash, true)
}
if len(f.announced) == 1 {
// 有通知放入到announced,则重设0s定时器,loop的另外一个分支会处理这些通知
f.rescheduleFetch(fetchTimer)
}fetcher获取完整区块
本节介绍fetcher获取完整区块的过程,这也是fetcher最重要的功能,会涉及到fetcher至少80%的代码。单独拉放一大节吧。
Fetcher的大头
Fetcher最主要的功能就是获取完整的区块,然后在合适的实际交给InsertChain去验证和插入到本地区块链。我们还是从宏观入手,看Fetcher是如何工作的,一定要先掌握好宏观,因为代码层面上没有这么清晰。
宏观
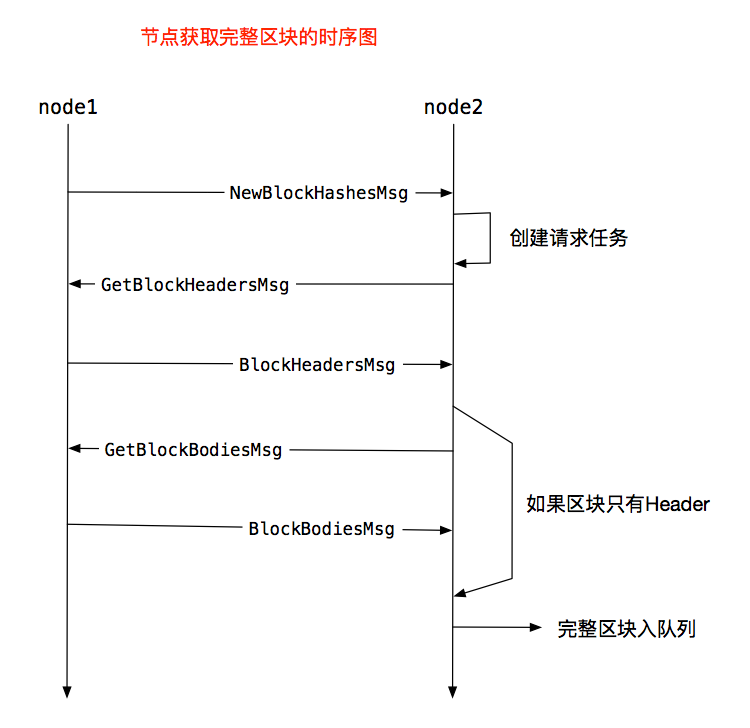
首先,看两个节点是如何交互,获取完整区块,使用时序图的方式看一下,见图6,流程很清晰不再文字介绍。
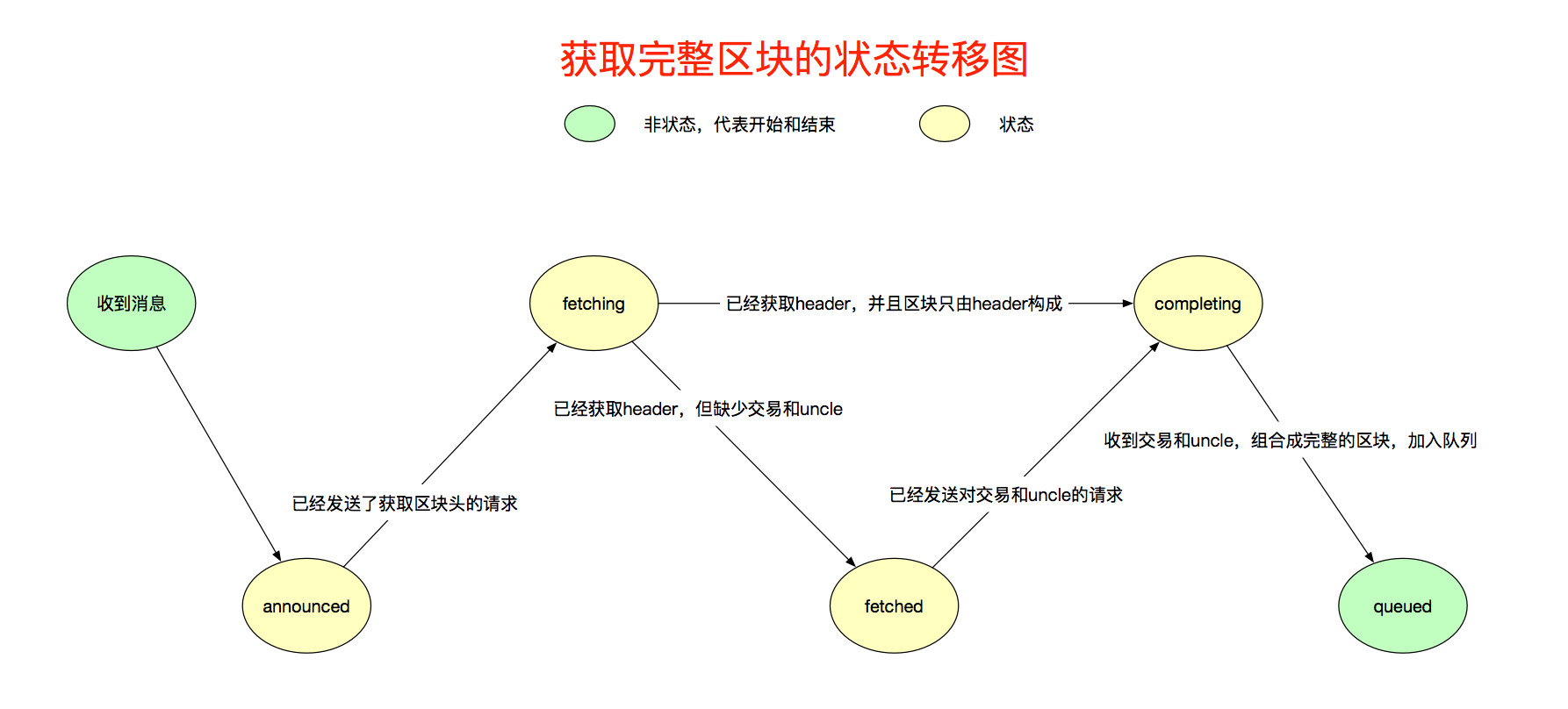
再看下获取区块过程中,fetcher内部的状态转移,它使用状态来记录,要获取的区块在什么阶段,见图7。我稍微解释一下:
- 收到NewBlockHashesMsg后,相关信息会记录到announced,进入announced状态,代表了本节点接收了消息。
- announced由fetcher协程处理,经过校验后,会向给他发送消息的Peer发送请求,请求该区块的区块头,然后进入fetching状态。
- 获取区块头后,如果区块头表示没有交易和uncle,则转移到completing状态,并且使用区块头合成完整的区块,加入到queued优先级队列。
- 获取区块头后,如果区块头表示该区块有交易和uncle,则转移到fetched状态,然后发送请求,请求交易和uncle,然后转移到completing状态。
- 收到交易和uncle后,使用头、交易、uncle这3个信息,生成完整的区块,加入到队列queued。
微观
接下来就是从代码角度看如何获取完整区块的流程了,有点多,看不懂的时候,再回顾下上面宏观的介绍图。
首先看Fetcher的定义,它存放了通信数据和状态管理,捡加注释的看,上文提到的状态,里面都有。
// Fetcher is responsible for accumulating block announcements from various peers
// and scheduling them for retrieval.
// 积累块通知,然后调度获取这些块
type Fetcher struct {
// Various event channels
// 收到区块hash值的通道
notify chan *announce
// 收到完整区块的通道
inject chan *inject
blockFilter chan chan []*types.Block
// 过滤header的通道的通道
headerFilter chan chan *headerFilterTask
// 过滤body的通道的通道
bodyFilter chan chan *bodyFilterTask
done chan common.Hash
quit chan struct{}
// Announce states
// Peer已经给了本节点多少区块头通知
announces map[string]int // Per peer announce counts to prevent memory exhaustion
// 已经announced的区块列表
announced map[common.Hash][]*announce // Announced blocks, scheduled for fetching
// 正在fetching区块头的请求
fetching map[common.Hash]*announce // Announced blocks, currently fetching
// 已经fetch到区块头,还差body的请求,用来获取body
fetched map[common.Hash][]*announce // Blocks with headers fetched, scheduled for body retrieval
// 已经得到区块头的
completing map[common.Hash]*announce // Blocks with headers, currently body-completing
// Block cache
// queue,优先级队列,高度做优先级
// queues,queued队列中某个peer发来的区块数量
// queued,等待插入到区块链的区块,实际插入时从queue取,queued就是用来快速判断区块是否在队列的
queue *prque.Prque // Queue containing the import operations (block number sorted)
queues map[string]int // Per peer block counts to prevent memory exhaustion
queued map[common.Hash]*inject // Set of already queued blocks (to dedupe imports)
// Callbacks
getBlock blockRetrievalFn // Retrieves a block from the local chain
verifyHeader headerVerifierFn // Checks if a block's headers have a valid proof of work,验证区块头,包含了PoW验证
broadcastBlock blockBroadcasterFn // Broadcasts a block to connected peers,广播给peer
chainHeight chainHeightFn // Retrieves the current chain's height
insertChain chainInsertFn // Injects a batch of blocks into the chain,插入区块到链的函数
dropPeer peerDropFn // Drops a peer for misbehaving
// Testing hooks
announceChangeHook func(common.Hash, bool) // Method to call upon adding or deleting a hash from the announce list
queueChangeHook func(common.Hash, bool) // Method to call upon adding or deleting a block from the import queue
fetchingHook func([]common.Hash) // Method to call upon starting a block (eth/61) or header (eth/62) fetch
completingHook func([]common.Hash) // Method to call upon starting a block body fetch (eth/62)
importedHook func(*types.Block) // Method to call upon successful block import (both eth/61 and eth/62)
}NewBlockHashesMsg消息的处理前面的小节已经讲过了,不记得可向前翻看。这里从announced的状态处理说起。loop()中,fetchTimer超时后,代表了收到了消息通知,需要处理,会从announced中选择出需要处理的通知,然后创建请求,请求区块头,由于可能有很多节点都通知了它某个区块的Hash,所以随机的从这些发送消息的Peer中选择一个Peer,发送请求的时候,为每个Peer都创建了单独的协程。
case <-fetchTimer.C:
// At least one block's timer ran out, check for needing retrieval
// 有区块通知,去处理
request := make(map[string][]common.Hash)
for hash, announces := range f.announced {
if time.Since(announces[0].time) > arriveTimeout-gatherSlack {
// Pick a random peer to retrieve from, reset all others
// 可能有很多peer都发送了这个区块的hash值,随机选择一个peer
announce := announces[rand.Intn(len(announces))]
f.forgetHash(hash)
// If the block still didn't arrive, queue for fetching
// 本地还没有这个区块,创建获取区块的请求
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
f.fetching[hash] = announce
}
}
}
// Send out all block header requests
// 把所有的request发送出去
// 为每一个peer都创建一个协程,然后请求所有需要从该peer获取的请求
for peer, hashes := range request {
log.Trace("Fetching scheduled headers", "peer", peer, "list", hashes)
// Create a closure of the fetch and schedule in on a new thread
fetchHeader, hashes := f.fetching[hashes[0]].fetchHeader, hashes
go func() {
if f.fetchingHook != nil {
f.fetchingHook(hashes)
}
for _, hash := range hashes {
headerFetchMeter.Mark(1)
fetchHeader(hash) // Suboptimal, but protocol doesn't allow batch header retrievals
}
}()
}
// Schedule the next fetch if blocks are still pending
f.rescheduleFetch(fetchTimer)从Notify的调用中,可以看出,fetcherHeader()的实际函数是RequestOneHeader(),该函数使用的消息是GetBlockHeadersMsg,可以用来请求多个区块头,不过fetcher只请求一个
pm.fetcher.Notify(p.id, block.Hash, block.Number, time.Now(), p.RequestOneHeader, p.RequestBodies)
// RequestOneHeader is a wrapper around the header query functions to fetch a
// single header. It is used solely by the fetcher.
func (p *peer) RequestOneHeader(hash common.Hash) error {
p.Log().Debug("Fetching single header", "hash", hash)
return p2p.Send(p.rw, GetBlockHeadersMsg, &getBlockHeadersData{Origin: hashOrNumber{Hash: hash}, Amount: uint64(1), Skip: uint64(0), Reverse: false})
}GetBlockHeadersMsg的处理如下:因为它是获取多个区块头的,所以处理起来比较“麻烦”,还好,fetcher只获取一个区块头,其处理在20行~33行,获取下一个区块头的处理逻辑,这里就不看了,最后调用SendBlockHeaders()将区块头发送给请求的节点,消息是BlockHeadersMsg。
// handleMsg()
// Block header query, collect the requested headers and reply
case msg.Code == GetBlockHeadersMsg:
// Decode the complex header query
var query getBlockHeadersData
if err := msg.Decode(&query); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
hashMode := query.Origin.Hash != (common.Hash{})
// Gather headers until the fetch or network limits is reached
// 收集区块头,直到达到限制
var (
bytes common.StorageSize
headers []*types.Header
unknown bool
)
// 自己已知区块 && 少于查询的数量 && 大小小于2MB && 小于能下载的最大数量
for !unknown && len(headers) < int(query.Amount) && bytes < softResponseLimit && len(headers) < downloader.MaxHeaderFetch {
// Retrieve the next header satisfying the query
// 获取区块头
var origin *types.Header
if hashMode {
// fetcher 使用的模式
origin = pm.blockchain.GetHeaderByHash(query.Origin.Hash)
} else {
origin = pm.blockchain.GetHeaderByNumber(query.Origin.Number)
}
if origin == nil {
break
}
number := origin.Number.Uint64()
headers = append(headers, origin)
bytes += estHeaderRlpSize
// Advance to the next header of the query
// 下一个区块头的获取,不同策略,方式不同
switch {
case query.Origin.Hash != (common.Hash{}) && query.Reverse:
// ...
}
}
return p.SendBlockHeaders(headers)BlockHeadersMsg的处理很有意思,因为GetBlockHeadersMsg并不是fetcher独占的消息,downloader也可以调用,所以,响应消息的处理需要分辨出是fetcher请求的,还是downloader请求的。它的处理逻辑是:fetcher先过滤收到的区块头,如果fetcher不要的,那就是downloader的,在调用fetcher.FilterHeaders的时候,fetcher就将自己要的区块头拿走了。
// handleMsg()
case msg.Code == BlockHeadersMsg:
// A batch of headers arrived to one of our previous requests
var headers []*types.Header
if err := msg.Decode(&headers); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// If no headers were received, but we're expending a DAO fork check, maybe it's that
// 检查是不是当前DAO的硬分叉
if len(headers) == 0 && p.forkDrop != nil {
// Possibly an empty reply to the fork header checks, sanity check TDs
verifyDAO := true
// If we already have a DAO header, we can check the peer's TD against it. If
// the peer's ahead of this, it too must have a reply to the DAO check
if daoHeader := pm.blockchain.GetHeaderByNumber(pm.chainconfig.DAOForkBlock.Uint64()); daoHeader != nil {
if _, td := p.Head(); td.Cmp(pm.blockchain.GetTd(daoHeader.Hash(), daoHeader.Number.Uint64())) >= 0 {
verifyDAO = false
}
}
// If we're seemingly on the same chain, disable the drop timer
if verifyDAO {
p.Log().Debug("Seems to be on the same side of the DAO fork")
p.forkDrop.Stop()
p.forkDrop = nil
return nil
}
}
// Filter out any explicitly requested headers, deliver the rest to the downloader
// 过滤是不是fetcher请求的区块头,去掉fetcher请求的区块头再交给downloader
filter := len(headers) == 1
if filter {
// If it's a potential DAO fork check, validate against the rules
// 检查是否硬分叉
if p.forkDrop != nil && pm.chainconfig.DAOForkBlock.Cmp(headers[0].Number) == 0 {
// Disable the fork drop timer
p.forkDrop.Stop()
p.forkDrop = nil
// Validate the header and either drop the peer or continue
if err := misc.VerifyDAOHeaderExtraData(pm.chainconfig, headers[0]); err != nil {
p.Log().Debug("Verified to be on the other side of the DAO fork, dropping")
return err
}
p.Log().Debug("Verified to be on the same side of the DAO fork")
return nil
}
// Irrelevant of the fork checks, send the header to the fetcher just in case
// 使用fetcher过滤区块头
headers = pm.fetcher.FilterHeaders(p.id, headers, time.Now())
}
// 剩下的区块头交给downloader
if len(headers) > 0 || !filter {
err := pm.downloader.DeliverHeaders(p.id, headers)
if err != nil {
log.Debug("Failed to deliver headers", "err", err)
}
}FilterHeaders()是一个很有大智慧的函数,看起来耐人寻味,但实在妙。它要把所有的区块头,都传递给fetcher协程,还要获取fetcher协程处理后的结果。fetcher.headerFilter是存放通道的通道,而filter是存放包含区块头过滤任务的通道。它先把filter传递给了headerFilter,这样fetcher协程就在另外一段等待了,而后将headerFilterTask传入filter,fetcher就能读到数据了,处理后,再将数据写回filter而刚好被FilterHeaders函数处理了,该函数实际运行在handleMsg()的协程中。
每个Peer都会分配一个ProtocolManager然后处理该Peer的消息,但fetcher只有一个事件处理协程,如果不创建一个filter,fetcher哪知道是谁发给它的区块头呢?过滤之后,该如何发回去呢?
// FilterHeaders extracts all the headers that were explicitly requested by the fetcher,
// returning those that should be handled differently.
// 寻找出fetcher请求的区块头
func (f *Fetcher) FilterHeaders(peer string, headers []*types.Header, time time.Time) []*types.Header {
log.Trace("Filtering headers", "peer", peer, "headers", len(headers))
// Send the filter channel to the fetcher
// 任务通道
filter := make(chan *headerFilterTask)
select {
// 任务通道发送到这个通道
case f.headerFilter <- filter:
case <-f.quit:
return nil
}
// Request the filtering of the header list
// 创建过滤任务,发送到任务通道
select {
case filter <- &headerFilterTask{peer: peer, headers: headers, time: time}:
case <-f.quit:
return nil
}
// Retrieve the headers remaining after filtering
// 从任务通道,获取过滤的结果并返回
select {
case task := <-filter:
return task.headers
case <-f.quit:
return nil
}
}接下来要看f.headerFilter的处理,这段代码有90行,它做了以下几件事:
- 从f.headerFilter取出filter,然后取出过滤任务task。
- 它把区块头分成3类:unknown这不是分是要返回给调用者的,即handleMsg(), incomplete存放还需要获取body的区块头,complete存放只包含区块头的区块。遍历所有的区块头,填到到对应的分类中,具体的判断可看18行的注释,记住宏观中将的状态转移图。
- 把unknonw中的区块返回给handleMsg()。
- 把 incomplete的区块头获取状态移动到fetched状态,然后触发定时器,以便去处理complete的区块。
- 把compelete的区块加入到queued。
// fetcher.loop()
case filter := <-f.headerFilter:
// Headers arrived from a remote peer. Extract those that were explicitly
// requested by the fetcher, and return everything else so it's delivered
// to other parts of the system.
// 收到从远端节点发送的区块头,过滤出fetcher请求的
// 从任务通道获取过滤任务
var task *headerFilterTask
select {
case task = <-filter:
case <-f.quit:
return
}
headerFilterInMeter.Mark(int64(len(task.headers)))
// Split the batch of headers into unknown ones (to return to the caller),
// known incomplete ones (requiring body retrievals) and completed blocks.
// unknown的不是fetcher请求的,complete放没有交易和uncle的区块,有头就够了,incomplete放
// 还需要获取uncle和交易的区块
unknown, incomplete, complete := []*types.Header{}, []*announce{}, []*types.Block{}
// 遍历所有收到的header
for _, header := range task.headers {
hash := header.Hash()
// Filter fetcher-requested headers from other synchronisation algorithms
// 是正在获取的hash,并且对应请求的peer,并且未fetched,未completing,未queued
if announce := f.fetching[hash]; announce != nil && announce.origin == task.peer && f.fetched[hash] == nil && f.completing[hash] == nil && f.queued[hash] == nil {
// If the delivered header does not match the promised number, drop the announcer
// 高度校验,竟然不匹配,扰乱秩序,peer肯定是坏蛋。
if header.Number.Uint64() != announce.number {
log.Trace("Invalid block number fetched", "peer", announce.origin, "hash", header.Hash(), "announced", announce.number, "provided", header.Number)
f.dropPeer(announce.origin)
f.forgetHash(hash)
continue
}
// Only keep if not imported by other means
// 本地链没有当前区块
if f.getBlock(hash) == nil {
announce.header = header
announce.time = task.time
// If the block is empty (header only), short circuit into the final import queue
// 如果区块没有交易和uncle,加入到complete
if header.TxHash == types.DeriveSha(types.Transactions{}) && header.UncleHash == types.CalcUncleHash([]*types.Header{}) {
log.Trace("Block empty, skipping body retrieval", "peer", announce.origin, "number", header.Number, "hash", header.Hash())
block := types.NewBlockWithHeader(header)
block.ReceivedAt = task.time
complete = append(complete, block)
f.completing[hash] = announce
continue
}
// Otherwise add to the list of blocks needing completion
// 否则就是不完整的区块
incomplete = append(incomplete, announce)
} else {
log.Trace("Block already imported, discarding header", "peer", announce.origin, "number", header.Number, "hash", header.Hash())
f.forgetHash(hash)
}
} else {
// Fetcher doesn't know about it, add to the return list
// 没请求过的header
unknown = append(unknown, header)
}
}
// 把未知的区块头,再传递会filter
headerFilterOutMeter.Mark(int64(len(unknown)))
select {
case filter <- &headerFilterTask{headers: unknown, time: task.time}:
case <-f.quit:
return
}
// Schedule the retrieved headers for body completion
// 把未完整的区块加入到fetched,跳过已经在completeing中的,然后触发completeTimer定时器
for _, announce := range incomplete {
hash := announce.header.Hash()
if _, ok := f.completing[hash]; ok {
continue
}
f.fetched[hash] = append(f.fetched[hash], announce)
if len(f.fetched) == 1 {
f.rescheduleComplete(completeTimer)
}
}
// Schedule the header-only blocks for import
// 把只有头的区块入队列
for _, block := range complete {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}跟随状态图的转义,剩下的工作是fetched转移到completing,上面的流程已经触发了completeTimer定时器,超时后就会处理,流程与请求Header类似,不再赘述,此时发送的请求消息是GetBlockBodiesMsg,实际调的函数是RequestBodies。
// fetcher.loop()
case <-completeTimer.C:
// At least one header's timer ran out, retrieve everything
// 至少有1个header已经获取完了
request := make(map[string][]common.Hash)
// 遍历所有待获取body的announce
for hash, announces := range f.fetched {
// Pick a random peer to retrieve from, reset all others
// 随机选一个Peer发送请求,因为可能已经有很多Peer通知它这个区块了
announce := announces[rand.Intn(len(announces))]
f.forgetHash(hash)
// If the block still didn't arrive, queue for completion
// 如果本地没有这个区块,则放入到completing,创建请求
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
f.completing[hash] = announce
}
}
// Send out all block body requests
// 发送所有的请求,获取body,依然是每个peer一个单独协程
for peer, hashes := range request {
log.Trace("Fetching scheduled bodies", "peer", peer, "list", hashes)
// Create a closure of the fetch and schedule in on a new thread
if f.completingHook != nil {
f.completingHook(hashes)
}
bodyFetchMeter.Mark(int64(len(hashes)))
go f.completing[hashes[0]].fetchBodies(hashes)
}
// Schedule the next fetch if blocks are still pending
f.rescheduleComplete(completeTimer)handleMsg()处理该消息也是干净利落,直接获取RLP格式的body,然后发送响应消息。
// handleMsg()
case msg.Code == GetBlockBodiesMsg:
// Decode the retrieval message
msgStream := rlp.NewStream(msg.Payload, uint64(msg.Size))
if _, err := msgStream.List(); err != nil {
return err
}
// Gather blocks until the fetch or network limits is reached
var (
hash common.Hash
bytes int
bodies []rlp.RawValue
)
// 遍历所有请求
for bytes < softResponseLimit && len(bodies) < downloader.MaxBlockFetch {
// Retrieve the hash of the next block
if err := msgStream.Decode(&hash); err == rlp.EOL {
break
} else if err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Retrieve the requested block body, stopping if enough was found
// 获取body,RLP格式
if data := pm.blockchain.GetBodyRLP(hash); len(data) != 0 {
bodies = append(bodies, data)
bytes += len(data)
}
}
return p.SendBlockBodiesRLP(bodies)响应消息BlockBodiesMsg的处理与处理获取header的处理原理相同,先交给fetcher过滤,然后剩下的才是downloader的。需要注意一点,响应消息里只包含交易列表和叔块列表。
// handleMsg()
case msg.Code == BlockBodiesMsg:
// A batch of block bodies arrived to one of our previous requests
var request blockBodiesData
if err := msg.Decode(&request); err != nil {
return errResp(ErrDecode, "msg %v: %v", msg, err)
}
// Deliver them all to the downloader for queuing
// 传递给downloader去处理
transactions := make([][]*types.Transaction, len(request))
uncles := make([][]*types.Header, len(request))
for i, body := range request {
transactions[i] = body.Transactions
uncles[i] = body.Uncles
}
// Filter out any explicitly requested bodies, deliver the rest to the downloader
// 先让fetcher过滤去fetcher请求的body,剩下的给downloader
filter := len(transactions) > 0 || len(uncles) > 0
if filter {
transactions, uncles = pm.fetcher.FilterBodies(p.id, transactions, uncles, time.Now())
}
// 剩下的body交给downloader
if len(transactions) > 0 || len(uncles) > 0 || !filter {
err := pm.downloader.DeliverBodies(p.id, transactions, uncles)
if err != nil {
log.Debug("Failed to deliver bodies", "err", err)
}
}过滤函数的原理也与Header相同。
// FilterBodies extracts all the block bodies that were explicitly requested by
// the fetcher, returning those that should be handled differently.
// 过去出fetcher请求的body,返回它没有处理的,过程类型header的处理
func (f *Fetcher) FilterBodies(peer string, transactions [][]*types.Transaction, uncles [][]*types.Header, time time.Time) ([][]*types.Transaction, [][]*types.Header) {
log.Trace("Filtering bodies", "peer", peer, "txs", len(transactions), "uncles", len(uncles))
// Send the filter channel to the fetcher
filter := make(chan *bodyFilterTask)
select {
case f.bodyFilter <- filter:
case <-f.quit:
return nil, nil
}
// Request the filtering of the body list
select {
case filter <- &bodyFilterTask{peer: peer, transactions: transactions, uncles: uncles, time: time}:
case <-f.quit:
return nil, nil
}
// Retrieve the bodies remaining after filtering
select {
case task := <-filter:
return task.transactions, task.uncles
case <-f.quit:
return nil, nil
}
}实际过滤body的处理瞧一下,这和Header的处理是不同的。直接看不点:
- 它要的区块,单独取出来存到blocks中,它不要的继续留在task中。
- 判断是不是fetcher请求的方法:如果交易列表和叔块列表计算出的hash值与区块头中的一样,并且消息来自请求的Peer,则就是fetcher请求的。
- 将blocks中的区块加入到queued,终结。
case filter := <-f.bodyFilter:
// Block bodies arrived, extract any explicitly requested blocks, return the rest
var task *bodyFilterTask
select {
case task = <-filter:
case <-f.quit:
return
}
bodyFilterInMeter.Mark(int64(len(task.transactions)))
blocks := []*types.Block{}
// 获取的每个body的txs列表和uncle列表
// 遍历每个区块的txs列表和uncle列表,计算hash后判断是否是当前fetcher请求的body
for i := 0; i < len(task.transactions) && i < len(task.uncles); i++ {
// Match up a body to any possible completion request
matched := false
// 遍历所有保存的请求,因为tx和uncle,不知道它是属于哪个区块的,只能去遍历所有的请求,通常量不大,所以遍历没有性能影响
for hash, announce := range f.completing {
if f.queued[hash] == nil {
// 把传入的每个块的hash和unclehash和它请求出去的记录进行对比,匹配则说明是fetcher请求的区块body
txnHash := types.DeriveSha(types.Transactions(task.transactions[i]))
uncleHash := types.CalcUncleHash(task.uncles[i])
if txnHash == announce.header.TxHash && uncleHash == announce.header.UncleHash && announce.origin == task.peer {
// Mark the body matched, reassemble if still unknown
matched = true
// 如果当前链还没有这个区块,则收集这个区块,合并成新区块
if f.getBlock(hash) == nil {
block := types.NewBlockWithHeader(announce.header).WithBody(task.transactions[i], task.uncles[i])
block.ReceivedAt = task.time
blocks = append(blocks, block)
} else {
f.forgetHash(hash)
}
}
}
}
// 从task中移除fetcher请求的数据
if matched {
task.transactions = append(task.transactions[:i], task.transactions[i+1:]...)
task.uncles = append(task.uncles[:i], task.uncles[i+1:]...)
i--
continue
}
}
// 将剩余的数据返回
bodyFilterOutMeter.Mark(int64(len(task.transactions)))
select {
case filter <- task:
case <-f.quit:
return
}
// Schedule the retrieved blocks for ordered import
// 把收集的区块加入到队列
for _, block := range blocks {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}
}至此,fetcher获取完整区块的流程讲完了,fetcher模块中80%的代码也都贴出来了,还有2个值得看看的函数:
- forgetHash(hash common.Hash) :用于清空指定hash值的记/状态录信息。
- forgetBlock(hash common.Hash):用于从队列中移除一个区块。
最后了,再回到开始看看fetcher模块和新区块的传播流程,有没有豁然开朗。
转载自:https://lessisbetter.site/2018/08/30/ethereum-fetcher-module-and-block-propagate/
以太坊源码分析:事件框架
过去在学Actor模型的时候,就认为异步消息是相当的重要,在华为的时候,也深扒了一下当时产品用的消息模型,简单实用,支撑起了很多模块和业务,但也有一个缺点是和其他的框架有耦合,最近看到以太坊的事件框架,同样简单简洁,理念很适合初步接触事件框架的同学,写文介绍一下。
以太坊的事件框架是一个单独的基础模块,存在于目录go-ethereum/event中,它有2中独立的事件框架实现,老点的叫TypeMux,已经基本弃用,新的叫Feed,当前正在广泛使用。
TypeMux和Feed还只是简单的事件框架,与Kafka、RocketMQ等消息系统相比,是非常的传统和简单,但是TypeMux和Feed的简单简洁,已经很好的支撑以太坊的上层模块,这是当下最好的选择。
TypeMux和Feed各有优劣,最优秀的共同特点是,他们只依赖于Golang原始的包,完全与以太坊的其他模块隔离开来,也就是说,你完全可以把这两个事件框架用在自己的项目中。
TypeMux的特点是,你把所有的订阅塞给它就好,事件来了它自会通知你,但有可能会阻塞,通知你不是那么及时,甚至过了一段挺长的时间。
Feed的特点是,它通常不存在阻塞的情况,会及时的把事件通知给你,但需要你为每类事件都建立一个Feed,然后不同的事件去不同的Feed上订阅和发送,这其实挺烦人的,如果你用错了Feed,会导致panic。
接下来,介绍下这种简单事件框架的抽象模型,然后再回归到以太坊,介绍下TypeMux和Feed。
事件框架的抽象结构
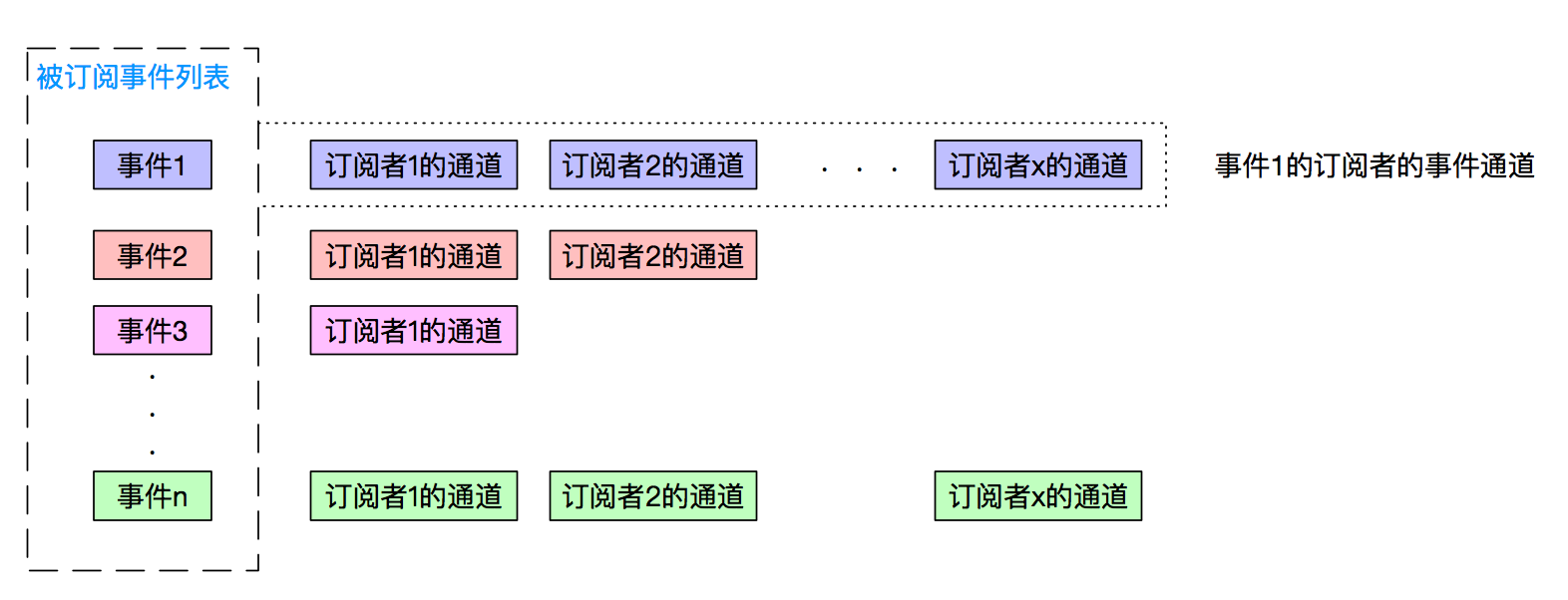
如上图,轻量级的事件框架会把所有的被订阅的事件收集起来,然后把每个订阅者组合成一个列表,当事件框架收到某个事件的时候,就把订阅该事件的所有订阅者找出来,然后把这个事件发给他们。
它需要具有2个功能:
- 让订阅者订阅、取消订阅某类事件。
- 让发布者能够发布某个事件,并且把事件送到每个订阅者。
如果做成完善的消息系统,就还得考虑这些特性:可用性、吞吐量、传输延迟、有序消息、消息存储、过滤、重发,这和事件框架相比就复杂上去了,我们专注的介绍下以太坊的事件模型怎么完成上述3个功能的。
以太坊的事件模型
TypeMux是一个以太坊不太满意的事件框架,所以以太坊就搞了Feed出来,它解决了TypeMux效率低下,延迟交付的问题。接下来就先看下这个TypeMux。
TypeMux:同步事件框架
TypeMux是一个同步事件框架。它的实现和上面讲的事件框架的抽象结构是完全一样的,它维护了一个订阅表,表里维护了每个事件的订阅者列表。它的特点:
- 采用多对多结构:多个事件对多个订阅者。
- 采用推模式,把事件/消息推送给订阅者,就像信件一样,会被送到你的信箱,你在信箱里取信就行了。
- 是一个同步事件框架。这也是它的缺点所在,举个例子就是:邮递员要给小红、小明送信,只有信箱里的信被小红取走后,邮递员才去给小明送信,如果小红旅游去了无法取信,邮递员就一直等在小红家,而小明一直收不到信,小明很无辜无辜啊!
看下它2个功能的实现:
- 订阅和取消订阅。订阅通过函数TypeMux.Subscribe(),入参为要订阅的事件类型,会返回TypeMuxSubscription给订阅者,订阅者可通过此控制订阅,通过TypeMuxSubscription.Unsubscribe() 可以取消订阅。
- 发布事件和传递事件。TypeMux.Post(),入参为事件类型,根据订阅表找出该事件的订阅者列表,遍历列表,依次向每个订阅者传递事件,如果前一个没有传递完成进入阻塞,会导致后边的订阅者不能及时收到事件。
TypeMux源码速递
TypeMux的精简组成:
// A TypeMux dispatches events to registered receivers. Receivers can be
// registered to handle events of certain type. Any operation
// called after mux is stopped will return ErrMuxClosed.
//
// The zero value is ready to use.
//
// Deprecated: use Feed
// 本质:哈希列表,每个事件的订阅者都存到对于的列表里
type TypeMux struct {
mutex sync.RWMutex // 锁
subm map[reflect.Type][]*TypeMuxSubscription // 订阅表:所有事件类型的所有订阅者
stopped bool
}订阅:
// Subscribe creates a subscription for events of the given types. The
// subscription's channel is closed when it is unsubscribed
// or the mux is closed.
// 订阅者只传入订阅的事件类型,然后TypeMux会返回给它一个订阅对象
func (mux *TypeMux) Subscribe(types ...interface{}) *TypeMuxSubscription {
sub := newsub(mux)
mux.mutex.Lock()
defer mux.mutex.Unlock()
if mux.stopped {
// set the status to closed so that calling Unsubscribe after this
// call will short circuit.
sub.closed = true
close(sub.postC)
} else {
if mux.subm == nil {
mux.subm = make(map[reflect.Type][]*TypeMuxSubscription)
}
for _, t := range types {
rtyp := reflect.TypeOf(t)
// 在同一次订阅中,不要重复订阅同一个类型的事件
oldsubs := mux.subm[rtyp]
if find(oldsubs, sub) != -1 {
panic(fmt.Sprintf("event: duplicate type %s in Subscribe", rtyp))
}
subs := make([]*TypeMuxSubscription, len(oldsubs)+1)
copy(subs, oldsubs)
subs[len(oldsubs)] = sub
mux.subm[rtyp] = subs
}
}
return sub
}取消订阅:
func (s *TypeMuxSubscription) Unsubscribe() {
s.mux.del(s)
s.closewait()
}发布事件和传递事件:
// Post sends an event to all receivers registered for the given type.
// It returns ErrMuxClosed if the mux has been stopped.
// 遍历map,找到所有订阅的人,向它们传递event,同一个event对象,非拷贝,运行在调用者goroutine
func (mux *TypeMux) Post(ev interface{}) error {
event := &TypeMuxEvent{
Time: time.Now(),
Data: ev,
}
rtyp := reflect.TypeOf(ev)
mux.mutex.RLock()
if mux.stopped {
mux.mutex.RUnlock()
return ErrMuxClosed
}
subs := mux.subm[rtyp]
mux.mutex.RUnlock()
for _, sub := range subs {
sub.deliver(event)
}
return nil
}
func (s *TypeMuxSubscription) deliver(event *TypeMuxEvent) {
// Short circuit delivery if stale event
// 不发送过早(老)的消息
if s.created.After(event.Time) {
return
}
// Otherwise deliver the event
s.postMu.RLock()
defer s.postMu.RUnlock()
select {
case s.postC <- event:
case <-s.closing:
}
}我上面指出了发送事件可能阻塞,阻塞在哪?关键就在下面这里:创建TypeMuxSubscription时,通道使用的是无缓存通道,读写是同步的,这里注定了TypeMux是一个同步事件框架,这是以太坊改用Feed的最大原因。
func newsub(mux *TypeMux) *TypeMuxSubscription {
c := make(chan *TypeMuxEvent) // 无缓冲通道,同步读写
return &TypeMuxSubscription{
mux: mux,
created: time.Now(),
readC: c,
postC: c,
closing: make(chan struct{}),
}
}Feed:流式框架
Feed是一个流式事件框架。上文强调了TypeMux是一个同步框架,也正是因为此以太坊丢弃了它,难道Feed就是一个异步框架?不一定是的,这取决于订阅者是否采用有缓存的通道,采用有缓存的通道,则Feed就是异步的,采用无缓存的通道,Feed就是同步的,把同步还是异步的选择交给使用者。
本节强调Feed的流式特点。事件本质是一个数据,连续不断的事件就组成了一个数据流,这些数据流不停的流向它的订阅者那里,并且不会阻塞在任何一个订阅者那里。
举几个不是十分恰当的例子。
- 公司要放中秋节,HR给所有同事都发了一封邮件,有些同事读了,有些同事没读,要到国庆节了HR又给所有同事发了一封邮件,这些邮件又进入到每个人的邮箱,不会因为任何一个人没有读邮件,导致剩下的同事收不到邮件。
- 你在朋友圈给朋友旅行的照片点了个赞,每当你们共同朋友点赞或者评论的时候,你都会收到提醒,无论你看没看这些提醒,这些提醒都会不断的发过来。
- 你微博关注了苍井空,苍井空发了个搞笑的视频,你刷微博的时候就收到了,但也有很多人根本没刷微博,你不会因为别人没有刷,你就收不到苍井空的动态。
Feed和TypeMux相同的是,它们都是推模式,不同的是Feed是异步的,如果有些订阅者阻塞了,没关系,它会继续向后面的订阅者发送事件/消息。
Feed是一个一对多的事件流框架。每个类型的事件都需要一个与之对应的Feed,订阅者通过这个Feed进行订阅事件,发布者通过这个Feed发布事件。
看下Feed是如何实现2个功能的:
- 订阅和取消订阅:Feed.Subscribe(),入参是一个通道,通常是有缓冲的,就算是无缓存也不会造成Feed阻塞,Feed会校验这个通道的类型和本Feed管理的事件类型是否一致,然后把通道保存下来,返回给订阅者一个Subscription,可以通过它取消订阅和读取通道错误。
- 发布事件和传递事件。Feed.Send()入参是一个事件,加锁确保本类型事件只有一个发送协程正在进行,然后校验事件类型是否匹配,Feed会尝试给每个订阅者发送事件,如果订阅者阻塞,Feed就继续尝试给下一个订阅者发送,直到给每个订阅者发送事件,返回发送该事件的数量。
Feed源码速递
Feed定义:
// Feed implements one-to-many subscriptions where the carrier of events is a channel.
// Values sent to a Feed are delivered to all subscribed channels simultaneously.
//
// Feeds can only be used with a single type. The type is determined by the first Send or
// Subscribe operation. Subsequent calls to these methods panic if the type does not
// match.
//
// The zero value is ready to use.
// 一对多的事件订阅管理:每个feed对象,当别人调用send的时候,会发送给所有订阅者
// 每种事件类型都有一个自己的feed,一个feed内订阅的是同一种类型的事件,得用某个事件的feed才能订阅该事件
type Feed struct {
once sync.Once // ensures that init only runs once
sendLock chan struct{} // sendLock has a one-element buffer and is empty when held.It protects sendCases. 这个锁确保了只有一个协程在使用go routine
removeSub chan interface{} // interrupts Send
sendCases caseList // the active set of select cases used by Send,订阅的channel列表,这些channel是活跃的
// The inbox holds newly subscribed channels until they are added to sendCases.
mu sync.Mutex
inbox caseList // 不活跃的在这里
etype reflect.Type
closed bool
}订阅事件:
// Subscribe adds a channel to the feed. Future sends will be delivered on the channel
// until the subscription is canceled. All channels added must have the same element type.
//
// The channel should have ample buffer space to avoid blocking other subscribers.
// Slow subscribers are not dropped.
// 订阅者传入接收事件的通道,feed将通道保存为case,然后返回给订阅者订阅对象
func (f *Feed) Subscribe(channel interface{}) Subscription {
f.once.Do(f.init)
// 通道和通道类型检查
chanval := reflect.ValueOf(channel)
chantyp := chanval.Type()
if chantyp.Kind() != reflect.Chan || chantyp.ChanDir()&reflect.SendDir == 0 {
panic(errBadChannel)
}
sub := &feedSub{feed: f, channel: chanval, err: make(chan error, 1)}
f.mu.Lock()
defer f.mu.Unlock()
if !f.typecheck(chantyp.Elem()) {
panic(feedTypeError{op: "Subscribe", got: chantyp, want: reflect.ChanOf(reflect.SendDir, f.etype)})
}
// 把通道保存到case
// Add the select case to the inbox.
// The next Send will add it to f.sendCases.
cas := reflect.SelectCase{Dir: reflect.SelectSend, Chan: chanval}
f.inbox = append(f.inbox, cas)
return sub
}发送和传递事件:这个发送是比较绕一点的,要想真正掌握其中的运行,最好写个小程序练习下。
// Send delivers to all subscribed channels simultaneously.
// It returns the number of subscribers that the value was sent to.
// 同时向所有的订阅者发送事件,返回订阅者的数量
func (f *Feed) Send(value interface{}) (nsent int) {
rvalue := reflect.ValueOf(value)
f.once.Do(f.init)
<-f.sendLock // 获取发送锁
// Add new cases from the inbox after taking the send lock.
// 从inbox加入到sendCases,不能订阅的时候直接加入到sendCases,因为可能其他协程在调用发送
f.mu.Lock()
f.sendCases = append(f.sendCases, f.inbox...)
f.inbox = nil
// 类型检查:如果该feed不是要发送的值的类型,释放锁,并且执行panic
if !f.typecheck(rvalue.Type()) {
f.sendLock <- struct{}{}
panic(feedTypeError{op: "Send", got: rvalue.Type(), want: f.etype})
}
f.mu.Unlock()
// Set the sent value on all channels.
// 把发送的值关联到每个case/channel,每一个事件都有一个feed,所以这里全是同一个事件的
for i := firstSubSendCase; i < len(f.sendCases); i++ {
f.sendCases[i].Send = rvalue
}
// Send until all channels except removeSub have been chosen. 'cases' tracks a prefix
// of sendCases. When a send succeeds, the corresponding case moves to the end of
// 'cases' and it shrinks by one element.
// 所有case仍然保留在sendCases,只是用过的会移动到最后面
cases := f.sendCases
for {
// Fast path: try sending without blocking before adding to the select set.
// This should usually succeed if subscribers are fast enough and have free
// buffer space.
// 使用非阻塞式发送,如果不能发送就及时返回
for i := firstSubSendCase; i < len(cases); i++ {
// 如果发送成功,把这个case移动到末尾,所以i这个位置就是没处理过的,然后大小减1
if cases[i].Chan.TrySend(rvalue) {
nsent++
cases = cases.deactivate(i)
i--
}
}
// 如果这个地方成立,代表所有订阅者都不阻塞,都发送完了
if len(cases) == firstSubSendCase {
break
}
// Select on all the receivers, waiting for them to unblock.
// 返回一个可用的,直到不阻塞。
chosen, recv, _ := reflect.Select(cases)
if chosen == 0 /* <-f.removeSub */ {
// 这个接收方要删除了,删除并缩小sendCases
index := f.sendCases.find(recv.Interface())
f.sendCases = f.sendCases.delete(index)
if index >= 0 && index < len(cases) {
// Shrink 'cases' too because the removed case was still active.
cases = f.sendCases[:len(cases)-1]
}
} else {
// reflect已经确保数据已经发送,无需再尝试发送
cases = cases.deactivate(chosen)
nsent++
}
}
// 把sendCases中的send都标记为空
// Forget about the sent value and hand off the send lock.
for i := firstSubSendCase; i < len(f.sendCases); i++ {
f.sendCases[i].Send = reflect.Value{}
}
f.sendLock <- struct{}{}
return nsent
}转载自:https://lessisbetter.site/2018/10/18/ethereum-code-event-framework/
以太坊源码分析:statedb
前言
就如以太坊黄皮书讲的,以太坊是状态机,区块的产生,实际是状态迁移的过程。那以太坊
- 是如何定义状态的?
- 是如何迁移状态的?
- 是怎么存储状态的?
这篇文章就介绍什么是状态,以及是怎么存储的。
状态基本知识
状态的定义
一个账户的信息,就是一个状态,而以太坊是所有状态的集合。比如,最开始的状态是:{A有10元,B有0元},后来A发起了交易,给B 2元,状态变成{A有8元,B有2元},这中间的过程就是状态转移。
以太坊实际最初的状态是创世块,每产生一个新区块就转移到一个新的状态。
状态表示
以太坊使用root表示状态。以太坊使用Trie组织状态,Trie可以理解为是字典树和默克尔树的结合,它有一个树根root,有这个root,你就可以访问所有的状态数据,即每个账户的信息,所以用root来表示一个状态。
获取状态
区块头中有一个字段Root,所以找到区块头,就能获取区块链的状态。
状态存在哪
状态不存在区块中。区块头中存放了root,这只是一个地址,从区块中并不能找到状态的数据。
状态只是临时的数据,可以再生成。创世块是最初的状态,把第一个区块中的交易都执行一遍,就得到了一个新的状态,把这个状态的root存到第一个区块头的Root中。如果有所有的区块,就可以把所有的交易都执行,然后生成最新区块中的状态。
状态存放在外部数据库。以太坊底层的数据库是LevelDB,区块存放在里面,状态也存放在里面。但状态是一个Trie,不能直接存在LevelDB里面。
StateDB
StateDB,从名字就能看出来,是用来存储状态的数据库。它把Trie和DB结合了起来,实现了对状态的存储、更新、回滚。我们先介绍它的设计思路,然后再介绍一些它的骨干实现。
StateDB的设计
以太坊使用LevelDB作为底层的存储数据库,虽然leveldb能够满足存取状态,但没有缓存功能、快速访问和修改状态等特性,以太坊实现了StateDB,来满足自身的需求。
我们就介绍下,它是如何设计来实现以上特性的。
底层存储设计
使用Trie实现快速访问。上文提到了,Trie是字典树和默克尔树的结合,可以实现快速查找,这里就看它是如何使用Trie的。
使用内存实现缓存。常用的数据,会被计算机留在内存中,同样,常用的状态也被留在内存中,并且使用StateDB把它们管理起来。
StateDB定义了2个接口:Trie和Database:Trie建立在Database之上,Trie的数据存放在Database中。

- Trie被定义为带有缓存的KV数据库。你可以通过它快速存储、更新、删除数据。
- Database被定义为一个打开Trie、拷贝Trie的数据库。它不直接对外访问,不能直接使用它存取数据。
在代码实现上,cachedTrie实现了Trie,cachingDB实现了Databse,他们定义在core/state/database.go
// 实现Database接口,缓存常用的trie
type cachingDB struct {
//保存trie数据的db
db *trie.Database
mu sync.Mutex
// 缓存过去的trie,队列类型
pastTries []*trie.SecureTrie
codeSizeCache *lru.Cache
}
// 包含了trie和缓存db,trie实际是存在db中的
type cachedTrie struct {
*trie.SecureTrie
db *cachingDB
}
//从db中打开一个trie,如果不是最近使用过,则创建一个新的,存到db
func (db *cachingDB) OpenTrie(root common.Hash) (Trie, error) {
db.mu.Lock()
defer db.mu.Unlock()
for i := len(db.pastTries) - 1; i >= 0; i-- {
if db.pastTries[i].Hash() == root {
return cachedTrie{db.pastTries[i].Copy(), db}, nil
}
}
tr, err := trie.NewSecure(root, db.db, MaxTrieCacheGen)
if err != nil {
return nil, err
}
return cachedTrie{tr, db}, nil
}StateDB的状态组织设计
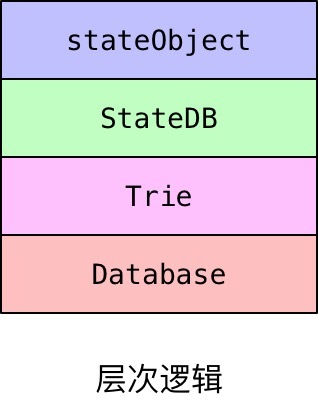
StateDB使用Trie存放stateObject,是账户地址到账户信息的映射,每个stateObject都是一个账户的信息。
stateObject使用Trie存放数据,这些数据被称为storage,实现对某个账户的状态数据的存储和修改,key是数据的hash值,value是状态数据。
StateDB和stateObject都使用Database存放了自己的Trie,他们使用的是同一个DB。
但从逻辑层次上看,他们满足这种关系:
事务和回滚设计
stateDB这个KV数据库,实现了类似传统数据库的事务和回滚设计。每一个交易都是一个事务,每一个交易的执行,都是一次状态转移,在执行交易之前,先创建当前的快照,执行交易的过程中,会记录状态数据的每一次修改,如果交易执行失败,则进行回滚,交易执行完毕,会把所有修改的状态数据写入到Trie,然后更新Trie的根。
在生成1个区块的时候,会进行很多次Finalise,回滚是不能跨越交易的,也就是说,当前交易失败了,我不能回滚到上上一条交易。生成区块的时候,最后一次Finalize的Trie的Root,会保存到区块头的Header.Root。当区块要写入到区块链的时候,会执行一次Commit。

关于Finalise和Commit的主要调用关系如下图:
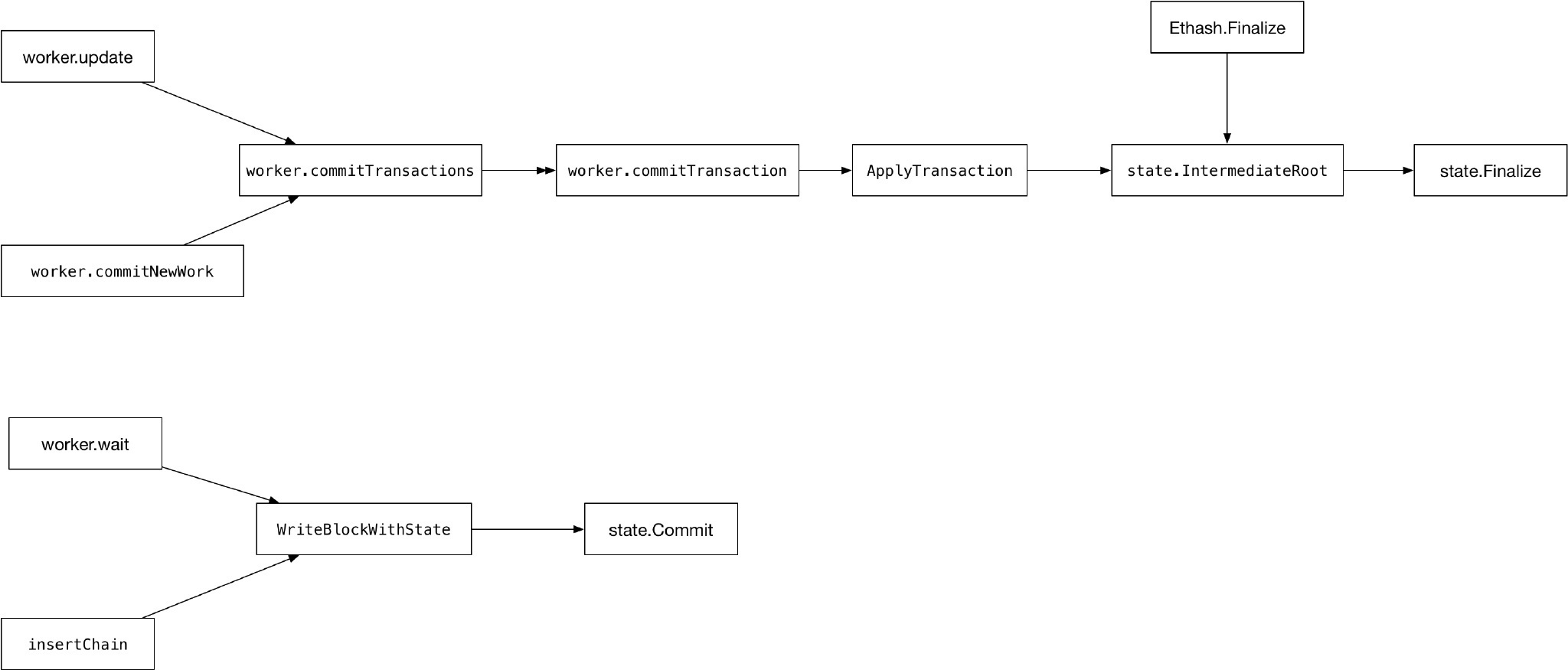
Finalise的主要调用场景是:
- 执行交易/合约,进行一次状态转移。
- 给矿工计算奖励后,进行一次状态转移。
Commit的主要调用场景是插入区块链,有2种情况:
- 自己挖到区块。
- 收到他人的区块。
StateDB的骨干实现
基于上面对StateDB设计的了解,我们再介绍一下StateDB一些主要的实现。这一小节主要覆盖以下内容:
- state所在的目录和文件划分。
- stateObject实现。
- stateDB的实现。
state目录和文件划分
state所在的目录是:core/state,它的文件和每个文件的主要功能如下:
core/state
├── database.go,底层的存储设计,`Trie`和`Database`定义在此文件。
├── dump.go,用来dumpstateDB数据。
├── iterator.go,用来遍历`Trie`。
├── journal.go,用来记录状态的每一步改变。
├── managed_state.go,给txpool使用,具体功能未研究。
├── state_object.go,每一个账户的状态。
├── statedb.go,以太坊整个的状态。
├── sync.go,用来和downloader结合起来同步state。关于stateDB如何存储状态,主要关注这3个文件:
- database.go
- state_object.go
- statedb.go
接下来通过源码介绍这3个文件的功能和实现。
database.go
database.go的主要代码和设计,已经在底层存储设计的时候介绍过了,这里补充介绍另外一个重要的函数OpenStorageTrie它与OpenTrie的区别:
- 实现区别,OpenTrie会先从db中查找,如果每找到才创建一个,而OpenStorageTrie是直接创建一个。
- 功能区别,OpenTrie创建的stateDB的Trie,而OpenStorageTrie创建的是stateObject的Trie。
把1和2合并:cachingDB会缓存stateDB使用的Trie,而不会缓存stateObject使用的Trie。
// OpenStorageTrie opens the storage trie of an account.
// 创建一个账户的存储trie,但实际没有使用到addrHash
func (db *cachingDB) OpenStorageTrie(addrHash, root common.Hash) (Trie, error) {
return trie.NewSecure(root, db.db, 0)
}
// OpenTrie opens the main account trie.
// 从db中打开一个trie,如果不是最近使用过,则创建一个新的,存到db
func (db *cachingDB) OpenTrie(root common.Hash) (Trie, error) {
db.mu.Lock()
defer db.mu.Unlock()
for i := len(db.pastTries) - 1; i >= 0; i-- {
if db.pastTries[i].Hash() == root {
return cachedTrie{db.pastTries[i].Copy(), db}, nil
}
}
tr, err := trie.NewSecure(root, db.db, MaxTrieCacheGen)
if err != nil {
return nil, err
}
return cachedTrie{tr, db}, nil
}state_object.go
该文件主要实现最小状态的存储和修改。stateObject代表最小粒度的状态,它是一个账户的状态信息。我们先看下基础的数据结构定义,再看它实现的主要功能。
账户和stateObject
以太坊的账户分为普通账户和合约账户,在代码上,他们都是用Account来表示,它记录了账户的数据,有:Nonce,余额,状态树根Root和合约代码的哈希值CodeHash。
// Account is the Ethereum consensus representation of accounts.
// These objects are stored in the main account trie.
// Account是账户的数据,不包含账户地址
// 账户需要使用地址来表示,地址在stateObject中
type Account struct {
// 每执行1次交易,Nonce+1
Nonce uint64
Balance *big.Int
// 该账户的状态,即trie的根
Root common.Hash // merkle root of the storage trie
// 合约账户专属,合约代码编译后的Hash值
CodeHash []byte
}以上是账户的数据,那如何表示一个账户呢?
使用账户地址表示账户,它记录在stateObject中:
// stateObject represents an Ethereum account which is being modified.
//
// The usage pattern is as follows:
// First you need to obtain a state object.
// Account values can be accessed and modified through the object.
// Finally, call CommitTrie to write the modified storage trie into a database.
// 地址、账户、账户哈希、数据库
type stateObject struct {
// 账户信息
address common.Address
addrHash common.Hash // hash of ethereum address of the account
data Account
code Code
// 更多信息省略
}所以 一个stateObject记录了一个完整的账户信息:Account + Address + Code。
再来看下stateObject的完整信息,它记录了:账户信息、EVM执行过程中的错误、保存数据的storage trie、合约代码、缓存的storage数据cachedStorage、修改过的storage数据dirtyStorage,剩下的信息先忽略。storage代表了该对象/账户中存储的KV数据。
type stateObject struct {
// 账户信息
address common.Address
addrHash common.Hash // hash of ethereum address of the account
data Account
// 所属于的stateDB
db *StateDB
// DB error.
// State objects are used by the consensus core and VM which are
// unable to deal with database-level errors. Any error that occurs
// during a database read is memoized http://lessisbetter.site/2018/06/22/ethereum-code-statedb/ and will eventually be returned
// by StateDB.Commit.
// VM不处理db层的错误,先记录下来,最后返回,只能保存1个错误,保存存的第一个错误
dbErr error
// Write caches.
// 使用trie组织stateObj的数据
trie Trie // storage trie, which becomes non-nil on first access
// 合约代码
code Code // contract bytecode, which gets set when code is loaded
// 存缓存,避免重复从数据库读
cachedStorage Storage // Storage entry cache to avoid duplicate reads
// 需要写到磁盘的缓存
dirtyStorage Storage // Storage entries that need to be flushed to disk
// Cache flags.
// When an object is marked suicided it will be delete from the trie
// during the "update" phase of the state transition.
dirtyCode bool // true if the code was updated
// 标记suicided,代表这个对象要从trie删除,在update阶段
suicided bool
deleted bool
}账户地址和账户信息是stateObject的核心数据,有他们2个就能建立一个stateObject:
// newObject creates a state object.
// 使用地址和账户创建stateObject
func newObject(db *StateDB, address common.Address, data Account) *stateObject {
if data.Balance == nil {
data.Balance = new(big.Int)
}
if data.CodeHash == nil {
data.CodeHash = emptyCodeHash
}
return &stateObject{
db: db,
address: address,
addrHash: crypto.Keccak256Hash(address[:]),
data: data,
cachedStorage: make(Storage),
dirtyStorage: make(Storage),
}
}stateObject的重要函数
stateObject保存了2个重要信息:
- 账户的信息:Account、Address、Code。创建账户之后,这些数据就不变了。
- 账户的数据:trie。对于合约账户,trie用来存储数据,因此trie是经常变化的。比如,投票合约,有新的投票,就有新的数据产生和改变,trie也就发生改变。
掌握关于trie的函数,就掌握了stateObject的核心操作:
- func (c *stateObject) getTrie(db Database) Trie。获取当前账户的trie。
- func (self *stateObject) SetState(db Database, key, value common.Hash)。设置trie中的kv数据对,能够完成创建、更新、删除功能。
- func (self *stateObject) updateRoot(db Database)。更新trie的根。
- func (self *stateObject) updateTrie(db Database) Trie。更新trie,把账户中修改过的数据写入到trie。
剩余的函数都是stateObject的基本Get和Set函数。
// 获取当前账户的trie,如果没有,则创建一个空的
func (c *stateObject) getTrie(db Database) Trie {
if c.trie == nil {
var err error
c.trie, err = db.OpenStorageTrie(c.addrHash, c.data.Root)
if err != nil {
c.trie, _ = db.OpenStorageTrie(c.addrHash, common.Hash{})
c.setError(fmt.Errorf("can't create storage trie: %v", err))
}
}
return c.trie
}
// SetState updates a value in account storage.
// 设置一个新的kv:保存过去的kv,然后设置新的。
func (self *stateObject) SetState(db Database, key, value common.Hash) {
self.db.journal.append(storageChange{
account: &self.address,
key: key,
prevalue: self.GetState(db, key),
})
self.setState(key, value)
}
// 先加入缓存和dirty
func (self *stateObject) setState(key, value common.Hash) {
self.cachedStorage[key] = value
self.dirtyStorage[key] = value
}
// updateTrie writes cached storage modifications into the object's storage trie.
// 把标记为dirty的kv写入、删除、更新到存储trie、
func (self *stateObject) updateTrie(db Database) Trie {
tr := self.getTrie(db)
for key, value := range self.dirtyStorage {
delete(self.dirtyStorage, key)
// 空value代表删除kv
if (value == common.Hash{}) {
self.setError(tr.TryDelete(key[:]))
continue
}
// Encoding []byte cannot fail, ok to ignore the error.
v, _ := rlp.EncodeToBytes(bytes.TrimLeft(value[:], "\x00"))
self.setError(tr.TryUpdate(key[:], v))
}
return tr
}
// UpdateRoot sets the trie root to the current root hash of
// 更新root:更新trie,然后获取新的root。Finalize使用
func (self *stateObject) updateRoot(db Database) {
self.updateTrie(db)
self.data.Root = self.trie.Hash()
}statedb.go
该文件主要实现stateDB的功能:
- 存储所有的账户信息(stateObject)。
- 提供增删、修改账户的状态数据(stateObject)的接口。
- Finalise和提交修改的账户信息(stateObject)。
- 对每个状态数据改变记录日志,创建快照,实现回滚。
接下来对这4个功能依次介绍。
存储账户信息
关于对stateObject的存储,之前是设计已经讲过其存储思路。现从StateDB的定义讲存储和管理stateObject:
- 使用trie来组织它所有的stateObject。
- 使用db存储trie。
- 使用stateObjects存储最近使用过的stateObject。
- 使用stateObjectsDirty存储被修改过的stateObject。
// StateDBs within the ethereum protocol are used to store anything
// within the merkle trie. StateDBs take care of caching and storing
// nested states. It's the general query interface to retrieve:
// * Contracts
// * Accounts
// 在merkle树种保存任何数据,形式是kv
type StateDB struct {
// 存储本Trie的数据库
db Database
// 存储所有的stateObject
trie Trie
// This map holds 'live' objects, which will get modified while processing a state transition.
// 最近使用过的数据对象,他们的账户地址为key
stateObjects map[common.Address]*stateObject
// 修改过的账户对象
stateObjectsDirty map[common.Address]struct{}
// DB error.
// State objects are used by the consensus core and VM which are
// unable to deal with database-level errors. Any error that occurs
// during a database read is memoized http://lessisbetter.site/2018/06/22/ethereum-code-statedb/ and will eventually be returned
// by StateDB.Commit.
dbErr error
// The refund counter, also used by state transitioning.
refund uint64
thash, bhash common.Hash
txIndex int
logs map[common.Hash][]*types.Log
logSize uint
preimages map[common.Hash][]byte
// Journal of state modifications. This is the backbone of
// Snapshot and RevertToSnapshot.
// 快照和回滚的主要参数
// 存放每一步修改了啥
journal *journal
// 快照id和journal的长度组成revision,可以回滚
validRevisions []revision
// 下一个可用的快照id
nextRevisionId int
lock sync.Mutex
}创建StateDB很简单,传入已知的root和使用的db即可。调用cachingDB.OpenTrie打开一个trie,该trie就用来存放所有的stateObject。
func New(root common.Hash, db Database) (*StateDB, error) {
tr, err := db.OpenTrie(root)
if err != nil {
return nil, err
}
return &StateDB{
db: db,
trie: tr,
stateObjects: make(map[common.Address]*stateObject),
stateObjectsDirty: make(map[common.Address]struct{}),
logs: make(map[common.Hash][]*types.Log),
preimages: make(map[common.Hash][]byte),
journal: newJournal(),
}, nil
}增删改和查询账户信息(状态数据)
创建账户。账户使用地址来标记,所以创建账户的时候要传入地址。如果当前的地址已经代表了一个账户,再执行创建账户,会创建1个新的空账户,然后把旧账户的余额,设置到新的账户,其他账户信息比如Nonce、Code等都设置为初始值了。
// CreateAccount explicitly creates a state object. If a state object with the address
// already exists the balance is carried over to the new account.
//
// CreateAccount is called during the EVM CREATE operation. The situation might arise that
// a contract does the following:
//
// 1. sends funds to sha(account ++ (nonce + 1))
// 2. tx_create(sha(account ++ nonce)) (note that this gets the address of 1)
//
// Carrying over the balance ensures that Ether doesn't disappear.
// 创建一个新的空账户,如果存在该地址的旧账户,则把旧地址中的余额,放到新账户中
func (self *StateDB) CreateAccount(addr common.Address) {
new, prev := self.createObject(addr)
if prev != nil {
new.setBalance(prev.data.Balance)
}
}
// createObject creates a new state object. If there is an existing account with
// the given address, it is overwritten and returned as the second return value.
// 创建一个stateObject,对账户数据进行初始化,然后记录日志
func (self *StateDB) createObject(addr common.Address) (newobj, prev *stateObject) {
prev = self.getStateObject(addr)
newobj = newObject(self, addr, Account{})
newobj.setNonce(0) // sets the object to dirty
if prev == nil {
self.journal.append(createObjectChange{account: &addr})
} else {
self.journal.append(resetObjectChange{prev: prev})
}
self.setStateObject(newobj)
return newobj, prev
}查询账户。getStateObject入参是账户地址,先查询缓存中是否存在账户,没有的话,再从trie中读取。有一点需要注意:trie中实际保存的stateObject中的Account数据,从trie中获取到Account信息后,然后再合成stateObject,它通常被查询账户数据的函数所使用。
GetOrNewStateObject是先查询一下stateObject,如果不存在则创建一个新的。通常是被Set系列函数在更新状态数据的时候使用。
// Retrieve a state object given by the address. Returns nil if not found.
// stateDB中使用trie保存addr到stateObject的映射,stateObject中保存key到value的映射
// 先从stateObjects中读取,否则从Trie读取Account,然后创建stateObject,存到stateObjects
func (self *StateDB) getStateObject(addr common.Address) (stateObject *stateObject) {
// Prefer 'live' objects.
if obj := self.stateObjects[addr]; obj != nil {
if obj.deleted {
return nil
}
return obj
}
// Load the object from the database.
enc, err := self.trie.TryGet(addr[:])
if len(enc) == 0 {
self.setError(err)
return nil
}
// trie中实际实际保存的是Account
var data Account
if err := rlp.DecodeBytes(enc, &data); err != nil {
log.Error("Failed to decode state object", "addr", addr, "err", err)
return nil
}
// Insert into the live set.
obj := newObject(self, addr, data)
self.setStateObject(obj)
return obj
}
// Retrieve a state object or create a new state object if nil.
// 获取stateObject,不存在则创建
func (self *StateDB) GetOrNewStateObject(addr common.Address) *stateObject {
stateObject := self.getStateObject(addr)
if stateObject == nil || stateObject.deleted {
stateObject, _ = self.createObject(addr)
}
return stateObject
}更新状态数据。stateObject的修改,修改后都暂存在stateDB.stateObjects中,当执行updateStateObject的时候,是把stateOject进行RLP编码,然后存到stateDB.trie中。
tire中实际保存的是stateObject的Account的RLP编码。因为stateObject实现了EncodeRLP函数,在RLP执行编码的时候,会调用该函数对stateObject进行编码,该函数实际只对state.data进行了编码。
// updateStateObject writes the given object to the trie.
// 把对象RLP编码,然后写到trie
func (self *StateDB) updateStateObject(stateObject *stateObject) {
addr := stateObject.Address()
data, err := rlp.EncodeToBytes(stateObject)
if err != nil {
panic(fmt.Errorf("can't encode object at %x: %v", addr[:], err))
}
self.setError(self.trie.TryUpdate(addr[:], data))
}
// EncodeRLP implements rlp.Encoder.
func (c *stateObject) EncodeRLP(w io.Writer) error {
return rlp.Encode(w, c.data)
}更新状态数据,就是一些列的Set函数了,这里就不讲了。
Finalise和Commit
Finalise和Commit是和存储过程紧密关联的2个函数,Finalise代表修改过的状态已经进入“终态”,Commit代表所有的状态都写入到数据库。我们使用下面这个图介绍一下。
- Finalise会把stateObjects写入到trie,并且计算trie的树根,但trie本身的所有节点,还在trie(trie暂时保存在内存)中,没有写入到trie数据库中。
- Commit要比Finalise深一步,它会把trie的所有节点写入到trie的数据库中,然后还会使用传入的回调函数处理trie的叶子节点。
我们再结合代码,看Finalise和Commit实现上的差异。Finalise处理的journal中标记为dirty的对象,不处理stateObjectsDirty中的对象,对于自杀的对象和空的对象,要把它们删除对象,降低trie的存储。然后,每向trie里写入1个对象,就会更新一次trie的根,然后才把对象加入到stateObjectsDirty,最后清空journal,因为这些journal已经过时了。
Commit会把journal中所有标记的对象加入到stateObjectsDirty,然后清空自杀和空的对象,把修改的对象写入到trie,把对象trie写入到数据库,最后把自己的trie写入到数据库。
// Finalise finalises the state by removing the self destructed objects
// and clears the journal as well as the refunds.
// 最终化数据库,遍历的日志中标记为dirty的账户,删除部分自杀、或空的数据,然后把数据写入存储trie,然后更新root,但每个对象都没有commit
func (s *StateDB) Finalise(deleteEmptyObjects bool) {
// 只处理journal中标记为dirty的对象,不处理stateObjectsDirty中的对象
for addr := range s.journal.dirties {
stateObject, exist := s.stateObjects[addr]
if !exist {
// ripeMD is 'touched' at block 1714175, in tx 0x1237f737031e40bcde4a8b7e717b2d15e3ecadfe49bb1bbc71ee9deb09c6fcf2
// That tx goes out of gas, and although the notion of 'touched' does not exist there, the
// touch-event will still be recorded in the journal. Since ripeMD is a special snowflake,
// it will persist in the journal even though the journal is reverted. In this special circumstance,
// it may exist in `s.journal.dirties` but not in `s.stateObjects`.
// Thus, we can safely ignore it http://lessisbetter.site/2018/06/22/ethereum-code-statedb/
continue
}
if stateObject.suicided || (deleteEmptyObjects && stateObject.empty()) {
s.deleteStateObject(stateObject)
} else {
// 把对象数据写入到storage trie,并获取新的root
stateObject.updateRoot(s.db)
s.updateStateObject(stateObject)
}
// 加入到stateObjectsDirty
s.stateObjectsDirty[addr] = struct{}{}
}
// Invalidate journal because reverting across transactions is not allowed.
// 清空journal,没法再回滚了
s.clearJournalAndRefund()
}
// 清空journal,revision,不能再回滚
func (s *StateDB) clearJournalAndRefund() {
s.journal = newJournal()
s.validRevisions = s.validRevisions[:0]
s.refund = 0
}
// Commit writes the state to the underlying in-memory trie database.
// 把数据写入trie数据库,与Finalize不同,这里处理的是Dirty的对象
func (s *StateDB) Commit(deleteEmptyObjects bool) (root common.Hash, err error) {
// 清空journal无法再回滚
defer s.clearJournalAndRefund()
// 把journal中dirties的对象,加入到stateObjectsDirty
for addr := range s.journal.dirties {
s.stateObjectsDirty[addr] = struct{}{}
}
// Commit objects to the trie.
// 遍历所有活动/修改过的对象
for addr, stateObject := range s.stateObjects {
_, isDirty := s.stateObjectsDirty[addr]
switch {
case stateObject.suicided || (isDirty && deleteEmptyObjects && stateObject.empty()):
// If the object has been removed, don't bother syncing it
// and just mark it for deletion in the trie.
s.deleteStateObject(stateObject)
case isDirty:
// Write any contract code associated with the state object
// 把修改过的合约代码写到数据库,这个用法高级,直接把数据库拿过来,插进去
// 注意:这里写入的DB是stateDB的数据库,因为stateObject的Trie只保存Account信息
if stateObject.code != nil && stateObject.dirtyCode {
s.db.TrieDB().Insert(common.BytesToHash(stateObject.CodeHash()), stateObject.code)
stateObject.dirtyCode = false
}
// Write any storage changes in the state object to its storage trie.
// 对象提交:把任何改变的存储数据写到数据库
if err := stateObject.CommitTrie(s.db); err != nil {
return common.Hash{}, err
}
// Update the object in the main account trie.
// 把修改后的对象,编码后写入到stateDB的trie中
s.updateStateObject(stateObject)
}
delete(s.stateObjectsDirty, addr)
}
// Write trie changes.
// stateDB的提交
root, err = s.trie.Commit(func(leaf []byte, parent common.Hash) error {
var account Account
if err := rlp.DecodeBytes(leaf, &account); err != nil {
return nil
}
// 如果叶子节点的trie不空,则trie关联到父节点
if account.Root != emptyState {
// reference的功能还没搞懂
s.db.TrieDB().Reference(account.Root, parent)
}
// 如果叶子节点的code不空(合约账户),则把code关联到父节点
code := common.BytesToHash(account.CodeHash)
if code != emptyCode {
s.db.TrieDB().Reference(code, parent)
}
return nil
})
log.Debug("Trie cache stats after commit", "misses", trie.CacheMisses(), "unloads", trie.CacheUnloads())
return root, err
}关于Commit保存对象信息的时候,还有1个重点关注:stateObject.Code并没有保存在stateObject.trie中,而是保存在stateDB.trie中。所以调用stateObject.Code获取合约代码的时候,实际传入的是stateDB.db,cachingDB.ContractCode实际也不使用合约的地址,因为(CodeHash, Code)本身就是作为KV存放在Trie中。
// Code returns the contract code associated with this object, if any.
// 从db读取合约代码,db实际是stateDB.db
func (self *stateObject) Code(db Database) []byte {
if self.code != nil {
return self.code
}
if bytes.Equal(self.CodeHash(), emptyCodeHash) {
return nil
}
code, err := db.ContractCode(self.addrHash, common.BytesToHash(self.CodeHash()))
if err != nil {
self.setError(fmt.Errorf("can't load code hash %x: %v", self.CodeHash(), err))
}
self.code = code
return code
}
// ContractCode retrieves a particular contract's code.
// 合约账户的code
func (db *cachingDB) ContractCode(addrHash, codeHash common.Hash) ([]byte, error) {
//addrHash无用
code, err := db.db.Node(codeHash)
if err == nil {
db.codeSizeCache.Add(codeHash, len(code))
}
return code, err
}日志和回滚
以太坊使用记录每一步状态的变化来支持回滚,每一步变化就是日志。假如从状态A转移到状态B,需要经过8步,在第1不的时候创建了snapshot,执行到第6步的时候出现了错误,回滚操作就是:把操作2,3,4,5步之前的数据,以5,4,3,2的顺序设置回去。

// Snapshot returns an identifier for the current revision of the state.
// 快照只是一个id,把id和日志的长度关联起来,存到Revisions中
// EVM在执行在运行一个交易时,在修改state之前,创建快照,出现错误,则回滚
func (self *StateDB) Snapshot() int {
id := self.nextRevisionId
self.nextRevisionId++
self.validRevisions = append(self.validRevisions, revision{id, self.journal.length()})
return id
}
// RevertToSnapshot reverts all state changes made since the given revision.
// 回滚到指定vision/快照
func (self *StateDB) RevertToSnapshot(revid int) {
// Find the snapshot in the stack of valid snapshots.
idx := sort.Search(len(self.validRevisions), func(i int) bool {
return self.validRevisions[i].id >= revid
})
if idx == len(self.validRevisions) || self.validRevisions[idx].id != revid {
panic(fmt.Errorf("revision id %v cannot be reverted", revid))
}
snapshot := self.validRevisions[idx].journalIndex
// Replay the journal to undo changes and remove invalidated snapshots
// 反操作后续的操作,达到回滚的目的
self.journal.revert(self, snapshot)
self.validRevisions = self.validRevisions[:idx]
}在journal.go中有更多的日志操作,以及每种类型操作需要记录的数据。
转载自:https://lessisbetter.site/2018/06/22/ethereum-code-statedb/
以太坊源码分析:共识(3)PoW
前言
Ethash实现了PoW,PoW的精妙在于通过一个随机数确定,矿工确实做了大量的工作,并且是没有办法作弊的。接下来将介绍:
- Ethash的挖矿本质。
- Ethash是如何挖矿的。
- 如何验证Ethash的随机数。
Ethash的挖矿本质
挖矿的本质是找到一个随机数,证明自己做了很多工作(计算)。在Ethash中,该随机数称为Nonce,它需要满足一个公式:
Rand(hash, nonce) ≤ MaxValue / Difficulty参数解释
- hash:去除区块头中Nonce、MixDigest生成的哈希值,见
HashNoNonce()。 - nonce:待寻找的符合条件的随机数。
- MaxValue:固定值2^256,生成的哈希值的最大取值。
- Difficulty:挖矿难度。
- Rand():使用hash和nonce生成一个哈希值,这其中包含了很多哈希运算。
以上参数中,在得到区块头的hash之后,只有nonce是未知的。公式的含义是,使用hash和nonce生成的哈希值必须落在合法的区间
利用下图介绍一下,Rand()函数结果取值范围是[0, MaxValue],但只有计算出的哈希值在[0, MaxValue / Difficulty]内,才是符合条件的哈希值,进而该Nonce才是符合条件的,否则只能再去寻找下一个Nonce。
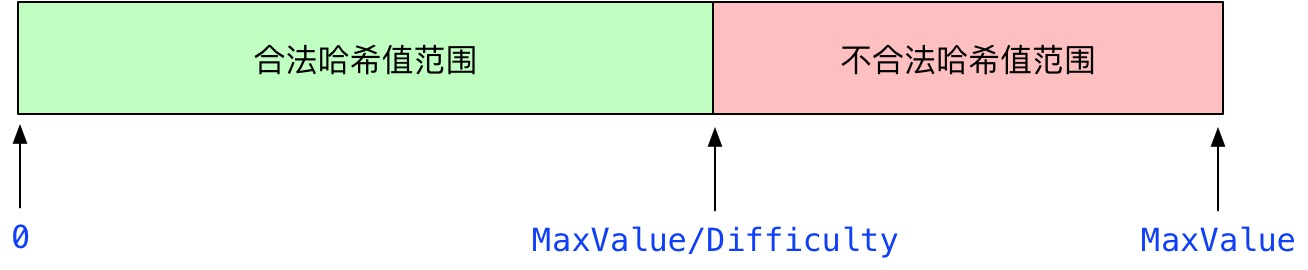
以太坊可以通过调整Difficulty来调节当前挖矿的难度,Difficulty越大,挖矿的难度越大。当Difficulty越大时, MaxValue / Difficulty越小,合法的哈希值范围越小,造成挖矿难度增加。
哈希值满足条件的概率是 p = (MaxValue / Difficulty) / MaxValue = 1 / Difficulty,矿工需要进行1 / p = Difficulty次的判断,才有可能找到一个符合条件的Nonce,当前以太坊难度为3241847139727150
为什么PoW需要做那么多的运算,而不是通过公式反推,计算出满足条件的结果(Nonce)?
PoW可以表示为许多数学公式的合集,每次运算的入参:前一个区块头的哈希,当前高度的DataSet,目标值Nonce,这些数学公式都是哈希函数,哈希函数的特性就是不可逆性,不能通过摘要获得输入数据。虽然,前一个区块头的哈希和当前高度的DataSet是固定的,但由于哈希函数的不可逆性,依然无法倒推出Nonce,只能随机的产生Nonce,或累加Nonce,并不断的重试,直到找到符合条件的Nonce。
如何挖矿
Ethash挖矿的主要思想是,开启多个线程去寻找符合条件的Nonce,给每个线程分配一个随机数,作为本线程的Nonce的初始值,然后每个线程判断当前的Nonce是否符合上面的公式,如果不符合,则把Nonce加1,再次进行判断,这样不定的迭代下去,直到找到一个符合条件的Nonce,或者挖矿被叫停。
接下来介绍挖矿的几个主要函数的实现,它们是:
- 挖矿的入口Seal函数。
- 挖矿函数mine函数。
- 挖矿需要的数据cache和dataset。
- Rand()函数的实现hashimotoFull和hashimoto。
挖矿入口Seal()
Seal是引擎的挖矿入口函数,它是管理岗位,负责管理挖矿的线程。它发起多个线程执行Ethash.mine进行并行挖矿,当要更新或者停止的时候,重新启动或停止这些线程。
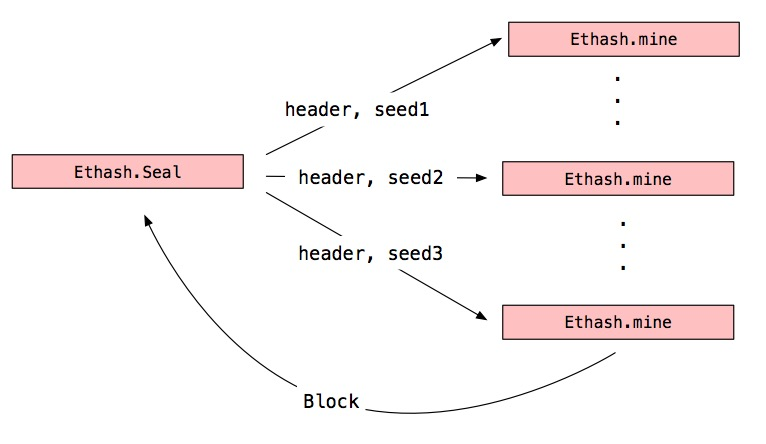
挖矿函数mine()
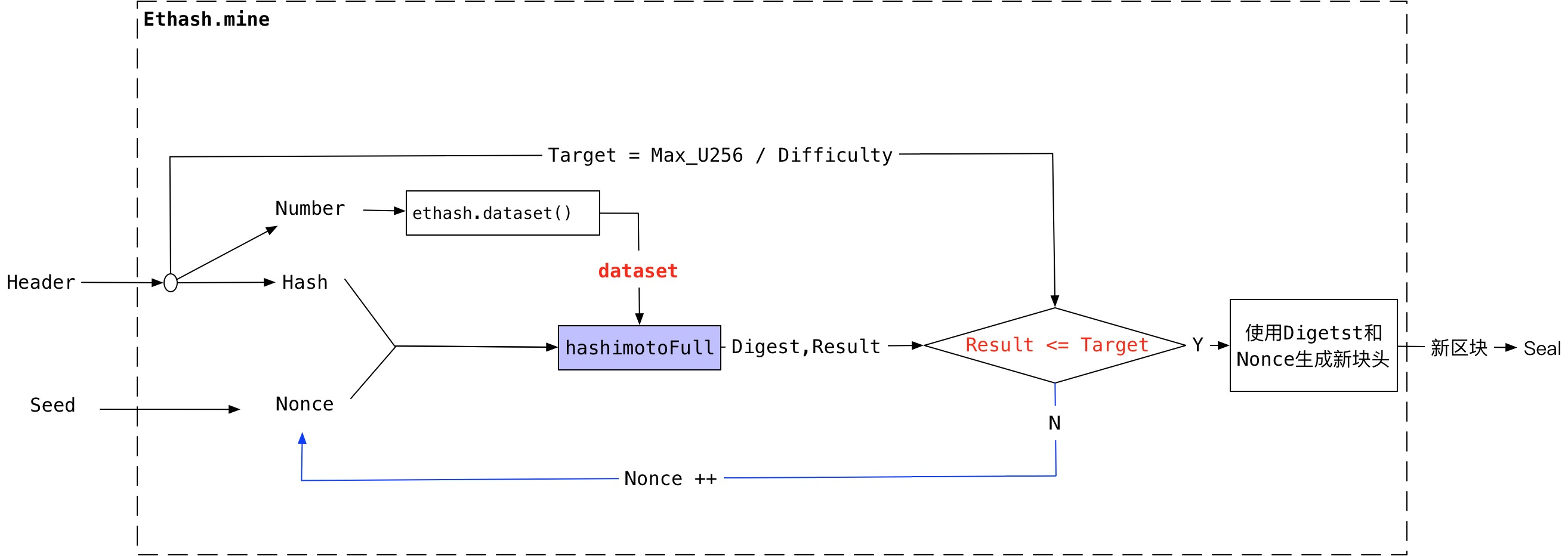
mine函数负责挖矿。Seal在启动每一个mine的时候,给它分配了一个seed,mine会把它作为Nonce的初始值,然后生成本高度使用的dataset,然后把dataset, hash, nonce传递给hashimotoFull函数,这个函数可以认为是原理介绍中的Rand随机函数,他会生成哈希值Result,当Result <= Target的时候,说明哈希值落在符合条件的区间了,mine找到了符合条件的Nonce,使用Digest和nonce组成新的区块后,发送给Seal,否则验证下一个Nonce是否是符合条件的
挖矿需要的数据cache和dataset
dataset用来生成Result,而cache用来生成dataset。至于如何使用dataset生成Result在hashimoto()中讲述,本节介绍如何生成dataset。
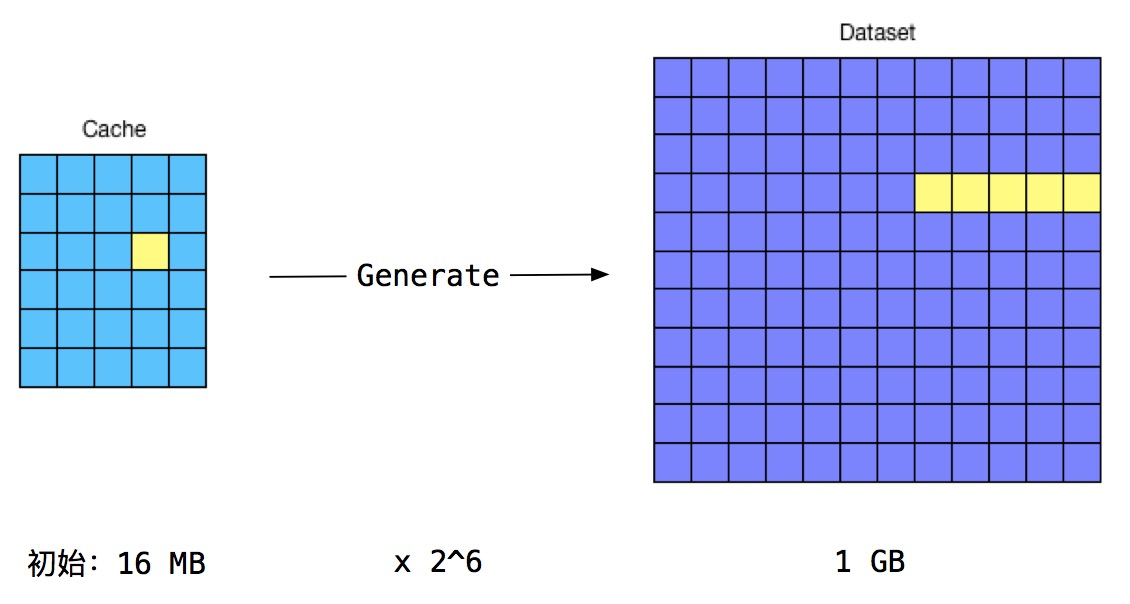
dataset和cache中存放的都是伪随机数,每个epoch的区块使用相同的cache和dataset,并且dataset需要暂用大量的内存。刚开始时cache是16MB,dataset是1GB,但每个epoch它们就会增大一次,它们的大小分别定义在datasetSizes和cacheSizes,dataset每次增长8MB,最大能达到16GB,所以挖矿的节点必须有足够大的内存。
使用cache生成dataset。使用cache的部分数据,进行哈希和异或运算,就能生成一组dataset的item,比如下图中的cache中黄色块,能生成dataset中的黄色块,最后把这些Item拼起来就生成了完整的Dataset,完成该功能的函数是generateDataset。
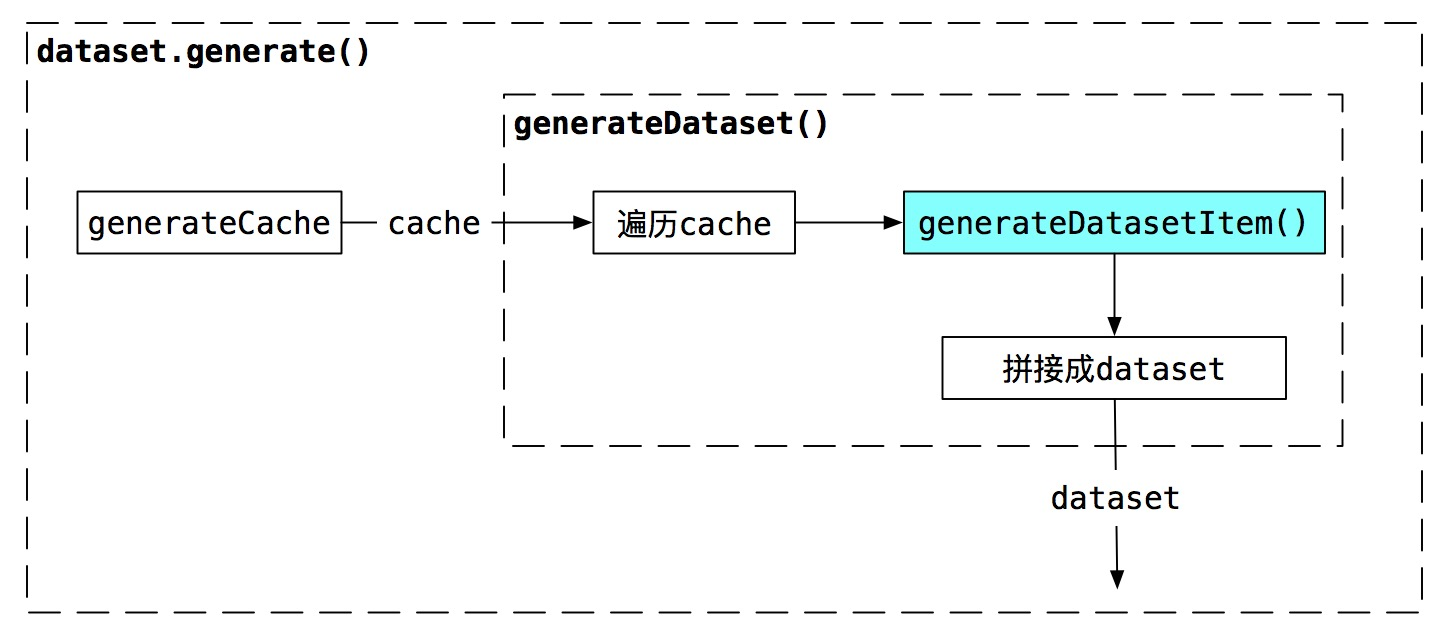
dataset.generate()是dataset的生成函数,该函数只执行一次,先使用generateCache()生成cache,再将cache作为generateDataset()的入参生成dataset,其中需要重点关注的是generateDatasetItem(),该函数是根据部分cache,生成一组dataset item,验证PoW的nonce的时候,也需要使用该函数。
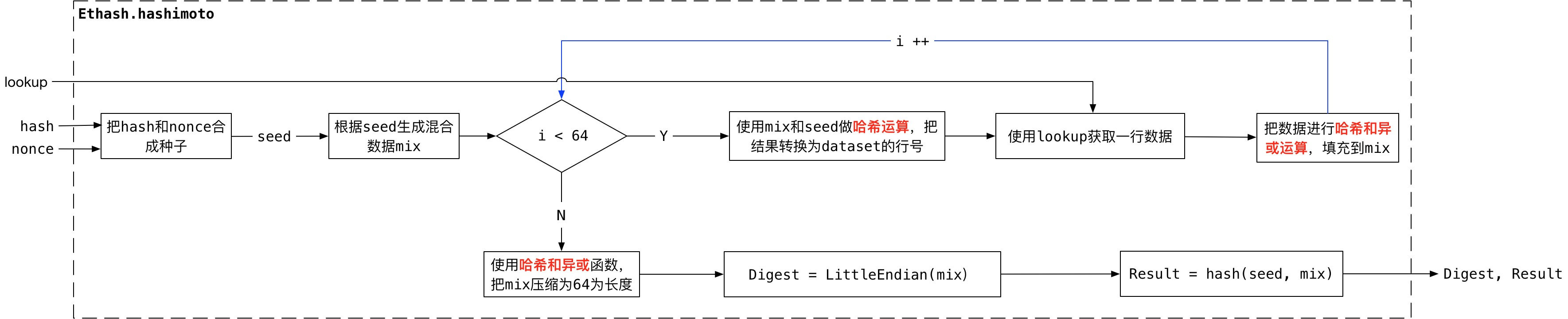
Rand()的实现hashimotoFull()和hashimoto()
hashimotoFull功能是使用dataset、hash和nonce生成Digest和Result。它创建一个获取dataset部分数据的lookup函数,该函数能够返回连续的64字节dataset中的数据,然后把lookup函数、hash和nonce传递给hashimoto。

hashimoto的功能是根据hash和nonce,以及lookup函数生成Digest和Result,lookup函数能够返回64字节的数据就行。它把hash和nonce合成种子,然后根据种子生成混合的数据mix,然后进入一个循环,使用mix和seed获得dataset的行号,使用lookup获取指定行的数据,然后把数据混合到mix中,混合的方式是使用哈希和异或运算,循环结束后再使用哈希和异或函数把mix压缩为64字节,把mix转为小端模式就得到了Digest,把seed和mix进行hash运算得到Result。
如何验证
PoW的验证是证明出块人确实进行了大量的哈希计算。Ethash验证区块头中的Nonce和MixDigest是否合法,如果验证通过,则认为出块人确实进行了大量的哈希运算。验证方式是确定区块头中的Nonce是否符合公式,并且区块头中的MixDigest是否与使用此Nonce计算出的是否相同。
验证与挖矿相比,简直是毫不费力,因为:
- 时间节省。验证只进行1次hashimoto运算,而挖矿进行大约Difficulty次。
- 空间节省。验证只需要cache,不需要dataset,也就不需要计算庞大的dataset,因此不挖矿的验证节点,不需要很高的配置。
接下来介绍验证函数VerifySeal(),以及根据cache生成Digest和Result的hashimotoLight()。
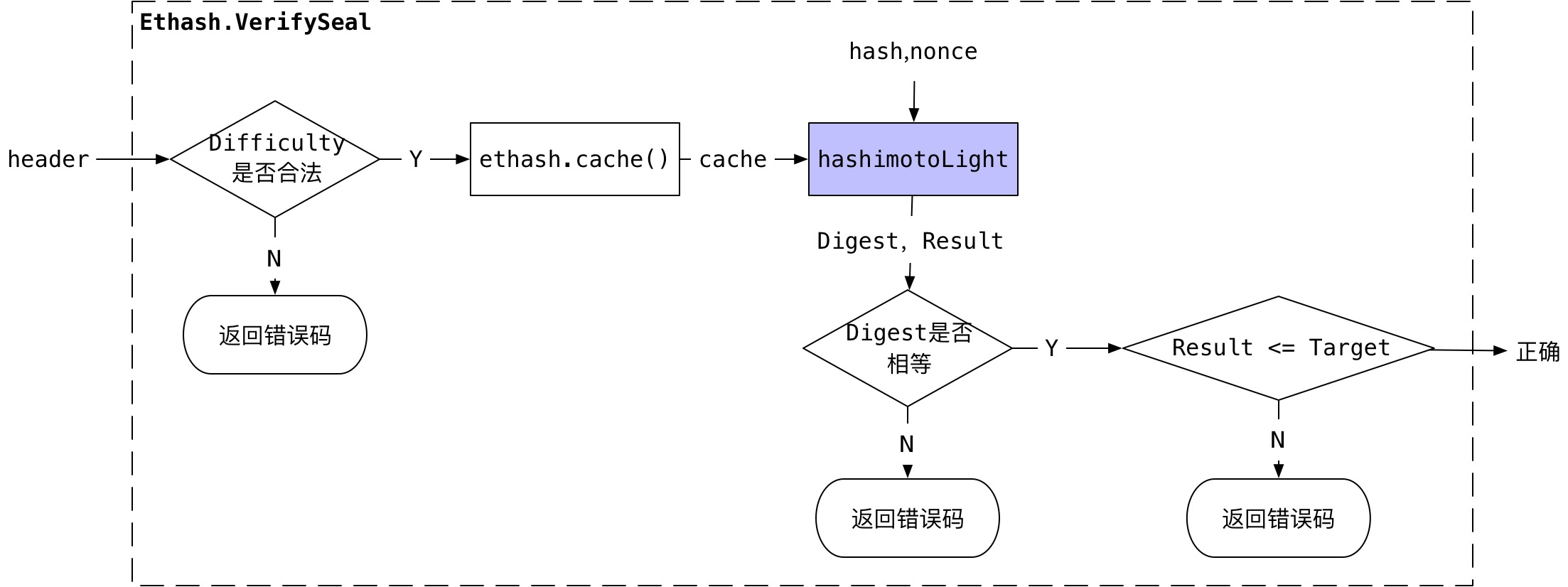
验证函数VerifySeal
Ethash.VerifySeal实现PoW验证功能。首先先判断区块中的Difficulty是否匹配,然后生成(获取)当前区块高度的cache,把cache和nonce传递给hashimotoLight,该函数能根据cache, hash, nonce生成Digest和Result,然后校验Digest是否匹配以及Result是否符合条件。
hashimotoLight函数
hashimotoLight使用cache, hash, nonce生成Digest和Result。生成Digest和Result只需要部分的dataset数据,而这些部分dataset数据时可以通过cache生成,因此也就不需要完整的dataset。它把generateDatasetItem函数封装成了获取部分dataset数据的lookup函数,然后传递给hashimoto计算出Digest和Result。

FAQ
- Q:每30000个块使用同一个dataset,那可以提前挖出一些合法的Nonce?
A:不行。提前挖去Nonce,意味着还不知道区块头的hash,因此无法生成合法的Nonce。 - Q:能否根据符合条件的哈希值,反推出Nonce呢?
A:不行。因为哈希运算具有不可逆性,不能根据摘要反推出明文,同理根据哈希值也无法推出Nonce。
转载自:https://lessisbetter.site/2018/06/22/ethereum-code-consensus-3/