在 Solana 上实现 SOL 转账及构建支付分配器
本教程将介绍 Solana Anchor 程序如何在交易中转移 SOL 的机制。
与以太坊不同,在以太坊中,钱包通过 msg.value 指定交易的一部分并“推送” ETH 到合约,而 Solana 程序则是从钱包“拉取” Solana。
因此,没有“可支付”函数或“msg.value”这样的概念。
下面我们创建了一个新的 anchor 项目,名为 sol_splitter,并放置了将 SOL 从发送者转移到接收者的 Rust 代码。
当然,如果发送者直接发送 SOL,而不是通过程序来完成,这样会更高效,但我们想要说明的是如何做到这一点:
use anchor_lang::prelude::*;
use anchor_lang::system_program;
declare_id!("9qnGx9FgLensJQy1hSB4b8TaRae6oWuNDveUrxoYatr7");
#[program]
pub mod sol_splitter {
use super::*;
pub fn send_sol(ctx: Context<SendSol>, amount: u64) -> Result<()> {
let cpi_context = CpiContext::new(
ctx.accounts.system_program.to_account_info(),
system_program::Transfer {
from: ctx.accounts.signer.to_account_info(),
to: ctx.accounts.recipient.to_account_info(),
}
);
let res = system_program::transfer(cpi_context, amount);
if res.is_ok() {
return Ok(());
} else {
return err!(Errors::TransferFailed);
}
}
}
#[error_code]
pub enum Errors {
#[msg("transfer failed")]
TransferFailed,
}
#[derive(Accounts)]
pub struct SendSol<'info> {
/// CHECK: we do not read or write the data of this account
#[account(mut)]
recipient: UncheckedAccount<'info>,
system_program: Program<'info, System>,
#[account(mut)]
signer: Signer<'info>,
}这里有很多内容需要解释。
引入 CPI:跨程序调用
在以太坊中,转移 ETH 只需在 msg.value 字段中指定一个值。在 Solana 中,一个名为 system program 的内置程序将 SOL 从一个账户转移到另一个账户。这就是为什么在我们初始化账户时,它不断出现并且需要支付费用来初始化它们。
你可以大致将系统程序视为以太坊中的预编译。想象一下,它的行为有点像内置于协议中的 ERC-20 代币,用作原生货币。它有一个名为 transfer 的公共函数。
CPI 交易的上下文
每当调用 Solana 程序函数时,必须提供一个 Context。该 Context 包含程序将要交互的所有账户。
调用系统程序没有什么不同。系统程序需要一个 Context,其中包含 from 和 to 账户。转移的 amount 作为“常规”参数传递——它不是 Context 的一部分(因为“amount”不是一个账户,它只是一个值)。
现在我们可以解释下面的代码片段:
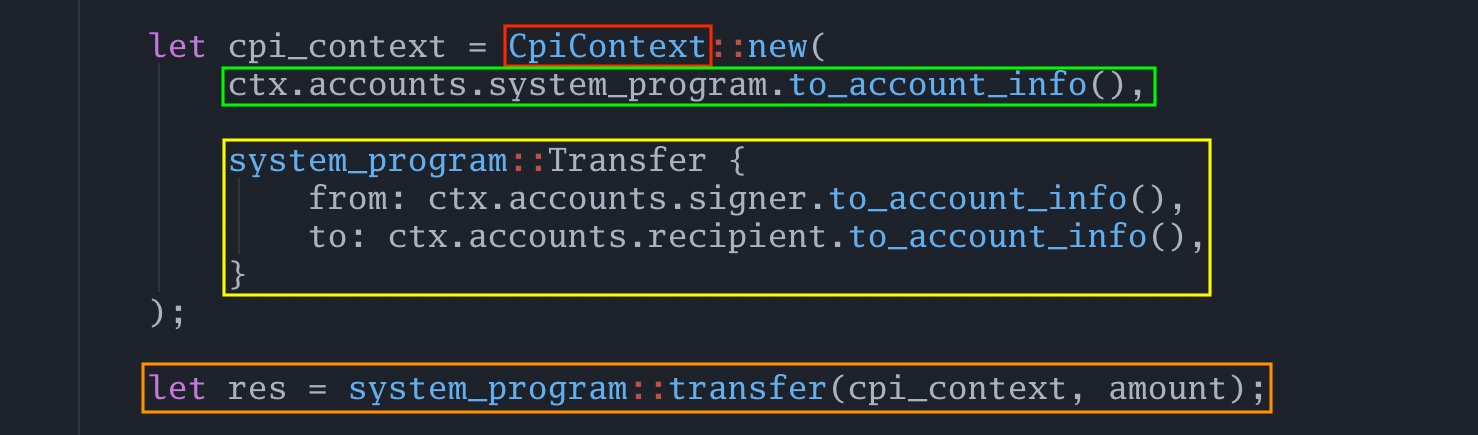
我们正在构建一个新的 CpiContext,它将我们要调用的程序作为第一个参数(绿色框),以及将作为该交易一部分的账户(黄色框)。参数 amount 在这里没有提供,因为 amount 不是一个账户。
现在我们已经构建了 cpi_context,可以在指定金额的同时对系统程序进行跨程序调用(橙色框)。
这返回一个 Result<()> 类型,就像我们 Anchor 程序上的公共函数一样。
不要忽视跨程序调用的返回值。
要检查跨程序调用是否成功,我们只需检查返回值是否为 Ok。Rust 通过 is_ok() 方法使这变得简单:
let res = system_program::transfer(cpi_context, amount);
if res.is_ok() {
return Ok(());
} else {
return err!(Errors::TransferFailed);
}
}
}
#[error_code]
pub enum Errors {
#[msg("transfer failed")]
TransferFailed,
}只有签名者可以是“from”
如果你调用系统程序时 from 是一个不是 Signer 的账户,那么系统程序将拒绝该调用。没有签名,系统程序无法知道你是否授权了该调用。
TypeScript 代码:
import * as anchor from "@coral-xyz/anchor";
import { Program } from "@coral-xyz/anchor";
import { SolSplitter } from "../target/types/sol_splitter";
describe("sol_splitter", () => {
// Configure the client to use the local cluster.
anchor.setProvider(anchor.AnchorProvider.env());
const program = anchor.workspace.SolSplitter as Program<SolSplitter>;
async function printAccountBalance(account) {
const balance = await anchor.getProvider().connection.getBalance(account);
console.log(`${account} has ${balance / anchor.web3.LAMPORTS_PER_SOL} SOL`);
}
it("Transmit SOL", async () => {
// generate a new wallet
const recipient = anchor.web3.Keypair.generate();
await printAccountBalance(recipient.publicKey);
// send the account 1 SOL via the program
let amount = new anchor.BN(1 * anchor.web3.LAMPORTS_PER_SOL);
await program.methods.sendSol(amount)
.accounts({recipient: recipient.publicKey})
.rpc();
await printAccountBalance(recipient.publicKey);
});
});一些需要注意的事项:
- 我们创建了一个辅助函数
printAccountBalance来显示余额的前后 - 我们使用
anchor.web3.Keypair.generate()生成了接收者钱包 - 我们将 1 SOL 转移到新账户
当我们运行代码时,预期结果如下。打印语句是接收者地址的前后余额:

练习:构建一个 Solana 程序,将传入的 SOL 平均分配给两个接收者。你将无法通过函数参数来完成此操作,账户需要在 Context 结构中。
构建支付分割器:使用 remaining_accounts 处理任意数量的账户。
我们可以看到,如果我们想将 SOL 分配给多个账户,必须指定一个 Context 结构会显得相当笨拙:
#[derive(Accounts)]
pub struct SendSol<'info> {
/// CHECK: we do not read or write the data of this account
#[account(mut)]
recipient1: UncheckedAccount<'info>,
/// CHECK: we do not read or write the data of this account
#[account(mut)]
recipient2: UncheckedAccount<'info>,
/// CHECK: we do not read or write the data of this account
#[account(mut)]
recipient3: UncheckedAccount<'info>,
// ...
/// CHECK: we do not read or write the data of this account
#[account(mut)]
recipientn: UncheckedAccount<'info>,
system_program: Program<'info, System>,
#[account(mut)]
signer: Signer<'info>,
}为了解决这个问题,Anchor 在 Context 结构中添加了一个 remaining_accounts 字段。
下面的代码说明了如何使用这个特性:
use anchor_lang::prelude::*;
use anchor_lang::system_program;
declare_id!("9qnGx9FgLensJQy1hSB4b8TaRae6oWuNDveUrxoYatr7");
#[program]
pub mod sol_splitter {
use super::*;
// 'a, 'b, 'c 是 Rust 生命周期,暂时忽略它们
pub fn split_sol<'a, 'b, 'c, 'info>(
ctx: Context<'a, 'b, 'c, 'info, SplitSol<'info>>,
amount: u64,
) -> Result<()> {
let amount_each_gets = amount / ctx.remaining_accounts.len() as u64;
let system_program = &ctx.accounts.system_program;
// 注意关键字 `remaining_accounts`
for recipient in ctx.remaining_accounts {
let cpi_accounts = system_program::Transfer {
from: ctx.accounts.signer.to_account_info(),
to: recipient.to_account_info(),
};
let cpi_program = system_program.to_account_info();
let cpi_context = CpiContext::new(cpi_program, cpi_accounts);
let res = system_program::transfer(cpi_context, amount_each_gets);
if !res.is_ok() {
return err!(Errors::TransferFailed);
}
}
Ok(())
}
}
#[error_code]
pub enum Errors {
#[msg("transfer failed")]
TransferFailed,
}
#[derive(Accounts)]
pub struct SplitSol<'info> {
#[account(mut)]
signer: Signer<'info>,
system_program: Program<'info, System>,
}这是 TypeScript 代码:
import * as anchor from "@coral-xyz/anchor";
import { Program } from "@coral-xyz/anchor";
import { SolSplitter } from "../target/types/sol_splitter";
describe("sol_splitter", () => {
// 配置客户端以使用本地集群。
anchor.setProvider(anchor.AnchorProvider.env());
const program = anchor.workspace.SolSplitter as Program<SolSplitter>;
async function printAccountBalance(account) {
const balance = await anchor.getProvider().connection.getBalance(account);
console.log(`${account} has ${balance / anchor.web3.LAMPORTS_PER_SOL} SOL`);
}
it("Split SOL", async () => {
const recipient1 = anchor.web3.Keypair.generate();
const recipient2 = anchor.web3.Keypair.generate();
const recipient3 = anchor.web3.Keypair.generate();
await printAccountBalance(recipient1.publicKey);
await printAccountBalance(recipient2.publicKey);
await printAccountBalance(recipient3.publicKey);
const accountMeta1 = {pubkey: recipient1.publicKey, isWritable: true, isSigner: false};
const accountMeta2 = {pubkey: recipient2.publicKey, isWritable: true, isSigner: false};
const accountMeta3 = {pubkey: recipient3.publicKey, isWritable: true, isSigner: false};
let amount = new anchor.BN(1 * anchor.web3.LAMPORTS_PER_SOL);
await program.methods.splitSol(amount)
.remainingAccounts([accountMeta1, accountMeta2, accountMeta3])
.rpc();
await printAccountBalance(recipient1.publicKey);
await printAccountBalance(recipient2.publicKey);
await printAccountBalance(recipient3.publicKey);
});
});运行测试显示了之前和之后的余额:

这里是对 Rust 代码的一些评论:
Rust 生命周期
split_sol 的函数声明有一些奇怪的语法:
pub fn split_sol<'a, 'b, 'c, 'info>(
ctx: Context<'a, 'b, 'c, 'info, SplitSol<'info>>,
amount: u64,
) -> Result<()>'a、'b 和 'c 是 Rust 生命周期。Rust 生命周期是一个复杂的话题,我们暂时不想涉及。但简单来说,Rust 代码需要确保在循环 for recipient in ctx.remaining_accounts 中传入的资源在整个循环期间始终存在。
ctx.remaining_accounts
循环通过 for recipient in ctx.remaining_accounts 遍历。关键字 remaining_accounts 是 Anchor 机制,用于传递任意数量的账户,而不必在 Context 结构中创建一堆键。
在 TypeScript 测试中,我们可以像这样将 remaining_accounts 添加到事务中:
await program.methods.splitSol(amount)
.remainingAccounts([accountMeta1, accountMeta2, accountMeta3])
.rpc();