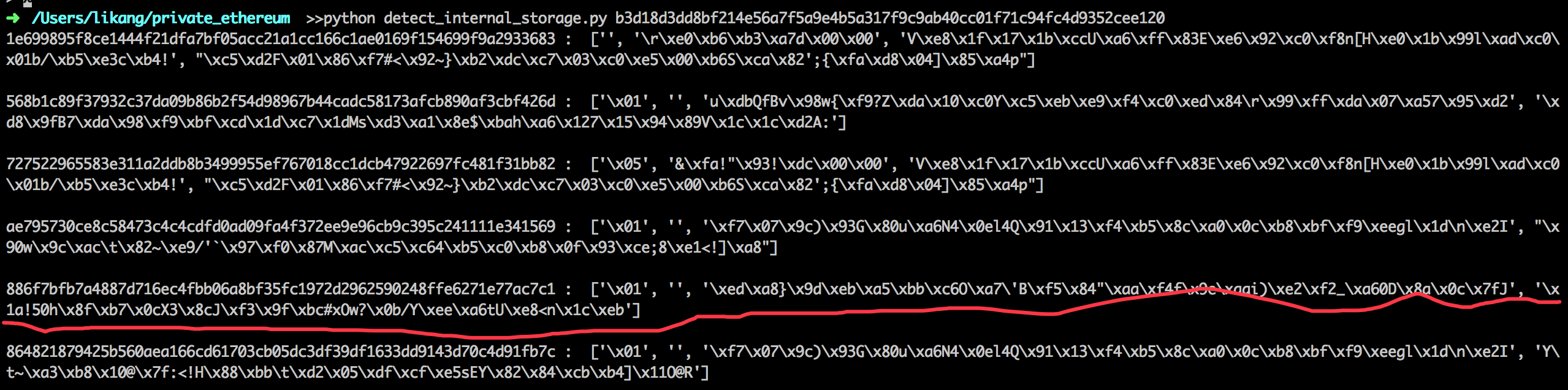
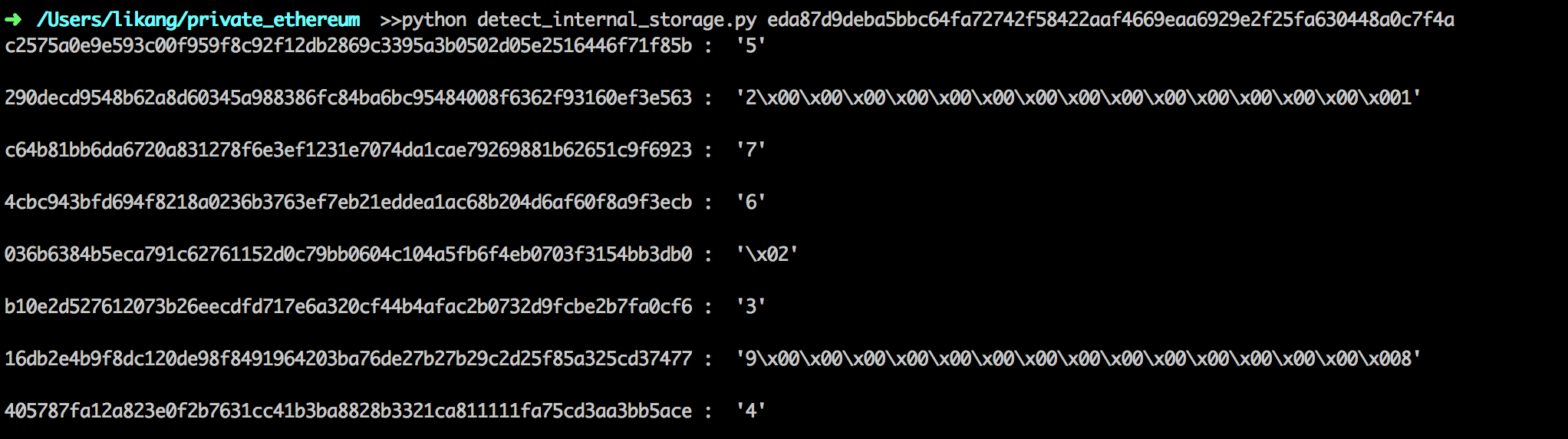
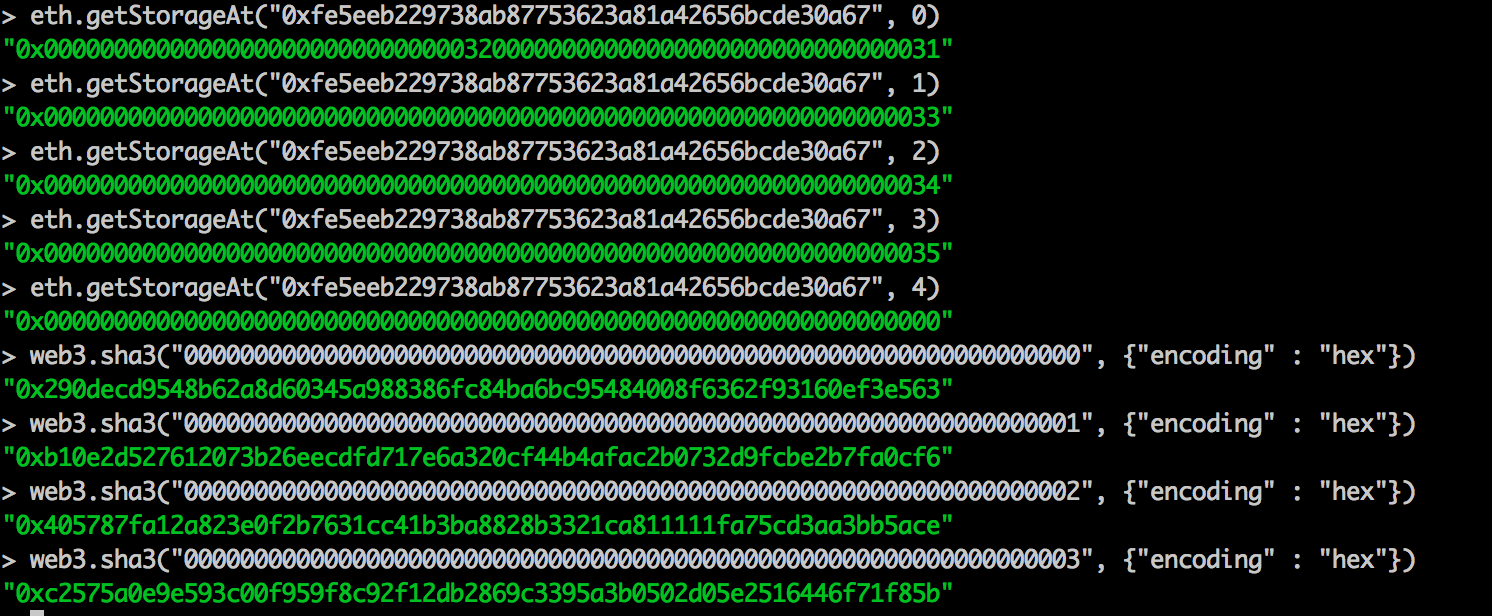
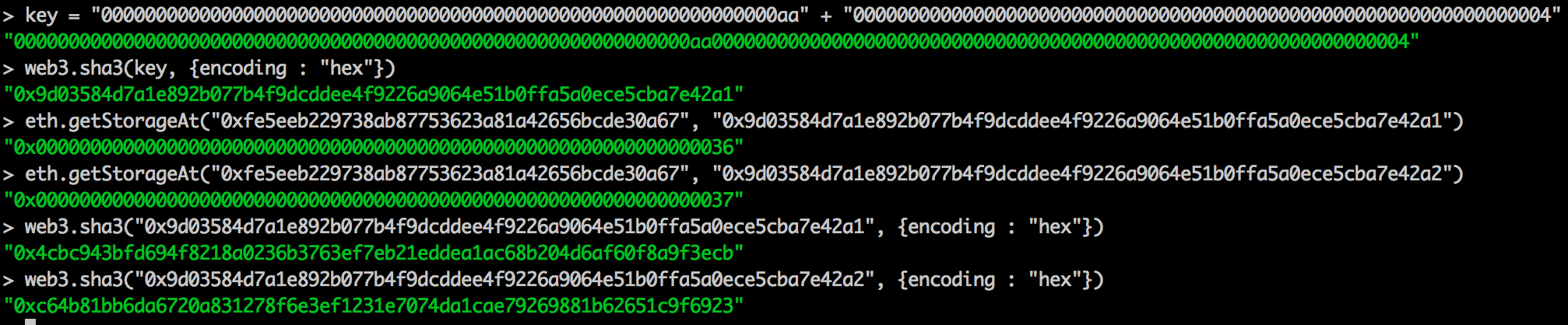
解释以太坊状态试图加深对以太坊区块链的了解。
介绍
这篇文章解释了以太坊状态树。复仇通常被称为“世态町ñ e”和使用原始数据存储到记录状态(账户)和交易。由于 state trie 是 Ethereum 的核心数据库,因此了解它以加深您对 Ethereum 的了解非常重要。我构建的内容是为了让你在逻辑上一步一步地理解。当我学习它时,很难深入理解,因为状态树有多种类型,并且每个状态树都彼此密切相关。我希望这篇文章可以帮助您轻松深入地了解 state try。本文按顺序涵盖以下主题。
- Merkle Patricia Trie
- World State Trie
- Transaction Trie
- Receipt Trie
- Account Storage Trie
Merkle Patricia Trie(基数树/帕特里夏树/前缀树)
Trie,也称为Radix Trie、Patricia Trie或Prefix Tree,是一种查找公共前缀最快、实现简单、占用内存小的数据结构。由于以太坊使用 Merkle Tree 将哈希高效地存储在块中,因此使用 Trie 作为数据存储的核心数据结构。以太坊使用“Modified Merkel Patricia Trie”,它是由 Merkle Tree、Patricia Tree(Trie) 和一些改进发明的。修改后的 Merkle Patricia Trie 作为以太坊尝试接收树、世界状态树、账户存储树和交易树中的主要数据结构。
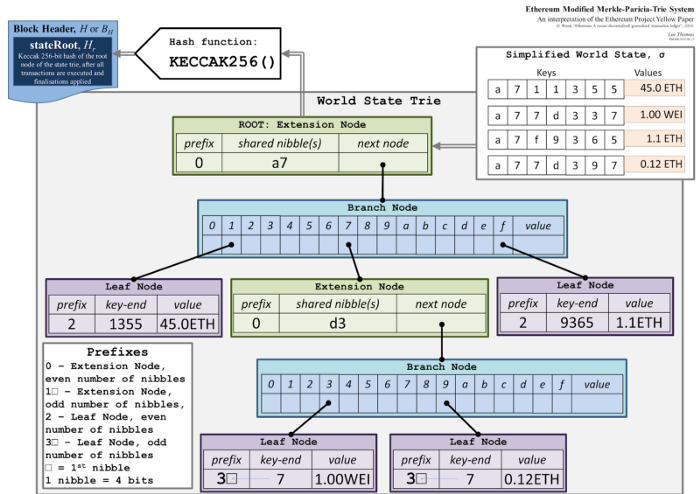
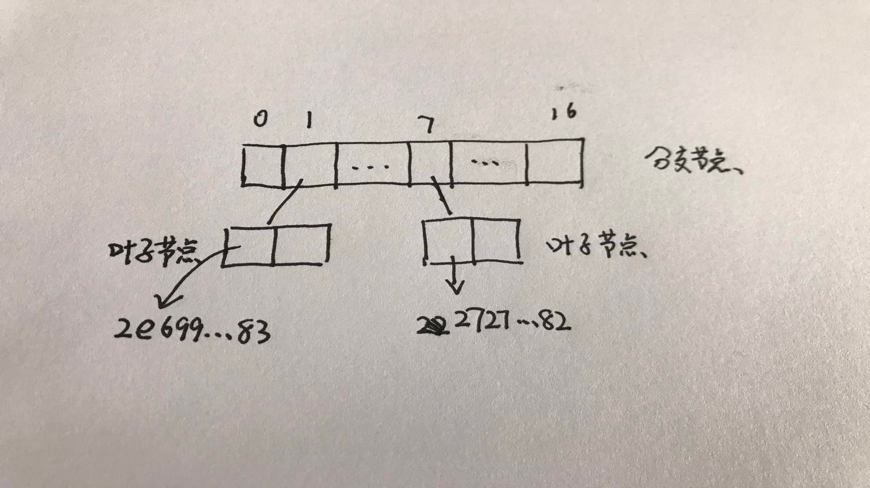
上图显示了 Merkel Patricia Trie 的结构。它主要由三种类型的节点组成:扩展节点、分支节点和叶节点。每个节点由其内容的 sha3 散列值决定,并将散列用作键。Go-ethereum 使用 levelDB,parity 使用 RocksDB 存储状态。如果您想了解更深入的内容,请参阅“修改后的 Merkle Patricia Trie — 以太坊如何保存状态”。
状态树结构
在开始解释每个状态树之前,让我解释一下以太坊状态树的整个架构。如前所述,状态树有四种类型:世界状态树、交易树、交易收据树和账户存储树。每个状态树都是用 Merkle Patricia Trie 构建的,只有根节点(状态树的顶部节点)存储在块中以备用存储。您可以在下图中看到整个架构。
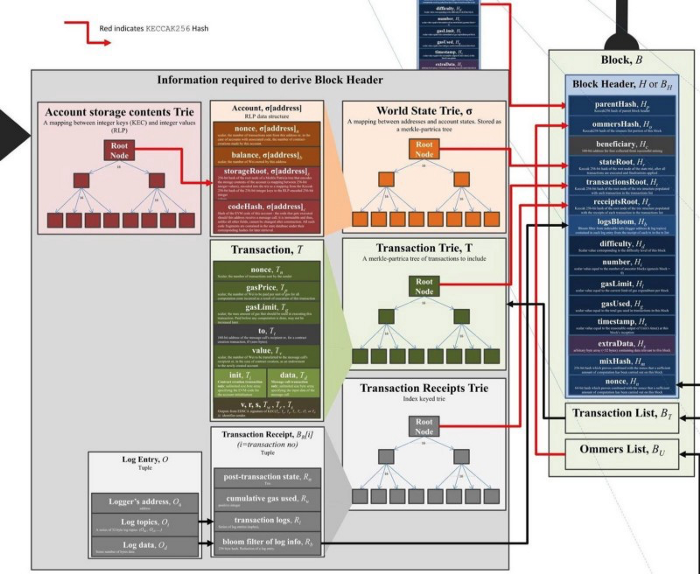
如您所见,三个主要的状态尝试:世界状态树、交易树和接收树被存储在块中。并且,账户存储树(account storage contents trie)在世界状态树中构造叶节点。
世界状态树(State Trie,全局状态树)
世界状态树是地址和帐户状态之间的映射。它可以被视为一个全局状态,通过事务执行不断更新。以太坊网络是一个分散的计算机,状态树被认为是硬盘驱动器。所有关于账户的信息都存储在世界状态树中,您可以通过查询来检索信息。世界状态树与账户存储树关系密切,因为它有“storageRoot”字段,指向账户存储树中的根节点。
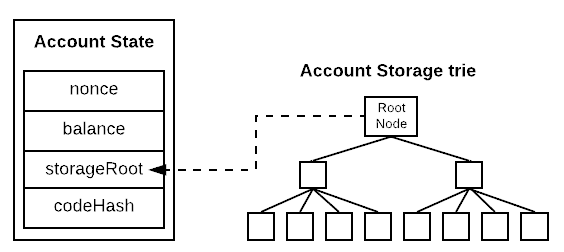
帐户存储树
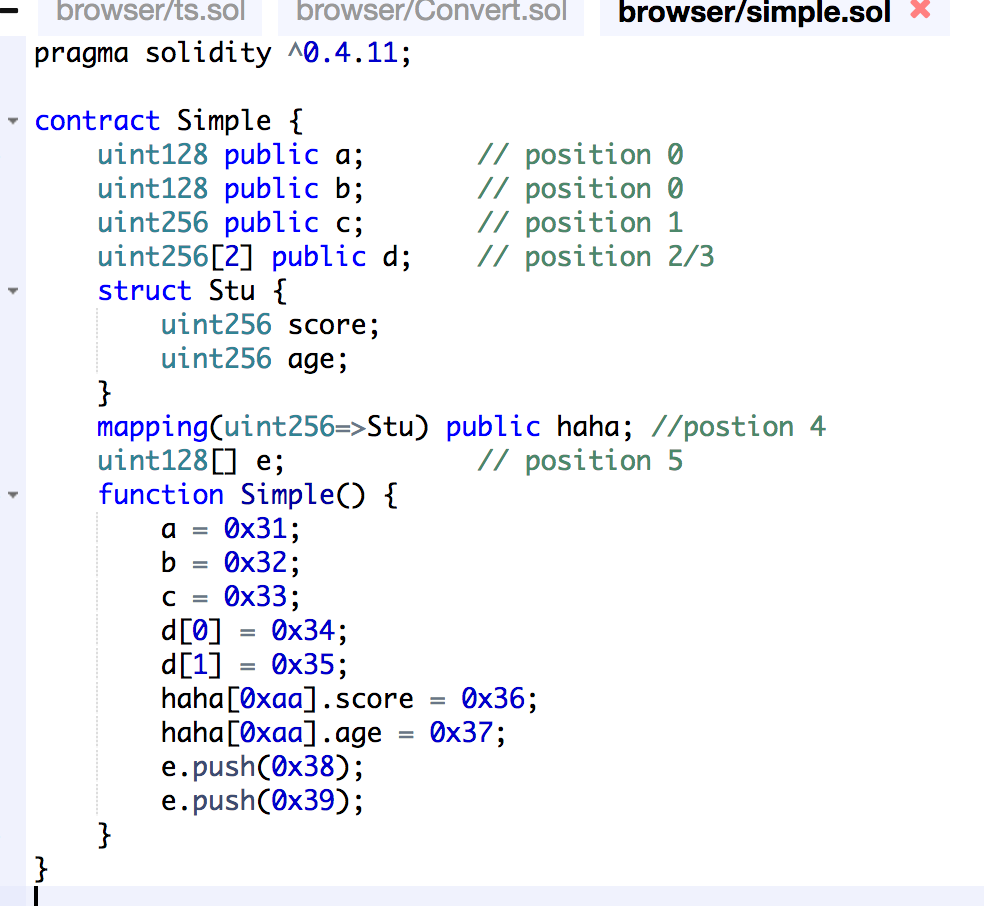
帐户存储树是存储与帐户关联的数据的地方。这仅与合约账户相关,所有智能合约数据都作为 32 字节整数之间的映射保存在账户存储树中。
并且,帐户状态存储有关帐户的信息,例如帐户有多少以及从帐户发送了多少交易。它有四个字段:nonce、balance、storageRoot 和 codeHash。它是世界状态树中的叶节点。
事务树
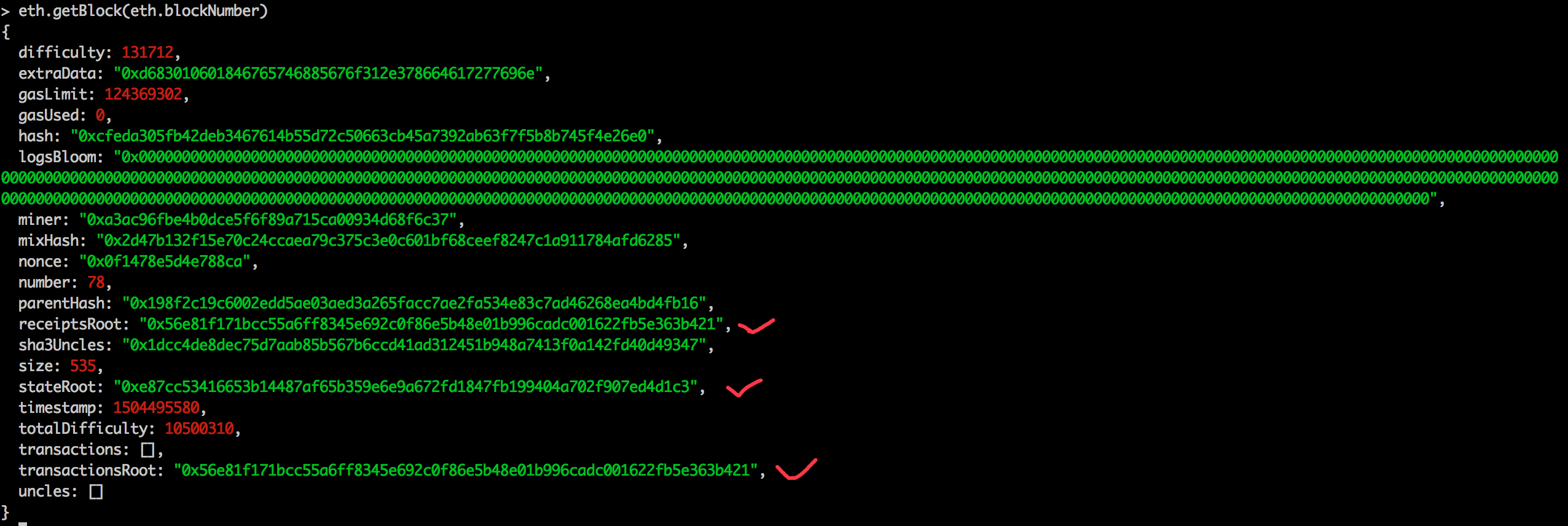
交易树记录以太坊中的交易。交易在改变状态方面起着核心作用,因为以太坊是基于交易的“状态”机器。一旦交易记录在一个区块中,就不能永久更改以证明账户余额(世界状态)。由于 Transaction Trie 是使用 Modified Merkel Patricia Trie 构建的,因此唯一的根节点存储在块中。下面的灰色框描述了交易数据字段。如果您想了解更多详细信息,请参阅以太坊交易结构说明。
nonce:交易 nonce 是从给定地址发送的交易序列号。
Gas Price:您愿意支付的价格
Gas Limit:Gas Limit 是发送方愿意为交易支付的 ETH 数量的限制
Recipient:收件人是以太坊地址的目的地。
Value:值字段表示从发送者到接收者的以太币/wei 的数量。
Data:数据字段用于合同相关活动,例如合同的部署或执行。
v,r,s:该字段是原始 EOA 的 ECDSA 数字签名的组成部分。交易收据树(Receipt Trie)
交易收据 Trie 记录交易的收据(结果)。收据是交易成功执行的结果。收据包括交易的哈希值、区块号、使用的gas 数量和合约地址等。这是交易收据的字段。
blockHash: String, 32 Bytes - 此交易所在区块的哈希值。
blockNumber: Number - 此交易所在的区块号。
transactionHash: String, 32 Bytes - 交易的哈希值。
transactionIndex: Number - 区块中交易索引位置的整数。
from: String, 20 Bytes - 发件人的地址。
to: String, 20 Bytes - 接收者的地址。如果是合约创建交易,则为 null。
cumulativeGasUsed: Number - 在区块中执行此交易时使用的总燃料量。
gasUsed: Number - 仅此特定交易使用的 gas 量。
contractAddress: String - 20 Bytes - 创建的合约地址,如果交易是合约创建,否则为 null。
logs:数组 - 此事务生成的日志对象数组。
status : String - '0x0' 表示交易失败,'0x1' 表示交易成功。引用:https : //ethereum.stackexchange.com/questions/6531/structure-of-a-transaction-receipt
结论
文章解释了以太坊的主要状态尝试:Merkle Patricia Trie、世界状态Trie、交易Trie、收据Trie和账户存储Trie。由于以太坊是一个世界的“状态机”,它具有原始的机制来记录和管理状态与特里数据结构。世界状态树存储帐户状态,表示帐户有多少钱。交易树记录可以更新世界状态树的交易,并且不可变地存储在区块链中以证明活动历史。Receipt trie 代表交易的结果,可以对外查询。我希望这篇文章有助于加深您对以太坊的了解。
参考
深入了解以太坊的世界状态
以太坊解释:默克尔树、世界状态、交易等
了解以太坊中的 Trie 数据库
Transaction Trie 和 Receepts Trie 之间的关系
以太坊区块架构
以太坊中的数据结构| 第 1 集:递归长度前缀 (RLP) 编码/解码。
Modified Merkle Patricia Trie——以太坊如何拯救一个状态
原文
https://medium.com/@eiki1212/ethereum-state-trie-architecture-explained-a30237009d4e