解锁消耗到了大量的 gas
每个人都在谈论 “无gas” 的以太坊交易,因为没有人喜欢支付gas费用。 但是以太坊网络的运行正是因为交易是付费的。 那么,你怎么才能“无gas”交易呢? 这是什么法术?
在本文中,我将展示如何使用 “无 gas” 交易背后的模式。 你会发现,尽管以太坊没有免费的午餐之类的东西,但是你可以通过有趣的方式改变 gas 成本。
通过运用本文中的知识,你的用户将节省大量 gas,享受更好的用户体验,甚至可以在你的智能合约中构建新颖的委派模式。
可是等等! 还有更多! 为方便起见,我将所需的所有工具都放在了此存储库中。 因此,现在你实现 “无 gas” 代币的障碍就突然降低了很多。
让我们开始吧。
背景
我不得不承认,即使我知道如何在智能合约中实现“无 gas”交易,但对于使它们成为可能的密码学我也知之甚少。 那对我来说不是障碍,所以对你也不应该是。
据我所知,私钥用于签署发送给以太坊的交易,一些密码学魔术用于将我(签名者)识别为msg.sender。 这支撑了以太坊中所有访问控制。
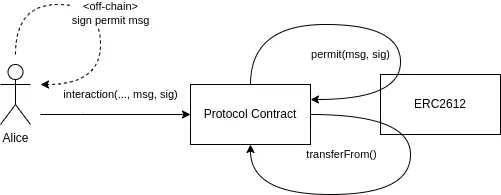
“无 gas” 交易背后的法宝是,我可以使用我的私钥和要执行的智能合约交易进行签名。签名是在链下进行的,而无需花费任何 gas。 然后,我可以将此签名交给其他人,以他们的名义代表我执行交易。
签名函数通常就是常规合约方法,但会使用其他签名参数进行扩展。 例如,在dai.sol中,我们有授权(approve)函数:
function approve(address usr, uint wad) external returns (bool)我们还具有permit许可函数,该功能与approve函数相同,但是将签名作为参数。
function permit(address holder, address spender, uint256 nonce, uint256 expiry, bool allowed, uint8 v, bytes32 r, bytes32 s) external不用担心所有这些额外的参数,我们将介绍它们。 你需要注意的是这两个函数都使用allowance映射执行的操作:
function approve(address usr, uint wad) external returns (bool)
{
allowance[msg.sender][usr] = wad;
…
}
function permit(
address holder, address spender,
uint256 nonce, uint256 expiry, bool allowed,
uint8 v, bytes32 r, bytes32 s
) external {
…
allowance[holder][spender] = wad;
…
}如果使用approve,则允许spender最多使用wad个代币。
如果你给某人提供有效的签名,则该人可以调用permit以允许spender 使用你的代币。
因此,基本上,“无 gas”交易背后的模式是制作可以提供给某人的签名,以便他们可以安全地执行特殊交易。 这就像授予某人执行函数的权限。
这是一种授权模式。
标准
如果你像我一样,那么你要做的第一件事就是深入研究代码。 我立即注意到此注释:
// — — EIP712 niceties — -有了这个,我钻进了兔子洞,却无望地迷路了。 现在,我已经理解了,我可以用简单的方式来解释它。
EIP712描述了如何以通用方式构建函数签名。 其他EIP描述了如何将EIP712应用。 例如,EIP2612描述了如何使用EIP712的签名应用于permit函数,其功能应与ERC20代币中的approve功能相同。
如果你只想实现之前提到的签名功能,例如将签名批准添加到自己的MetaCoin,则可以阅读EIP2612 ,你甚至可以继承实现过的合约,并减轻生活压力。
在本文中,我们将研究dai.sol中“无 gas”交易的实现。 这将使事情变得清晰。 dai.sol实现发生在EIP2612之前,会略有不同。 那不会有问题。
签名组成
EIP712签名的早期实现可以在dai.sol源码中找到 。 它允许Dai持有人通过计算链下签名并将其提供给支出者(spender)来批准转账交易,而不是自己调用approve函数。
它包含下面几个部分:
- 一个 DOMAIN_SEPARATOR .
- 一个 PERMIT_TYPEHASH .
- 一个 nonces 变量.
- 一个 permit 函数.
这是DOMAIN_SEPARATOR,和相关变量:
string public constant name = "Dai Stablecoin";
string public constant version = "1";
bytes32 public DOMAIN_SEPARATOR;
constructor(uint256 chainId_) public {
...
DOMAIN_SEPARATOR = keccak256(abi.encode(
keccak256(
"EIP712Domain(string name,string version," +
"uint256 chainId,address verifyingContract)"
),
keccak256(bytes(name)),
keccak256(bytes(version)),
chainId_,
address(this)
));
}DOMAIN_SEPARATOR只不过是唯一标识智能合约的哈希。 它是由EIP712域(EIP712Domain)的字符串,包含代币合约的名称,版本,所在的chainId以及合约部署的地址构成。
所有这些信息都在构造函数上进行hash 运算赋值到DOMAIN_SEPARATOR变量中,该变量在创建线下签名时由持有人使用,并且在执行permit时需要匹配。 这样可以确保签名仅对一个合约有效。
这是PERMIT_TYPEHASH:

PERMIT_TYPEHASH 是函数名称(大写开头)和所有参数(包括类型和名称)的哈希。 目的是清楚地标志签名的函数。
签名将在permit函数中处理,如果使用的PERMIT_TYPEHASH不是该特定函数的签名,它将回退交易。 这样可以确保仅将签名用于预期的功能。
然后是nonces映射:
mapping (address => uint) public nonces;该映射记录了特定持有人已使用了多少次签名。 创建签名时,需要包含一个nonces值。 执行permit时,所包含的nonce 值必须与该持有人到目前为止使用的签名数完全匹配。 这样可以确保每个签名仅使用一次。
所有这三个条件,即PERMIT_TYPEHASH,DOMAIN_SEPARATOR和nonce,确保每个签名仅用于预期的合约,预期的函数,并且仅使用一次。
现在,让我们看看如何在智能合约中处理签名。
permit 函数
permit是dai.sol里实现的函数,允许使用签名来修改持有人的 allowance对spender授权的数量。
// --- 通过签名授权 ---
function permit(
address holder, address spender,
uint256 nonce, uint256 expiry, bool allowed,
uint8 v, bytes32 r, bytes32 s
) external;如你所见,permit有很多参数。 它们是计算签名所需的所有参数,加上签名本身就是v, r和s。
你需要用参数创建签名似乎很愚蠢,但是你确实需要。 因为仅能从签名中恢复签名的地址。 我们将使用所有参数和恢复的地址来确保签名有效。
首先,我们使用确保安全性所需的所有参数来计算digest。 作为签名创建的一部分,holder将需要在链下计算出完全相同的digest:
bytes32 digest =
keccak256(abi.encodePacked(
"\x19\x01",
DOMAIN_SEPARATOR,
keccak256(abi.encode(
PERMIT_TYPEHASH,
holder,
spender,
nonce,
expiry,
allowed
))
));使用ecrecover和v,r,s签名,我们可以恢复地址。 如果它是holder的地址,我们知道所有参数都匹配DOMAIN_SEPARATOR,PERMIT_TYPEHASH,nonce,holder,spender,expiry和allowed。 哪怕是任何一点内容没匹配,则签名被拒绝:
require(holder == ecrecover(digest, v, r, s), "Dai/invalid-permit");请注意这里。 签名中有许多参数,其中一些参数有点模糊,例如chainId (它是 DOMAIN_SEPARATOR 的一部分)。 它们中的任何一个不匹配都会导致签名被拒绝,并带有完全相同的错误提示,这让链下调试签名很困难。
现在我们知道 holder 批准了这个函数调用。 接下来,我们将证明签名没有被滥用。 我们检查当前时间是否在 expiry(过期)之前,这保证了仅在特定时间内许可有效。
require(expiry == 0 || now <= expiry, "Dai/permit-expired");我们还会检查签名中的 nonce ,以便每个签名只能使用一次。
require(nonce == nonces[holder]++, "Dai/invalid-nonce");这些检查都通过了! dai.sol使spender可以使用的holder的代币数量设置为最大值(即allowance设置为最大),并触发一个事件,仅此而已。
uint wad = allowed ? uint(-1) : 0;
allowance[holder][spender] = wad;
emit Approval(holder, spender, wad);dai.sol合约对 allowance 使用的是二分法设置(译者注:要么是最大,要么是 0), 在代码库,有更传统的方法。
创建链下签名
创建签名也许需要通过一些实践才可以掌握它。 我们将分三步复制智能合约中permit的功能:
- 生成 DOMAIN_SEPARATOR
- 生成 digest
- 创建交易签名
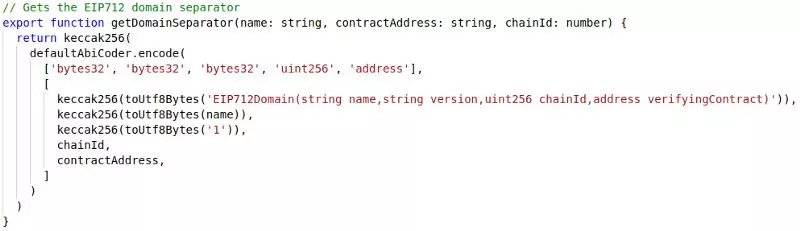
以下函数将生成 DOMAIN_SEPARATOR。 它与dai.sol构造函数中的代码相同,但在JavaScript中实现,并使用ethers.js的keccak256,defaultAbiCoder和toUtfBytes,它需要代币名称和部署地址,以及chainId。 假定代币版本为“1”。
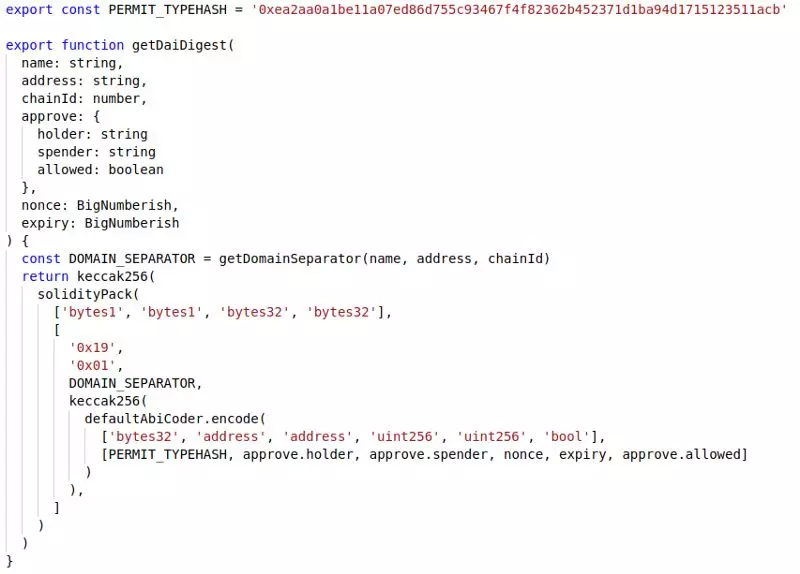
以下函数将为特定的permit调用生成digest。 注意,holder,spender,nonce 和 expiry作为参数传递。 为了清楚起见,它还传递了一个 approve.allowed 参数,尽管你可以将其始终设置为 true,否则签名将被拒绝。从刚刚dai.sol复制PERMIT_TYPEHASH。
一旦我们有了digest,对其进行签名就相对容易了。 我们从[digest]中删除0x前缀后,使用ethereumjs-util中的ecsign。 请注意,我们需要用户私钥才能执行此操作。
在代码中,我们将按以下方式调用这些函数:
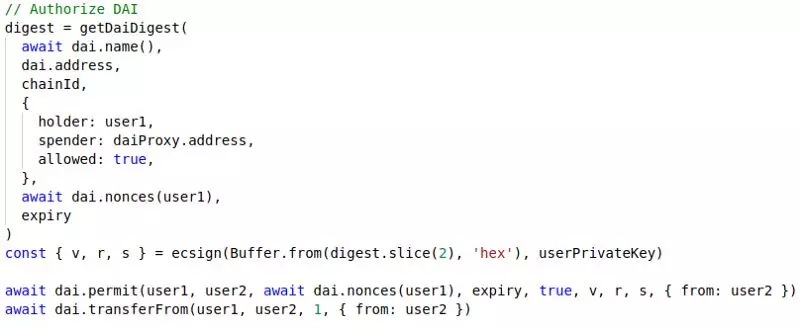
请注意,对permit的调用需要重用用于创建digest的所有参数。 只有在这种情况下,签名才有效。
还要注意的是,此代码段中仅有的两个交易是由user2调用的。 user1是holder,是创建digest并签名的用户。 但是,user1并没有花费任何gas。
user1将签名提供给user2,后者使用它来执行user1授权的 permit 和transferFrom。
从 user1的角度来看,这是一次“无 gas”交易, 他没有花一分钱。
结论
本文介绍了如何使用“无Gas”交易,阐明了“无Gas”实际上意味着将Gas成本转移给其他人。 为此,我们需要一个智能合约中的功能,该功能可以处理预先签署的交易,并且需要进行大量的数据检验以确保一切安全。
但是,使用此模式有很多好处,因此,它被广泛使用。 签名允许将交易 gas 成本从用户转移到服务提供商,从而在许多情况下消除了相当大的障碍。 它还允许实现更高级的委派模式,通常会对UX进行相当大的改进。
已为您提供入门代码库,请使用它。
本翻译由 Cell Network 赞助支持。





{kind=link}
{kind=link}