使用 standard-input-json(以BSC测试链为例)
合约源码
Storage.sol
// SPDX-License-Identifier: MIT
pragma solidity >=0.7.0 <0.9.0;
import "@openzeppelin/contracts/access/Ownable.sol";
contract Storage is Ownable {
uint256 number;
function setNumber(uint256 num) public onlyOwner {
number = num;
}
function getNumber() public view returns (uint256) {
return number;
}
}
JSON格式的输入
Storage.json
{
"language": "Solidity",
"sources": {
"contracts/Storage.sol": {
"content": "// SPDX-License-Identifier: MIT\n\npragma solidity >=0.7.0 <0.9.0;\nimport \"@openzeppelin/contracts/access/Ownable.sol\";\n\ncontract Storage is Ownable {\n uint256 number;\n\n function setNumber(uint256 num) public onlyOwner {\n number = num;\n }\n\n function getNumber() public view returns (uint256) {\n return number;\n }\n}"
},
"@openzeppelin/contracts/access/Ownable.sol": {
"content": "// SPDX-License-Identifier: MIT\n// OpenZeppelin Contracts v4.4.1 (access/Ownable.sol)\n\npragma solidity ^0.8.0;\n\nimport \"../utils/Context.sol\";\n\n/**\n * @dev Contract module which provides a basic access control mechanism, where\n * there is an account (an owner) that can be granted exclusive access to\n * specific functions.\n *\n * By default, the owner account will be the one that deploys the contract. This\n * can later be changed with {transferOwnership}.\n *\n * This module is used through inheritance. It will make available the modifier\n * `onlyOwner`, which can be applied to your functions to restrict their use to\n * the owner.\n */\nabstract contract Ownable is Context {\n address private _owner;\n\n event OwnershipTransferred(address indexed previousOwner, address indexed newOwner);\n\n /**\n * @dev Initializes the contract setting the deployer as the initial owner.\n */\n constructor() {\n _transferOwnership(_msgSender());\n }\n\n /**\n * @dev Returns the address of the current owner.\n */\n function owner() public view virtual returns (address) {\n return _owner;\n }\n\n /**\n * @dev Throws if called by any account other than the owner.\n */\n modifier onlyOwner() {\n require(owner() == _msgSender(), \"Ownable: caller is not the owner\");\n _;\n }\n\n /**\n * @dev Leaves the contract without owner. It will not be possible to call\n * `onlyOwner` functions anymore. Can only be called by the current owner.\n *\n * NOTE: Renouncing ownership will leave the contract without an owner,\n * thereby removing any functionality that is only available to the owner.\n */\n function renounceOwnership() public virtual onlyOwner {\n _transferOwnership(address(0));\n }\n\n /**\n * @dev Transfers ownership of the contract to a new account (`newOwner`).\n * Can only be called by the current owner.\n */\n function transferOwnership(address newOwner) public virtual onlyOwner {\n require(newOwner != address(0), \"Ownable: new owner is the zero address\");\n _transferOwnership(newOwner);\n }\n\n /**\n * @dev Transfers ownership of the contract to a new account (`newOwner`).\n * Internal function without access restriction.\n */\n function _transferOwnership(address newOwner) internal virtual {\n address oldOwner = _owner;\n _owner = newOwner;\n emit OwnershipTransferred(oldOwner, newOwner);\n }\n}\n"
},
"@openzeppelin/contracts/utils/Context.sol": {
"content": "// SPDX-License-Identifier: MIT\n// OpenZeppelin Contracts v4.4.1 (utils/Context.sol)\n\npragma solidity ^0.8.0;\n\n/**\n * @dev Provides information about the current execution context, including the\n * sender of the transaction and its data. While these are generally available\n * via msg.sender and msg.data, they should not be accessed in such a direct\n * manner, since when dealing with meta-transactions the account sending and\n * paying for execution may not be the actual sender (as far as an application\n * is concerned).\n *\n * This contract is only required for intermediate, library-like contracts.\n */\nabstract contract Context {\n function _msgSender() internal view virtual returns (address) {\n return msg.sender;\n }\n\n function _msgData() internal view virtual returns (bytes calldata) {\n return msg.data;\n }\n}\n"
}
},
"settings": {
"optimizer": {
"enabled": true,
"runs": 200
},
"outputSelection": {
"*": {
"*": [
"abi",
"evm.bytecode",
"evm.deployedBytecode",
"evm.methodIdentifiers",
"metadata"
],
"": [
"ast"
]
}
}
}
}
content内容:将solidity源码转换为JSON字符串。
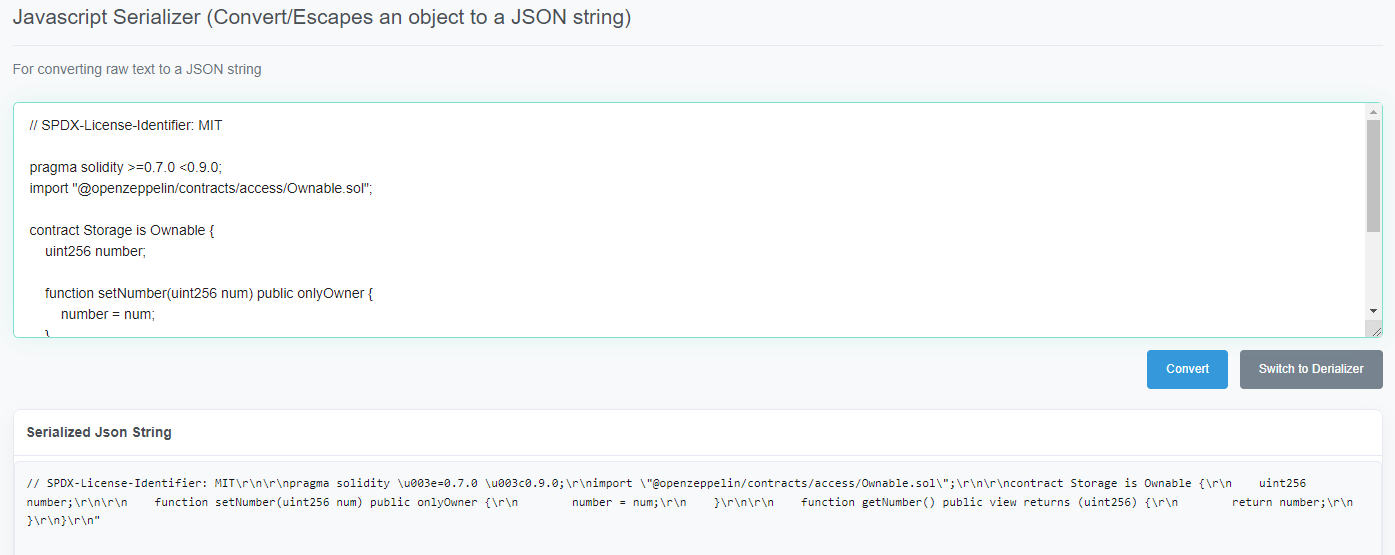
Javascript Serializer(推荐方法2、方法3)
Convert/Escapes an object to a JSON string
将solidity源码转换为JSON字符串
方法1.BSC网址
去掉最后的 ”
方法2.字符串转义
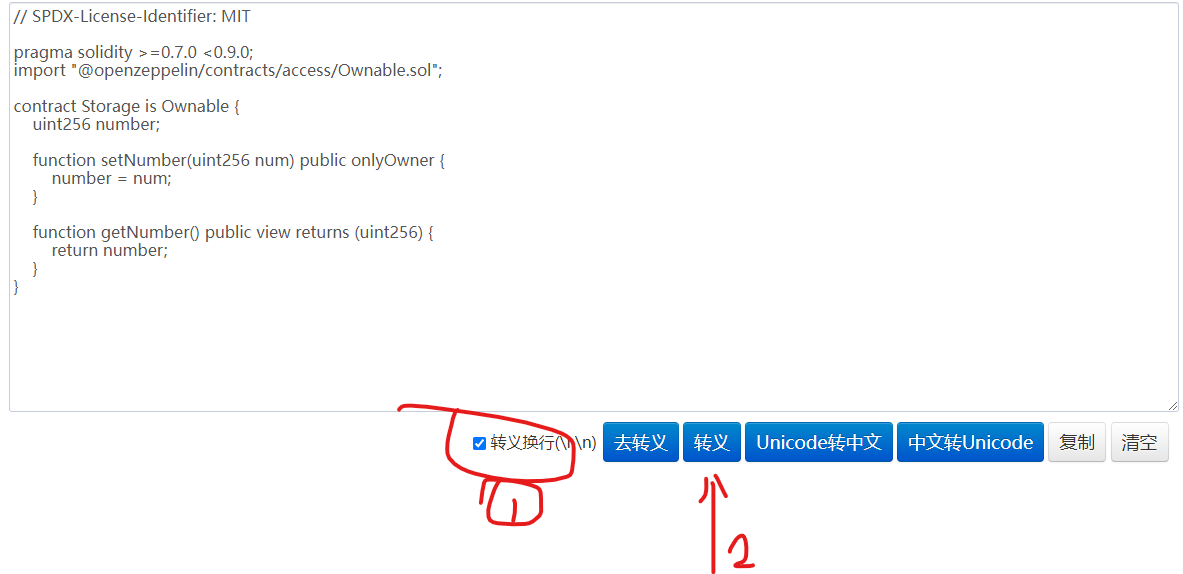
// SPDX-License-Identifier: MIT\n\npragma solidity >=0.7.0 <0.9.0;\nimport \"@openzeppelin/contracts/access/Ownable.sol\";\n\ncontract Storage is Ownable {\n uint256 number;\n\n function setNumber(uint256 num) public onlyOwner {\n number = num;\n }\n\n function getNumber() public view returns (uint256) {\n return number;\n }\n}
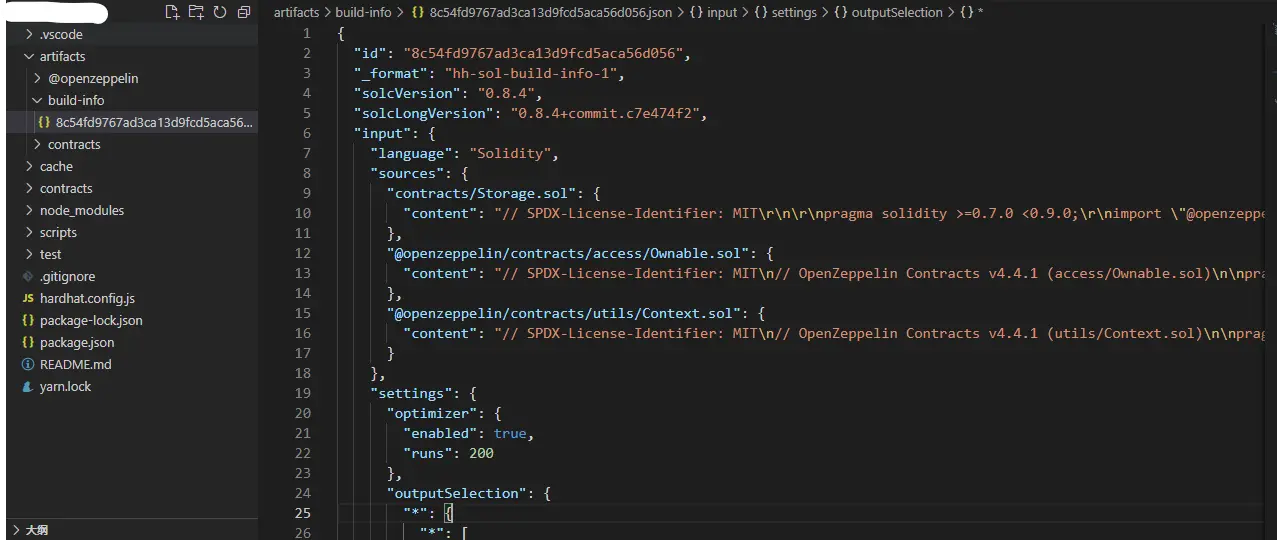
方法3. Hardhat项目下
编译合约:
npx hardhat compile
打开artifacts\build-info路径下的json文件
input字段内容
部署合约
部署合约
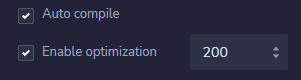
与Storage.json配置文件相同
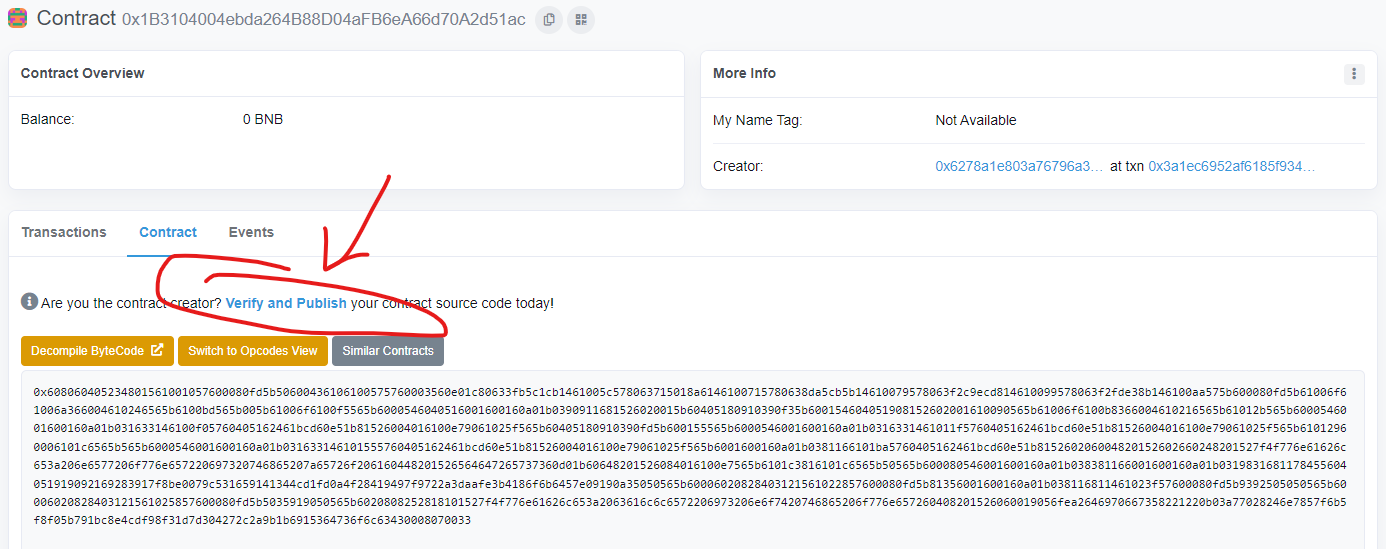
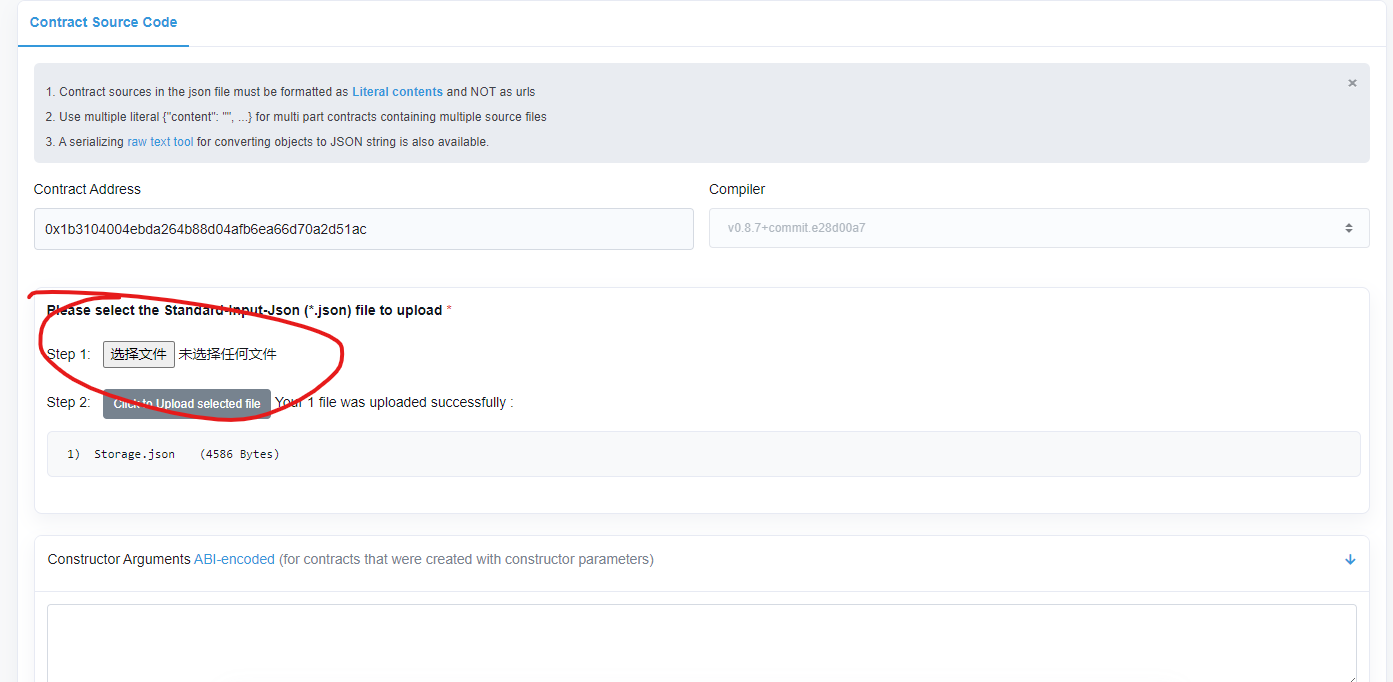
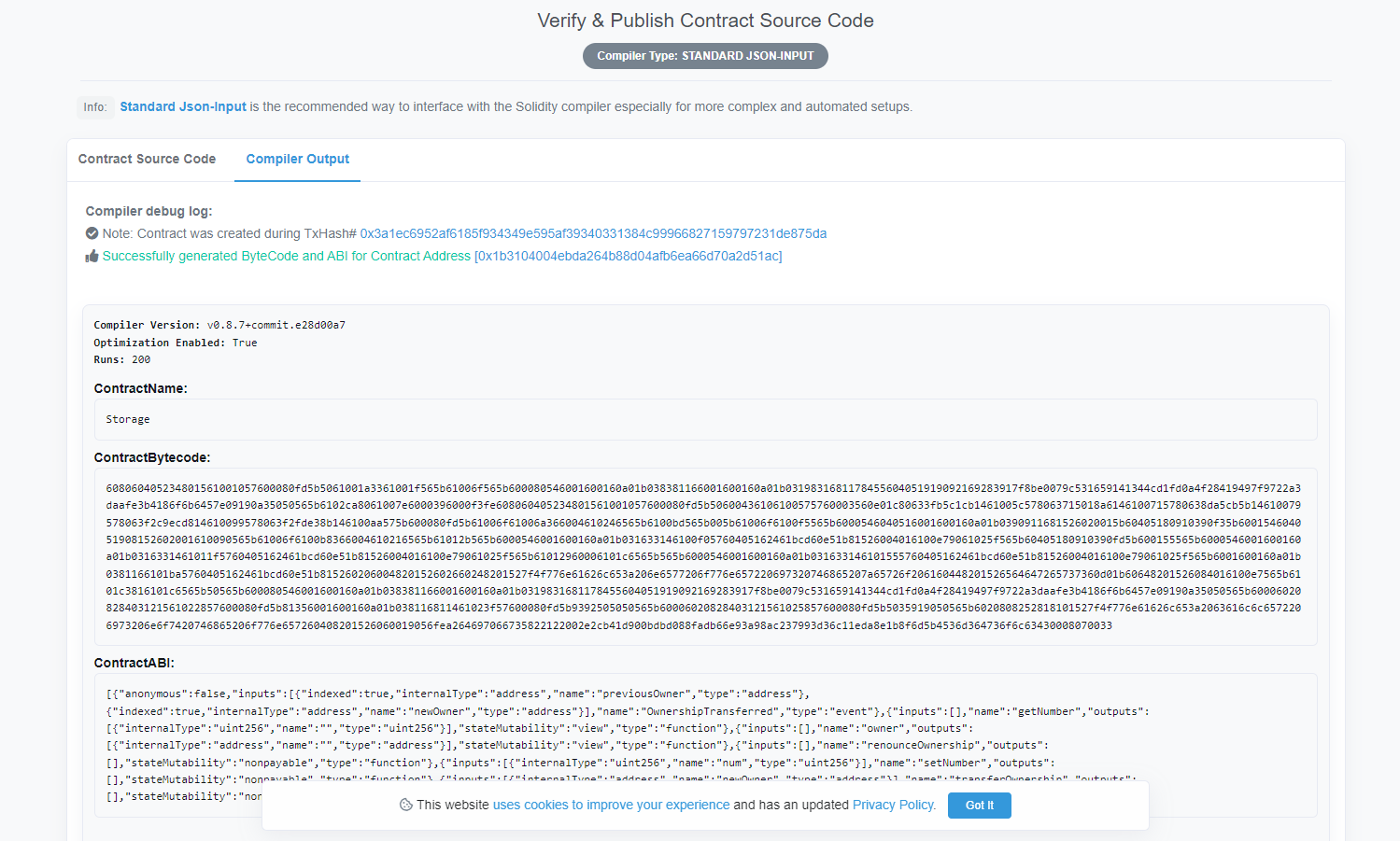
BSC浏览器验证合约
https://testnet.bscscan.com/address/0x1b3104004ebda264b88d04afb6ea66d70a2d51ac#code
-
-
-
转载自:https://learnblockchain.cn/article/3415