各种智能合约语言有自己的设计哲学,他们并非一样,这篇文章探索一下 Solidity、Cairo、Rust和Move的语言设计的权衡。
我相信一些智能合约新手甚至精通web2的开发者可能会好奇,如何选择第一门智能合约编程语言来学习。现在,有很多选择,如EVM的Solidity,Starknet的Cairo,Solona的Rust,Aptos & Sui的Move,等等。
事实是,没有绝对正确或错误的答案。每种语言都有取舍。真正的问题是 "当我们在使用一种智能合约编程语言开发时,是否意识到了他们的差异?"
就个人而言,我使用这个图表来可视化编程语言的基本功能和它们的局限性。
语言的权衡:实用性与安全性
事实上,这种权衡不仅是特定于智能合约领域。它适用于任何语言。
安全性
安全性有以下两个特点:
- Progress(进行):一个类型良好的程序可以被评估或求值
- Preservation(维持):维护步骤执行时的类型
因此,一旦类型被检查过,它们就可以被忽略,并且计算的运行不会出现错误。
一个安全的编程语言的例子是 "Haskell"。它是一种通用的和纯函数编程语言,具有静态的和强类型系统。它可以被认为是一种具有最少语法垃圾的数学语言。它的纯洁性提供了确定性、不可逆性和可控的副作用。因此,用Haskell编写的程序是可读的、合理的、可维护的、模块化的和可测试的。所有这些都直接或间接地与安全属性相联系。
因此,在对域模式l或域类型进行原型设计时,Haskell是一个很好的解决方案,因为它有复杂的类型推理引擎。它允许我们进行低成本的测试驱动开发。这有助于我们在投入大量精力在另一种语言的生产中进行真正的实现之前获得快速迭代和反馈。
实用性(有效性)
为了更清楚,你可能想知道为什么Haskell只是学术和研究工作中使用,而不是普遍用于生产中?它的函数式风格使它在某些工作中很有用,比如编译器。然而,在处理其他一些需要性能或效率的工业问题时,如网络服务器,它是没有意义的,因为这些应用需要状态操作或副作用,在这些方面,命令式编程范式语言做得非常好。换句话说,有两种计算模型(函数式编程的Lambda 演算和命令式编程的图灵机)。
重要的是,我提到,"实用"在这里意味着"有效"。特别是,它对世界有影响,它改变了某些状态。我绝对不是说一种具有使用价值的语言比其他语言优越。
然而,世界正在向函数式范式迈进。我们可以看到一些现代编程语言正在实现函数式编程的特点和设计。例如,functors、monoids、monads等等。
因此,多范式编程语言(在面向对象(OOP)与函数式风格之间混合)越来越受欢迎。具体来说,它并不严格要求命令式、面向对象(OOP)或函数式编程。例如,在Rust语言中,程序员可以在一个简单的boiler-page-free的宏或一个强大的(但程序化的)宏之间进行选择。另一个例子是Scala语言。它仍然是一种函数式编程语言,但没有Haskell那么纯粹。尽管如此,它也支持OOP,而且它的实用性足以解决现实世界的工业问题。
那么,用于工业生产的实用的语言有哪些?这方面的例子包括: Java, Ruby, Python, Javascript, Typescript, Rust, Scala 等。
这可以用下面的图来表示:
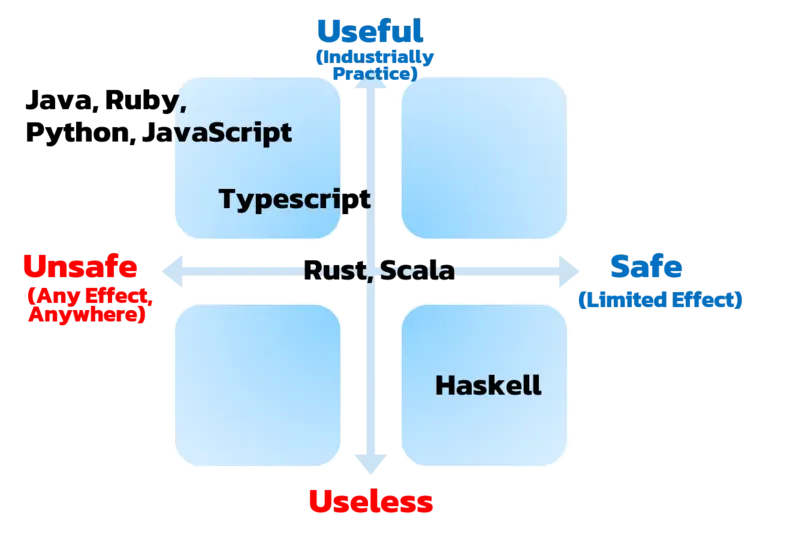
这个图表是从Simon Peyton Jones(Haskell语言的贡献者)那里借用和修改的。
有人提出了一个有趣的观点:"实用" 是主观的。例如,许多有经验的开发者可能会说,Typescript比Javascript更实用。在此案例中,我指出,用Typescript编写的程序需要更多的时间来定义类型,由于之前没有开发第三方库。因此,Javascript可能更实用。
重申,这个图表并不意味着某种语言比其他语言更好。实际上,它们是无法判断的。我并不是说 Java 在实践中比 Rust 更实用。它只是一个比喻,用来比较函数式和命令式范式。
转到智能合约编程语言背景...
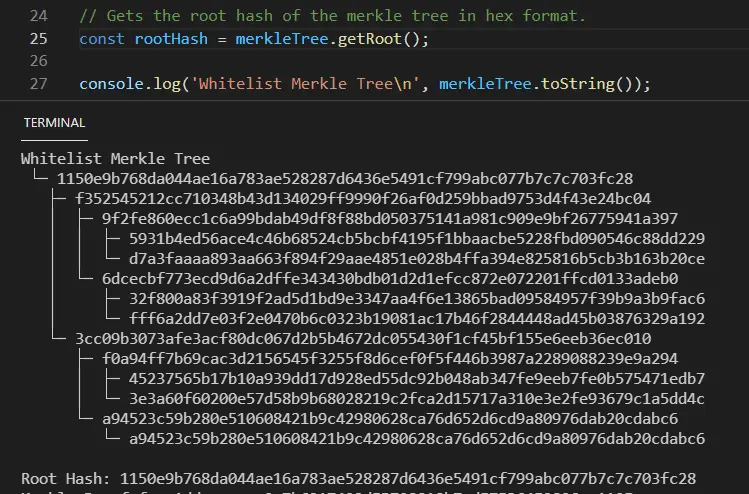
根据该图,实用性,在这里与区块链的独特功能更相关,如无信任性和去中心化。准确地说,智能合约程序的编写应该是为了做传统程序不能解决的问题。
不同的语言有不同的特点。这意味着这些语言也有不同程度的安全性权衡,这取决于每种语言。
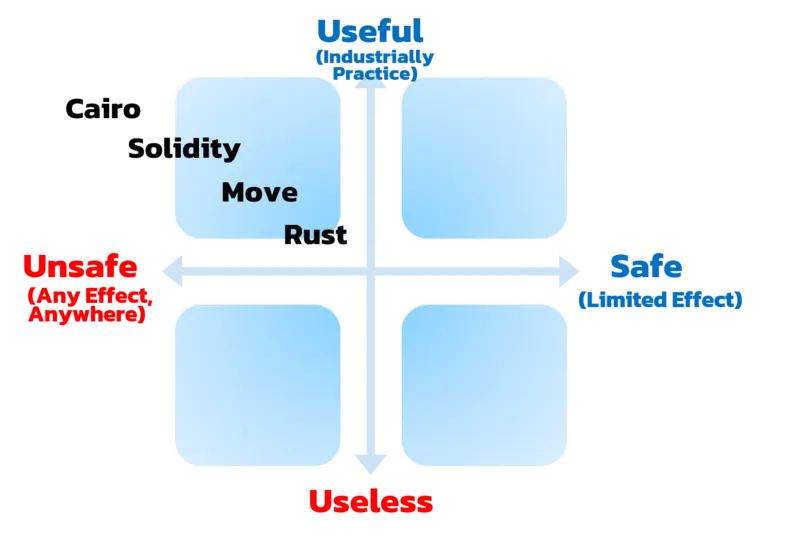
Solidity
Solidity 是第一个主流的图灵完备的编程语言,使以太坊虚拟机(EVM)进行可组合的计算。另外,Solidity是经过编译的高级语言。
例如,"可组合性 ",使任何人都能将现有部署的智能合约组件结合起来。这使得我们可以通过复制、修改和整合这些可互操作的乐高积木来创新出新的复杂系统。此外,智能合约应用程序通常是开源的,这意味着开发人员可以免费访问其源代码。
而对于传统的软件,开发者有时则需要从头开始开发一些基本的组件,这就需要花费金钱和时间。
值得注意的是,用Solidity编写的程序允许:
- 能够被编译成透明的字节码(没有隐藏的网络API)和ABI(应用二进制接口)(标准化的API结构 )
- 无停机,确保高可用性
- 在EVM中基本的状态机功能(状态、访问、更新等)
- 不同智能合约之间的可兼容接口
- 内置Gas和支付系统(不依赖第三支付方)
- 通过Solidity Assembly(汇编)的低级别性能访问
然而,可组合计算的主要权衡是安全。在某种程度上,可组合性,意味着外部行为者可以部署恶意的智能合约,同时隐藏他们的身份。同样,这些行为者不仅可以访问智能合约应用程序的代码库,而且还可以无限制地进行压力测试。
与传统软件相比,当软件是闭源的时候,这种攻击者不可能经常观察到代码库。此外,如果有一个bug,维护者可以在发现bug阶段保持离线。
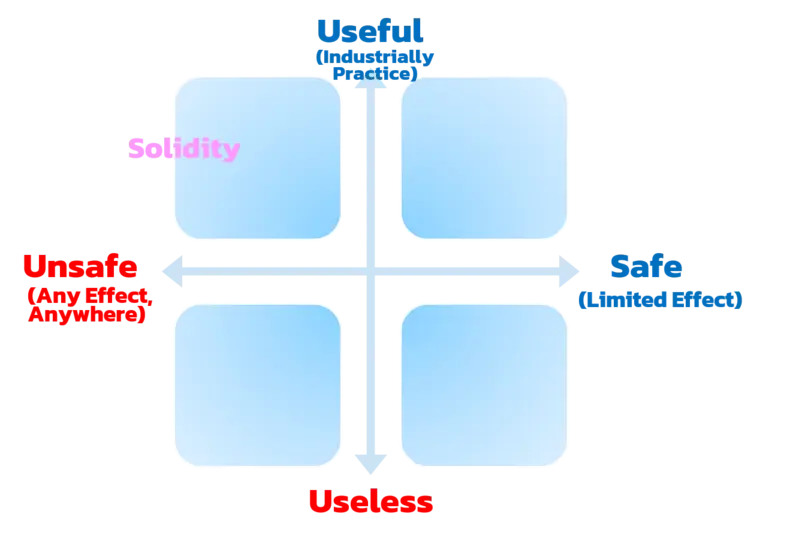
因此,Solidity可以定义为高实用性和低安全性。
Cairo
Cairo是第一个图灵完备的编程语言,使Layer2能够进行可证明计算。
可证明性意味着可以在Layer2(证明者(Prover)、Starknet OS、序列器(Sequencer))上生成一个证明,在Layer1完整节点上(通过EVM)验证Cairo程序的输出已经被正确计算。从而实现可扩展性,因为生成证明的运行时间几乎是线性的,而验证则是计算次数的对数。因此,链上计算的成本不会随着计算量的增加而发生很大变化。简单地说,计算发生在第2层而不是第1层,而第1层的全节点使用较少的计算资源来验证生成的证明。这是因为在验证过程中没有重新执行的计算。
证明者(Prover)是一个独立的进程,它接收Cairo程序的输出,然后生成STARK证明,进行验证。证明者将STARK证明提交给验证者,验证者在Layer1上注册事实。
StarkNet OS是基于 Cairo 的操作系统,本质上是 Cairo 程序 输出被证明和验证的程序。它根据交易作为输入的来更新系统的 L2状态。
序列器(或块提议者)- Sequencer:这个特殊的节点用相关的输入执行StarkNet OS Cairo 程序,用证明器证明结果,并最终在StarkNet核心合约上更新网络状态
另一方面,EVM中的可组合计算与可证明计算的范式不同。事实上,solidity开发者使用OOP和命令式编程作为主要范式。而Cairo的开发者则抽象出计算的输出是可以接受的。你可能认为这种范式是函数式编程,但它是非确定性的。
特别是,用Cairo编写的程序适用以下范式:
- 能够创建STARK-provable程序,用于一般计算。
- felt,一个低级的整数数据类型。在数学上,它使用模块化算术,其中modulo是一个素数。在进行可证明计算时,它比uint256更有效率。
- 支持在只读的非确定性存储器上运行
然而,可证明计算的权衡与可组合计算是一样的。原因是,Cairo是Solidity等价的。这意味着存在一个编译器,这样用Solidity编写的智能合约程序可以被编译成用Cairo编写的智能程序。因此,Cairo生态系统继承了许多以太坊标准(以太坊改进提案:EIPs)。在某种程度上,如果这些开发者之前在EVM生态系统中开发过,那么新的开发者很容易开始开发。不过注意,安全风险也是可以继承的,但 Cairo 开发者需要更认真地考虑这个问题。
除了在solidity中发现的常见漏洞(如重入、奇偶性等),Cairo引入了新的攻击载体。例如,Cairo语言只有一个数据类型,即Finite Field(又称felt)。因此,需要使用库来处理其他数据类型,这有可能导致安全风险。另一个有趣的错误是Under-constrained bug(非约束性错误)。在Cairo中,程序描述了理想的结果,而Hint是证明者如何产生这样的结果的抽象。
一个hint是一个块的代码(不一定是 Cairo 代码),它将在下一条指令之前被证明者执行
问题发生在有一个不恰当的断言时,所以在Cairo代码中的约束性编码允许一个恶意的证明者产生非预期的结果。这是因为那些证明者不一定使用开发者的hint !。
综上所述,Cairo的安全风险远大于Solidity,它可以用以下方式表示:
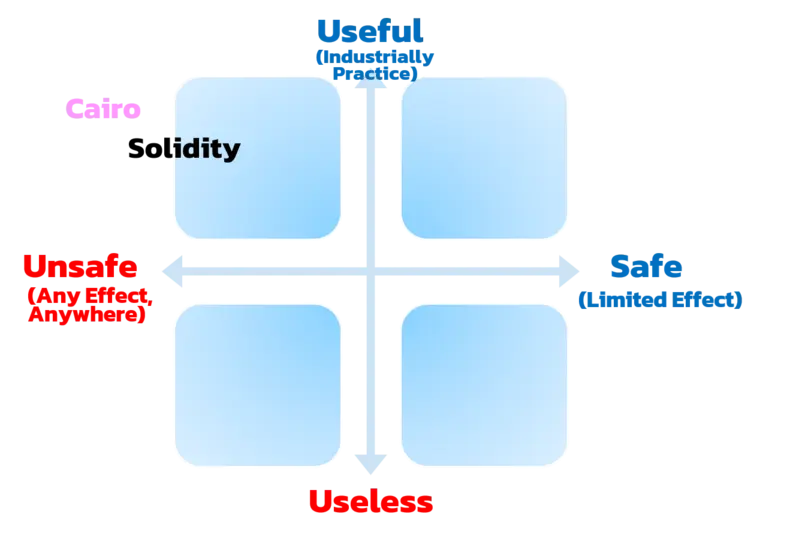
Rust
Rust是一种编译的、系统级的、多范式的编程语言(并发式、函数式和命令式)。
具体来说,Rust 实现了以下功能:
- 函数式编程:闭包、匿名函数、迭代器。
- Traits( 在其他语言中,对应是接口)
- 生命周期(处理引用)
- 零成本抽象
- 通过宏系统进行元编程、异步编程(async/await)
实际上,Rust开发者可以有效地管理内存,并利用并行处理的高性能。一个很好的例子是Solana,它有助于实现高吞吐量的高扩展性。
更重要的是,众所周知,许多加密算法和基于零知识的应用都是使用Rust实现的。
尽管如此,区块链的实用性(如无信任和去中心化)被权衡了,因为它是一种通用的编程语言,不限于智能合约背景。换句话说,Rust比上面提到的其他智能合约语言更安全。
事实上,Rust的主要特点是安全。Rust可以提供强大的安全保障,这要归功于借用(borrowing)检查功能。一旦代码在充分测试的情况下被编译,程序就会在安全保证下运行。例如,Rust在字符串处理方面做得很好,因为它很容易写出不能溢出的代码。
值得注意的是,尽管与代码意图无关的技术实现(如溢出)被最小化了,但开发者仍然需要照顾到领域业务或设计层面的潜在缺陷。
因此,Rust在这个位置:
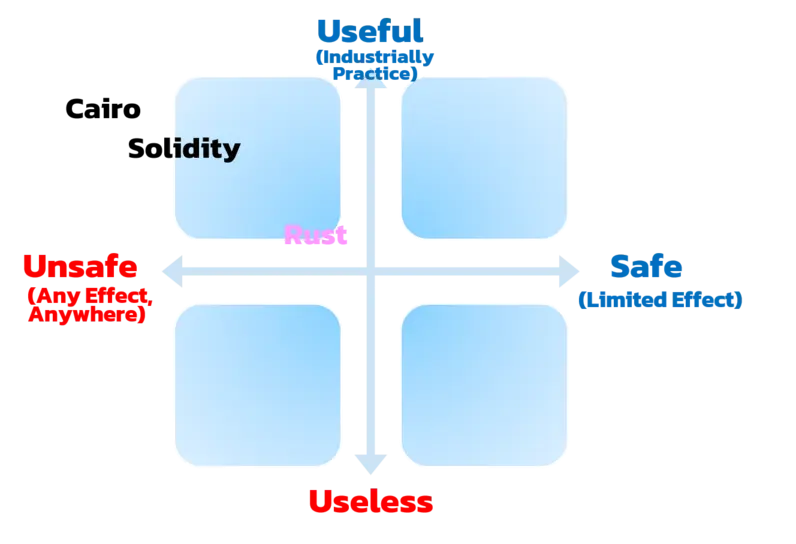
Move
Move是一种解释型的,和OOP的编程语言。它特意为基于区块链的应用而设计。
具体来说,Rust强调了以下范式:
- 一流的资源管理(资产asset被抽象为一个特定的资源类型系统)。
- 可验证性(链外静态验证工具)
另外,Move是基于Rust的。由于高效的内存管理和并行处理,因此它允许高吞吐量。尽管如此,它是解释语言而不是编译语言。一般来说,性能可能会比较慢。
关于它的安全性,来自编译器的错误被消除了,因为Move是一种解释语言。此外,由于安全的资源类型系统,一些众所周知的智能合约漏洞(如重入)被跟除。
尽管如此,开发人员在对Move智能合约进行编程时,还是需要谨慎对待。由于它是一种非常新的语言,社区规模相对较小,安全实践还不成熟,而且有很多未知的逻辑错误,让开发者跳入兔子洞。
所以,Move可以被认为是介于Solidity和Rust之间,具体位置如下:
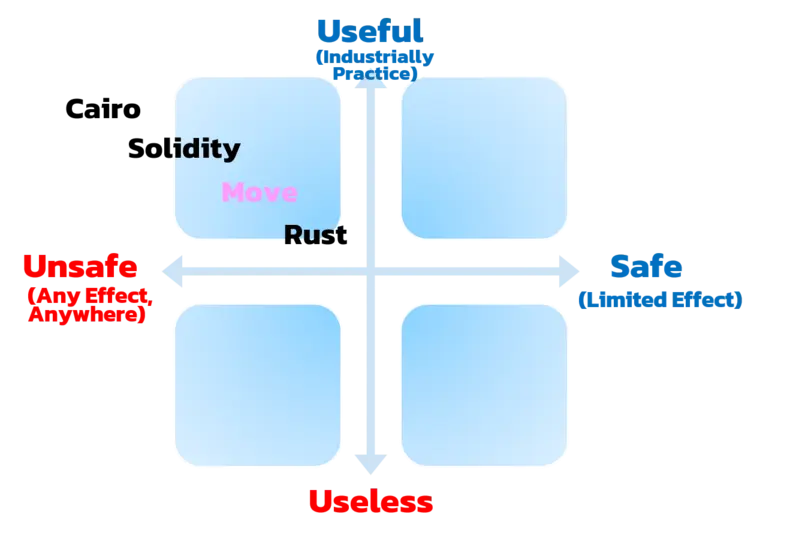
最后的思考
如前所述,在这些编程语言中,实用性与安全性之间的权衡是相当不同的。尽管这种权衡对于传统的和智能合约编程语言来说都是真实的,但这些智能合约语言和相关框架的生命周期都比传统的短得多。此外,每天都有越来越多的新区块链语言出现,一个人在短时间内成为所有语言的专家是不可能的。因此,选择正确的可持续发展的语言是相当重要的,它将会持续很长时间。我希望在深入研究任何语言之前,所提供的图表可以作为一个指导原则。
参考资料
ethereum.org. smart contract composability
starknet.io. Hints
ctrlc03.github.io. Cairo and StarkNet Security
Peteris Erins. 可证明与可组合计算或为什么Cairo将取代Solidity
Yield App Labs. Solidity vs Move vs Rust: 智能合约编程语言的演变
Gwyneth Iredale. Move编程语言概述
转载自:https://learnblockchain.cn/article/5365