这篇文章重点介绍了在Solidity中可以访问的EVM的最后一个数据位置:智能合约的字节码。
我们将在架构层面上考察合约的字节码的大部分内容。这包括对 "智能合约的字节码存储在哪里 "的一些详细解释,以及创建时(creation)和运行时(runtime)代码的区别。
我们还将解密部署智能合约时运行的字节码,以了解当我们部署一个没有 constructor的智能合约时,它是如何工作的。这将有助于我们理解EVM如何(以及为什么)返回智能合约的运行时代码,将其保存在智能合约地址下的以太坊的世界状态。
我们最后将看看围绕OpenZeppelin库的isContract()函数的一些安全注意事项,这些注意事项与EXTCODESIZE操作码直接相关。
代码的基础知识
当我们学习以太坊时,首先了解到的是以太坊上有两种类型的账户--外部拥有的账户(EOAs)和智能合约。以太坊网站提供了以下的定义:
- 外部拥有的账户(EOAs)--由任何人通过其私钥控制。
- 合约账户--部署在网络中的智能合约,由代码控制。
由于外部拥有的账户(或EOAs)在其地址下没有存储代码,这就是智能合约的独特之处:其代码,也被称为 "合约字节码"。
一个合约的字节码是构成智能合约逻辑的所有EVM指令的存储地。代码中的每个字节都是一个操作码的十六进制表示。因此,合约代码的字节码是:
EVM.codes的解释为 "字节码是智能合约执行过程中 EVM 读取、解释和执行的字节。"
我们使用术语 "字节码 "而不是 "代码",以避免混淆并与Solidity高层代码相区别。
合约字节码的属性

如果我们看一下以太坊黄皮书的这段摘录,我们可以看到合约的字节码被存储在一个单独的虚拟ROM(只读存储器)中。这给我们带来了合约代码的一个重要特征:代码是不可改变的。
这意味着一旦合约被部署,合约的代码就不能被修改。它的指令数据,存储在代码中(构成智能合约逻辑的操作码),是持久的,如上所述,是账户状态字段的一部分。
一旦合约被部署,其代码就不能被改变。因此,存储在代码中的数据和变量是只读的,不能编辑。
将变量存储在合约的字节码内是Gas高效的。从合约字节码中访问这些变量是廉价和高效的。
与代码有关的操代码。
有四个操作码与合约的字节码有关。
- CODESIZE
- CODECOPY
- EXTCODESIZE
- EXTCODECOPY
操作码CODESIZE和CODECOPY使你能够读取和复制我们目前正在执行的合约的字节码。
最后,EXTCODESIZE和EXTCODECOPY使你能够从一个合约中提供体统的地址读取和复制另一个外部合约的字节码。
代码的布局
注意:请参阅系列文章,来自OpenZeppelin "解构Solidity合约 ",以深入了解一个合约字节码的布局。
代码是由字节组成的(与存储不同,它是由 槽(slot) 组成的)。在智能合约的字节码中,不存在 槽 的概念。存储在合约字节码中的变量,如 constant或 immutable,编译器可能放置在代码中的任何位置。
代码总是32字节的倍数。参见zkSync的L1ERC20Bridge使用的L2ContractHelper。
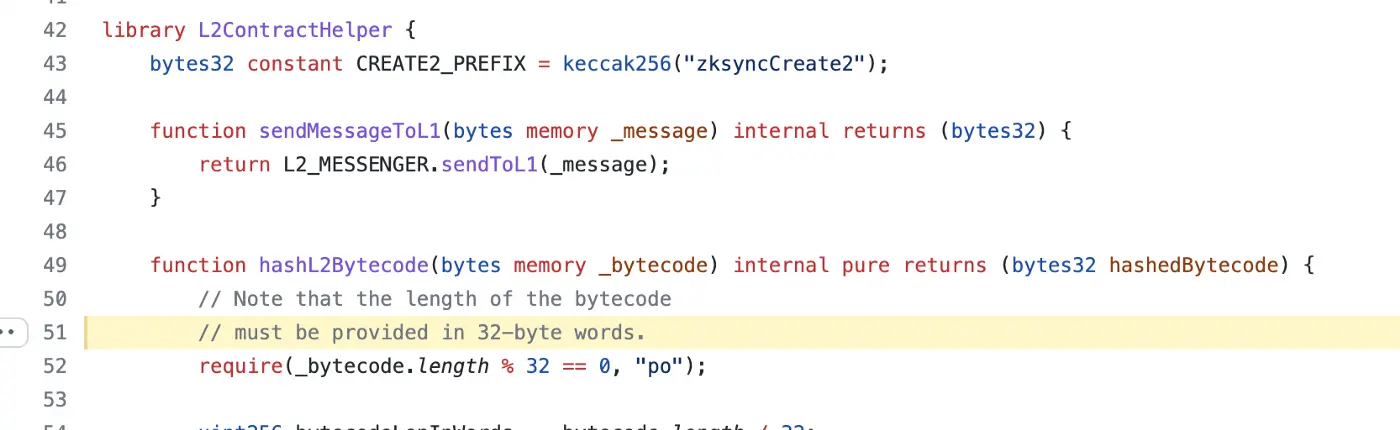
Solidity库合约L2ContractHelper来自GitHub上的zkSync
智能合约的运行时字节码可以被分成三个主要部分:
- 调度器(dispatcher):也被称为 "枢纽(hub)",旨在通过分析calldata并将其与函数选择器进行比较来找到智能合约。
- 函数包装器:旨在解包/拆包函数参数,并包装由函数主体返回的值。
- 函数主体:包含Solidity函数的主要逻辑。
参见解构Solidity合约 #1 - 字节码 文章的解构图。

除了这三个主要部分,智能合约的字节码还包括三个小部分:
- 自由空闲指针
- Calldata检查:确保我们至少发送四个字节函数选择器。如果没有,则使用receive/fallback函数作为默认的函数处理程序。
- 合约元数据
为了简洁起见,我们将不详细包括这些部分。然而,我强烈建议你看看上面提到的专栏的OpenZeppelin系列解构文章,以便深入了解。
专栏: 理解 EVM 已经包含OpenZeppelin系列文章:
我们看看调度器是如何工作的,因为它是任何智能合约字节码中的主要通用组件之一(每个合约的其余字节码是独特的,因为它取决于 Solidity 合约的内部逻辑)。
调度器(dispatcher)
感谢Faheel (721Orbit)为本文撰写本节内容并提供CLI中的插图。
你有没有想过,你的智能合约在收到calldata时如何知道要执行哪个外部/公共函数?
正如我们所看到的,一个合约的EVM字节码的结构本身就包含了大量的数据,即使是它发出的一个小的Ownable合约。
其中一个相当小但重要的部分是一个调度器。让我们以一个Ownable合约为例,看看调度器如何工作。下面是代码:
pragma solidity >= 0.7 .0 < 0.9 .0;
contract Ownable {
address private owner;
// event for EVM logging
event OwnerSet(address indexed oldOwner, address indexed newOwner);
// modifier to check if caller is owner
modifier isOwner() {
require(msg.sender == owner, "Caller is not owner");
_;
}
/**
* @dev Set contract deployer as owner
*/
constructor() {
owner = msg.sender; // 'msg.sender' is sender of current call, contract
// deployer for a constructor
emit OwnerSet(address(0), owner);
}
/**
* @dev Change owner
* @param _newOwner address of new owner
*/
function updateOwner(address _newOwner) external isOwner {
emit OwnerSet(owner, _newOwner);
owner = _newOwner;
}
/**
* @dev Return owner address
* @return address of owner
*/
function getOwner() external view returns(address) {
return owner;
}
}
为了解释什么是调度器以及它是如何工作的,让我们看一下上面的Solidity代码。我们的Ownable合约包含两个外部函数:
- updateOwner(address newOwner) => 四字节的函数签名 = 0x880cdc31.
- getOwner() => 四字节的函数签名 = 0x893d20e8。
如果你用solc命令为这个合约生成运行时字节码,它看起来会是这样的。
solc — bin-runtime Ownable.sol
你将在 CLI 中获得以下运行时字节码作为输出:
这个字节码包含了一堆十六进制代码,如果我们把它分解成代表操作码的代码,就会更有意义。在生成它的反汇编代码时,我们得到合约字节码的所有操作码表示,如下所示:
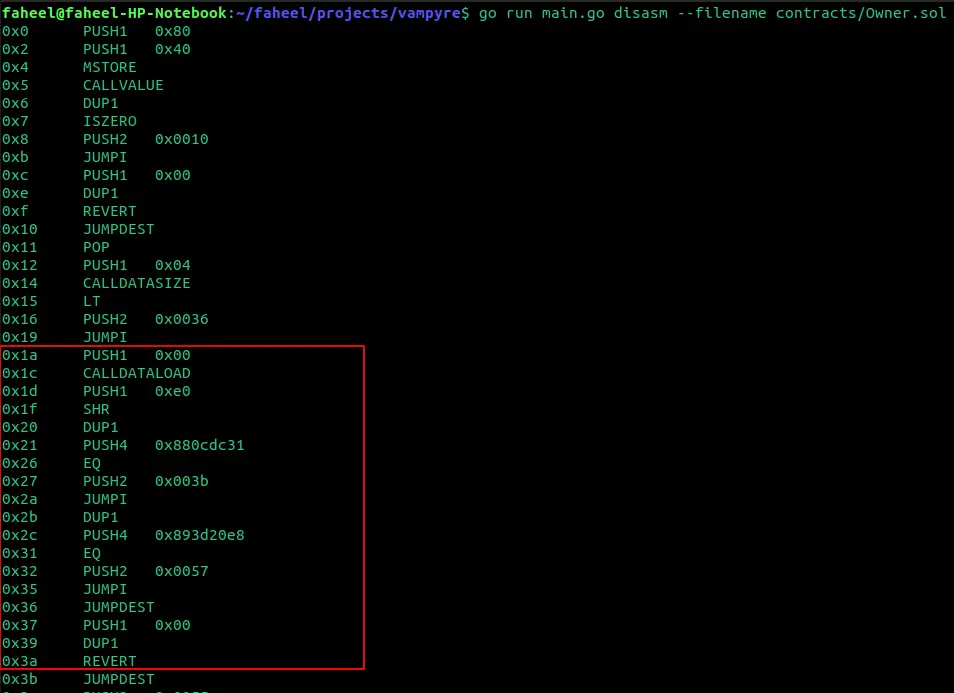
译者注: 反编译工具可以使用: evmasm
整个反汇编代码是相当大的,但我想让你关注红框内的操作码:这个红框代表了我们字节码中的调度器。
那么,什么是调度器?调度器是运行时字节码的一部分,它检查用户要求执行的函数在智能合约中是否存在。使用函数选择器来检查其存在。
- 如果存在性检查通过(意味着该函数存在于合约中),它就会跳转到其函数主体来执行其逻辑。
- 如果没有找到该函数的存在,它要么执行智能合约的 fallback函数,要么在合约不包含 fallback函数的情况下回退(revert)。
那么,调度器是如何工作的?调度器如何找到要执行的函数?
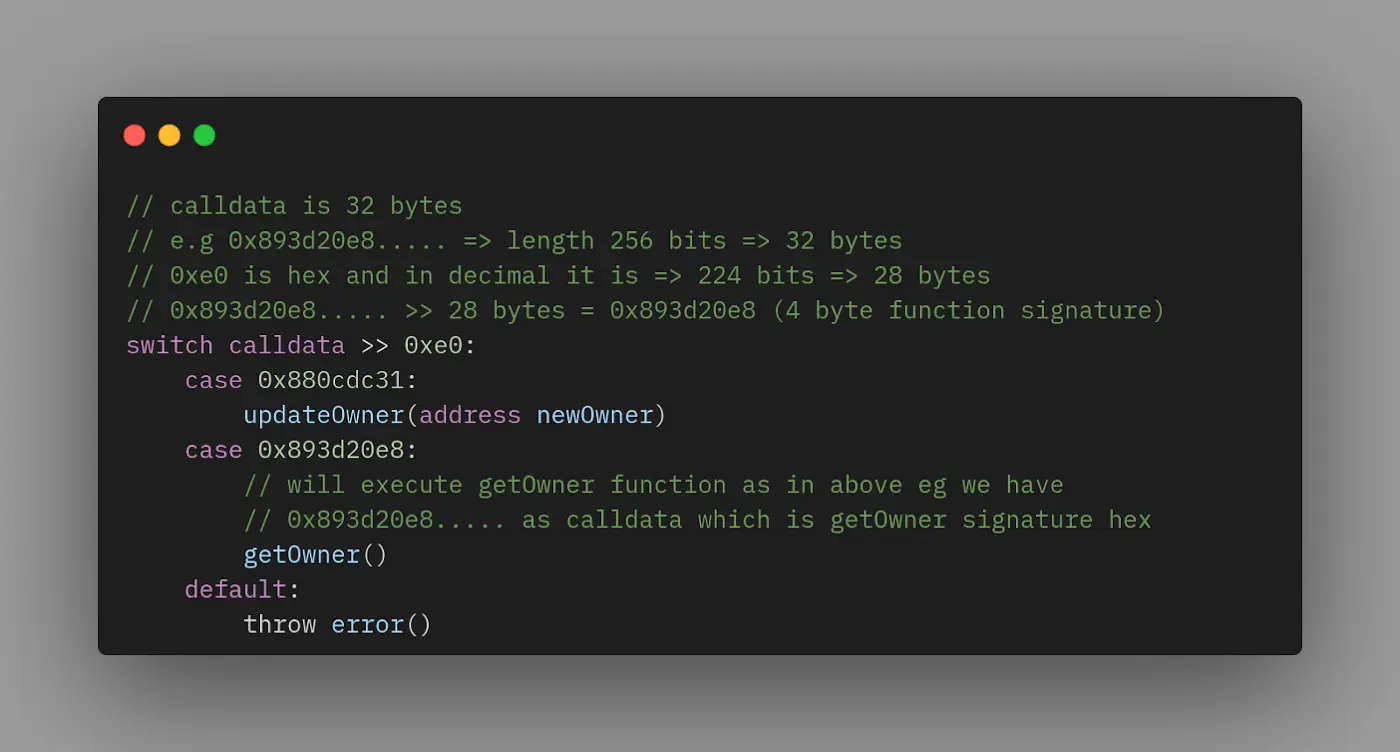
让我们再仔细看一下反汇编。如果用户想执行我们合约中的getOwner函数,函数调用calldata将是0x893d20e8...。
调度器包含所有的函数签名。如果你看一下下面调度器中0x21和0x2c的位置,他是updateOwner(address newOwner)和getOwner()的函数签名。
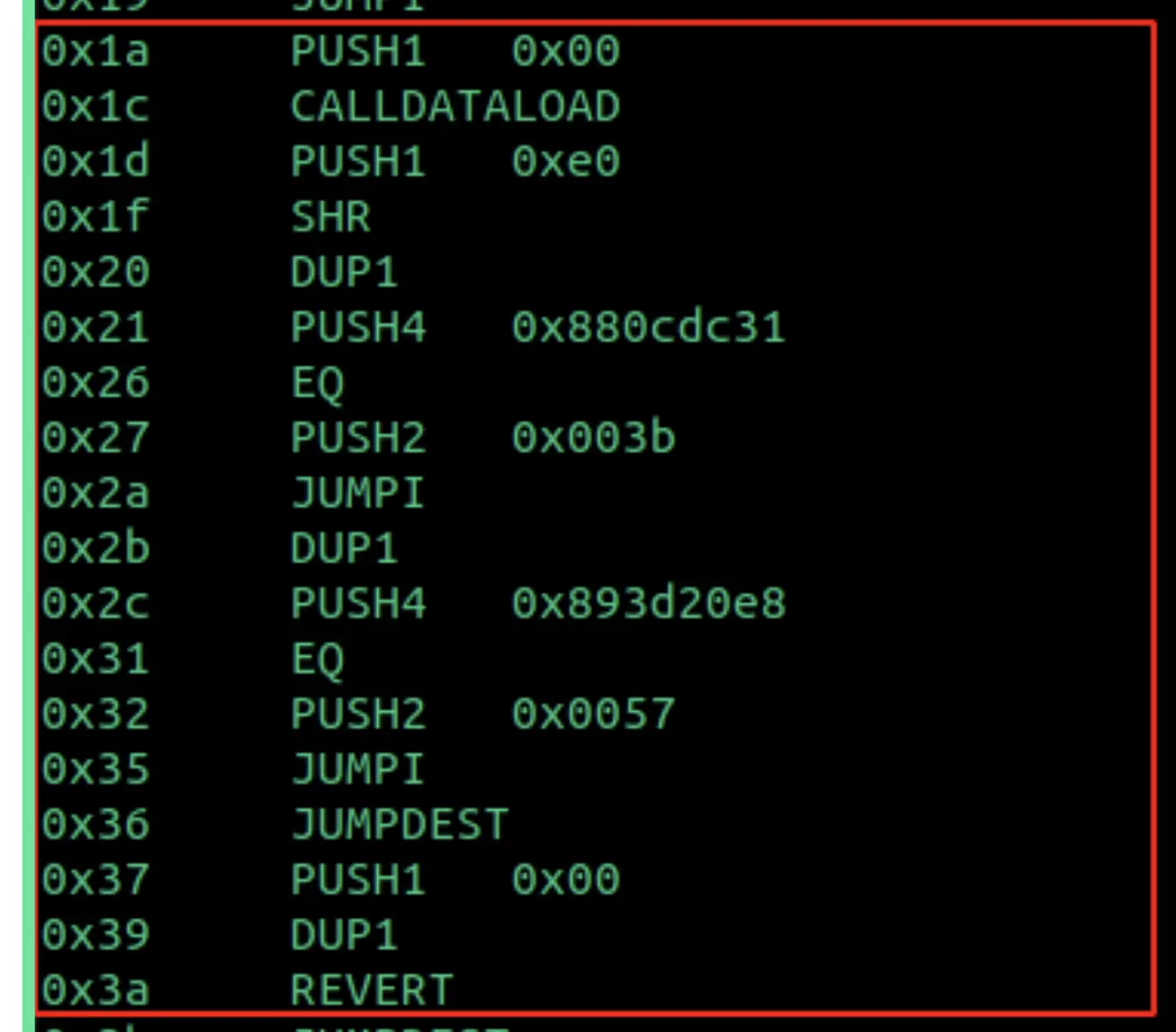
根据反汇编,调度器将开始比较(使用EQ opcode)我们的calldata和里面所有的函数签名。
- 如果它与位置0x21的函数签名相匹配,它将跳到字节码中0x003b的位置,执行updateOwner(address newOwner)的逻辑。
- 如果它与位置0x2c的函数签名匹配,它将跳转到字节码中的位置0x0057,执行getOwner()的逻辑。
- 如果它不能匹配调度器中定义的任何函数签名,它将revert,如位置0x3a所示。
在我们的例子中,由于我们想执行调度器(dispatcher)中定义的getOwner函数,它将跳到字节码中的0x0057位置,执行那里的任何逻辑。
你可以把调度器想象成一个switchcase语句,就像你在许多编程语言中可能使用过的那样。switch case是如何工作的呢? 它接受 switch 中的数据,并检查它是否与任何定义的 case 相匹配。同样地,我们可以写一些伪代码来描述调度器的样子。下面是一个例子:
智能合约的代码存储在哪里?
代码作为一个数据位置是指合约的字节码,所以你可能想知道这个(字节)代码存储在哪里。
合约代码存储在EVM的什么地方?
这是一个复杂的问题,需要一个指南来解决。正如我们将看到的低层,访问特定地址下的智能合约字节码的路径要经过多个步骤。但让我们先来回顾一下。
在介绍性文章"Solidity教程:关于数据位置 "中,我们强调了EVM中可用的不同数据位置,使用的是精通以太坊一书中的EVM架构图.
其中,存储(以下为绿色)和代码(以下为紫色)是与实际智能合约直接相关的两个数据位置(而内存或calldata 与EVM执行环境有关的)。
指令数据是合约账户状态域的一部分。如果我们再看看下面的EVM架构图,我们可以想象账户状态(每个以太坊地址下的状态)、合约字节码和合约的存储之间的直接联系。
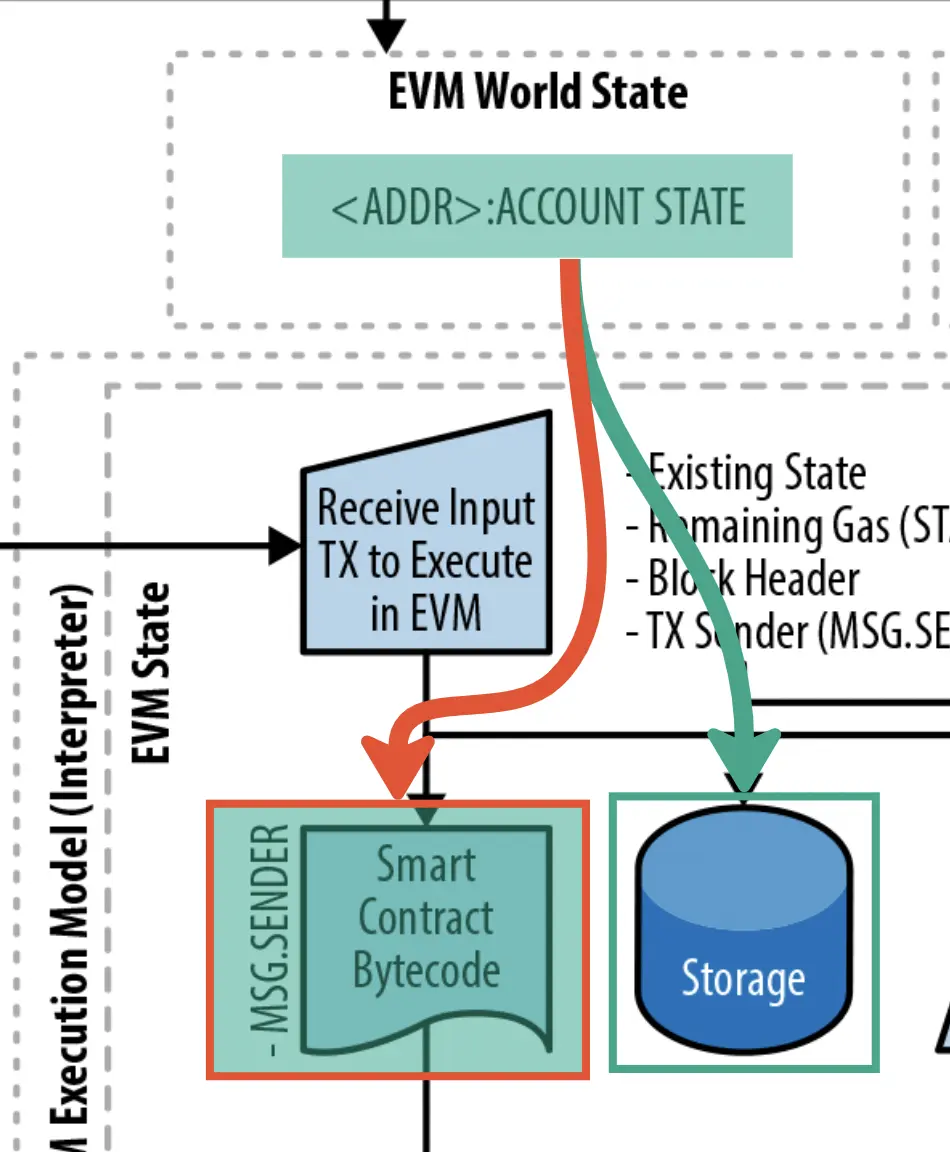
因此,对于 "智能合约的字节码存储/定位在哪里,如何访问?"这个问题的答案很简单,智能合约的字节码存储在账户状态下,在智能合约的地址状态下。
然而,这里面有一个细微的差别!智能合约的字节码不是直接存储在账户状态下。相反,它是被存储的codeHash。
因此,我们接下来要了解合约的字节码存储在哪里的问题是:
- 什么是 codeHash?
- 合约的字节码位于哪里?
- 为什么我们要对智能合约的字节码进行哈希处理?
- 为什么我们要将合约字节码的哈希值存储在账户状态中,而不是直接存储字节码?
回答问题1),codeHash只是合约字节码的keccak256哈希值。
要回答问题2),让我们看看这个图, 节选自黄皮书 详细的EVM架构图。

了解账户状态下的codeHash(来源:以太坊黄皮书,第4页,柏林版)
从上图我们可以看到,账户状态只存储哈希值。无论是合约的存储还是合约的字节码。那么,如果我们只存储合约字节码的哈希值,实际的合约字节码存储在哪里呢?
如上图所示,《黄皮书》指出:"所有这些(合约的)代码片段都包含在状态数据库中,在它们相应的哈希值下。"
这里的 "状态数据库 "指的是什么?
每个以太坊客户端(Geth、Nethermind等)都在底层使用一个底层数据库(leveldb for Geth, rocksdb for Nethermind)。这种基本的底层数据库软件使你能够以基本的键值对来存储数据。数据可以被存储在一个特定的键下。
因此,一个智能合约的字节码被存储在以太坊客户端的底层数据库中,在合约字节码的keccak256哈希值对应的字段下。
最后,是时候回答最后一个问题了,3)和4)。为什么我们要存储合约字节码的哈希值而不是直接存储合约的字节码?
使用codeHash而不是代码的唯一原因是为了性能和优化。
- 出于性能的考虑
当智能合约的 nonce、balance或 storageRoot发生变化时,我们需要再次将合约的账户状态的四个元素重新洗牌("nonce "+"balance "+"storageRoot "+"codeHash")以得到该账户的根。
如果我们使用代码而不是codeHash,我们将不得不“重洗”所有的字段,导致一个更昂贵的计算,而只是使用codeHash,永远不会改变。
- 为了优化以节省底层数据库的空间
当多个智能合约有相同的代码/字节码时(例如,10个智能合约部署在10个不同的地址),我们可以在codeHash下只保存一次字节码,在每个智能合约地址下保存codeHash,而不是在每个地址下保存相同的字节码10次。这就避免了多次存储相同的数据,减少了以太坊客户端的底层数据库所使用的磁盘空间。
创建与运行时代码
注意:你会在网上发现,"代码 "或 "字节码 "这两个词是可以互换使用的。所以:
- "创建代码(creation code)"或 "创建字节码(creation bytecode)"指的是同一件事。
- "运行时代码(runtime code)"或 "运行时字节码(runtime bytecode)"指的是同一件事。
以太坊上只有两种类型的字节码,但有五种不同的名称来描述它们。 - Shane Fontaine
围绕着以太坊的合约代码/字节码的概念,有很多不同的术语。本节旨在简要地澄清这些术语。欲了解更多细节,请参考这篇出色的文章--"了解以太坊的字节码。"
正如作者 Shane Fontaine 所解释的,"字节码 "是一个 "总括术语",包括运行时和创建字节码。
然而,当你深入研究以太坊上的智能合约、EVM以及此类合约如何部署在以太坊区块链上时,你会发现有两个不同的概念。
智能合约有两种类型的代码,如下图所示:
- 创建代码:这是合约的字节码,包括部署合约的指令和运行 constructor逻辑。
- 运行时代码:一旦它被部署到区块链上, 这是合约的最终字节码。
主要区别在于,创建代码只在合约部署时运行一次。相比之下,合约运行时代码是保存在网络上的合约的字节码,一旦合约被调用就会执行。在外部调用触发了合约时,运行时代码是EVM运行的代码。
你也会在网上找到描述创建或运行时代码的替代术语。
- "初始代码" = 创建代码
- "部署的字节码" = 运行时代码
让我们更仔细地看一下创建和运行时代码。
创建代码
创建字节码相当于创建合约的交易的输入数据,只要该交易的唯一目的是创建合约。
创建代码包括 "构造函数"逻辑及其参数。
但是,关于创建代码,最重要的一件事是:
创建代码是生成运行时字节码的代码。
在前面这句话中,有一个重要的词需要注意, "生成"。
创建代码不仅包含运行构造函数的逻辑,还包含返回“合约运行时代码”的逻辑,并将此字节码保存在区块链上已部署智能合约的地址下。这就是为什么它被命名为 "创建 "代码。
在下面的部分,我们将看到这一点是完成的。让我们先来看看运行时代码和额外的差异。
运行时代码
合约的运行时代码是存储在链上的智能合约的字节码,在部署的智能合约的地址下。
当你与区块链上的智能合约交互时,运行时代码是你通过外部调用(来自EOA或其他智能合约)的 "运行代码"。
与创建代码不同,运行时代码不包括 constructor的逻辑。只是因为由于 constructor只运行一次(当合约被部署时),解析 constructor逻辑的EVM字节码指令只在合约被创建时进行。
创建与运行时代码 -- 看到工件(artifacts)的区别
让我们看一个具体的例子来直观地区分智能合约的创建和运行时代码。
通常,创建代码比运行时代码更大(包含更多的字节),因为它包含 "构造函数 "逻辑+返回和保存合约字节码的逻辑。
让我们来看看下面这个Solidity智能合约的例子。
// SPDX-License-Identifier: Apache-2.0
pragma solidity ^ 0.8 .0;
contract MyContract {
string internal _myName;
constructor(string memory initialName) {
_myName = initialName;
}
function setName(string memory name) public {
_myName = name;
}
function getName() public view returns(string memory) {
return _myName;
}
}
如果我们比较创建代码和运行时代码,我们可以看到创建代码比运行时代码更大,包含更多字节。这是因为如前所述,创建时包含以下内容:
- 我们合约的 构造函数 的逻辑(在我们的例子中,将状态变量_myName设置为initialName)。
- 返回和保存智能合约在区块链上的运行时字节码的逻辑(下一节会有更多介绍)
请看下面的区别。我将与这两部分有关的字节码用粗体字标出。
Note: the creation and bytecode of this contract was compiled using
solc version 0.8.15 with the optimiser on and the number of runs set to 1,000.
Creation Code
0x
608060405234801561001057600080fd5b5060405161062938038061062983398101604081905261002f91610058565b600061003b82826101b0565b505061026f565b634e487b7160e01b600052604160045260246000fd5b6000602080838503121561006b57600080fd5b82516001600160401b038082111561008257600080fd5b818501915085601f83011261009657600080fd5b8151818111156100a8576100a8610042565b604051601f8201601f19908116603f011681019083821181831017156100d0576100d0610042565b8160405282815288868487010111156100e857600080fd5b600093505b8284101561010a57848401860151818501870152928501926100ed565b8284111561011b5760008684830101525b98975050505050505050565b600181811c9082168061013b57607f821691505b60208210810361015b57634e487b7160e01b600052602260045260246000fd5b50919050565b601f8211156101ab57600081815260208120601f850160051c810160208610156101885750805b601f850160051c820191505b818110156101a757828155600101610194565b5050505b505050565b81516001600160401b038111156101c9576101c9610042565b6101dd816101d78454610127565b84610161565b602080601f83116001811461021257600084156101fa5750858301515b600019600386901b1c1916600185901b1785556101a7565b600085815260208120601f198616915b8281101561024157888601518255948401946001909101908401610222565b508582101561025f5787850151600019600388901b60f8161c191681555b5050505050600190811b01905550565b6103ab8061027e6000396000f3fe608060405234801561001057600080fd5b50600436106100365760003560e01c806317d7de7c1461003b578063c47f002714610059575b600080fd5b61004361006e565b6040516100509190610110565b60405180910390f35b61006c61006736600461017b565b610100565b005b60606000805461007d9061022c565b80601f01602080910402602001604051908101604052809291908181526020018280546100a99061022c565b80156100f65780601f106100cb576101008083540402835291602001916100f6565b820191906000526020600020905b8154815290600101906020018083116100d957829003601f168201915b5050505050905090565b600061010c82826102b5565b5050565b600060208083528351808285015260005b8181101561013d57858101830151858201604001528201610121565b8181111561014f576000604083870101525b50601f01601f1916929092016040019392505050565b634e487b7160e01b600052604160045260246000fd5b60006020828403121561018d57600080fd5b813567ffffffffffffffff808211156101a557600080fd5b818401915084601f8301126101b957600080fd5b8135818111156101cb576101cb610165565b604051601f8201601f19908116603f011681019083821181831017156101f3576101f3610165565b8160405282815287602084870101111561020c57600080fd5b826020860160208301376000928101602001929092525095945050505050565b600181811c9082168061024057607f821691505b60208210810361026057634e487b7160e01b600052602260045260246000fd5b50919050565b601f8211156102b057600081815260208120601f850160051c8101602086101561028d5750805b601f850160051c820191505b818110156102ac57828155600101610299565b5050505b505050565b815167ffffffffffffffff8111156102cf576102cf610165565b6102e3816102dd845461022c565b84610266565b602080601f83116001811461031857600084156103005750858301515b600019600386901b1c1916600185901b1785556102ac565b600085815260208120601f198616915b8281101561034757888601518255948401946001909101908401610328565b50858210156103655787850151600019600388901b60f8161c191681555b5050505050600190811b0190555056fea26469706673582212201ce19d00816f93d51e8ec603d254f721cc52796da195e52fe2ba6c928e980e3264736f6c634300080f0033,
Runtime Code
0x608060405234801561001057600080fd5b50600436106100365760003560e01c806317d7de7c1461003b578063c47f002714610059575b600080fd5b61004361006e565b6040516100509190610110565b60405180910390f35b61006c61006736600461017b565b610100565b005b60606000805461007d9061022c565b80601f01602080910402602001604051908101604052809291908181526020018280546100a99061022c565b80156100f65780601f106100cb576101008083540402835291602001916100f6565b820191906000526020600020905b8154815290600101906020018083116100d957829003601f168201915b5050505050905090565b600061010c82826102b5565b5050565b600060208083528351808285015260005b8181101561013d57858101830151858201604001528201610121565b8181111561014f576000604083870101525b50601f01601f1916929092016040019392505050565b634e487b7160e01b600052604160045260246000fd5b60006020828403121561018d57600080fd5b813567ffffffffffffffff808211156101a557600080fd5b818401915084601f8301126101b957600080fd5b8135818111156101cb576101cb610165565b604051601f8201601f19908116603f011681019083821181831017156101f3576101f3610165565b8160405282815287602084870101111561020c57600080fd5b826020860160208301376000928101602001929092525095945050505050565b600181811c9082168061024057607f821691505b60208210810361026057634e487b7160e01b600052602260045260246000fd5b50919050565b601f8211156102b057600081815260208120601f850160051c8101602086101561028d5750805b601f850160051c820191505b818110156102ac57828155600101610299565b5050505b505050565b815167ffffffffffffffff8111156102cf576102cf610165565b6102e3816102dd845461022c565b84610266565b602080601f83116001811461031857600084156103005750858301515b600019600386901b1c1916600185901b1785556102ac565b600085815260208120601f198616915b8281101561034757888601518255948401946001909101908401610328565b50858210156103655787850151600019600388901b60f8161c191681555b5050505050600190811b0190555056fea26469706673582212201ce19d00816f93d51e8ec603d254f721cc52796da195e52fe2ba6c928e980e3264736f6c634300080f0033
关于生成的创建/运行时代码的说明
请注意,生成的创建和运行时代码基于多种因素而变化,包括:
- 你用来编译你的 Solidity 智能合约的 solc 编译器的版本
- solc编译器的优化器被设置是否开启 。
- 优化器的配置,如 (RUNS 的数量)。
- 当合约被部署时,提供给 "构造函数 "的参数。
合约(运行时)代码是如何生成的
我们现在看到了智能合约的两类代码:创建和运行时代码。
但任何Solidity开发者都会遇到的一个主要问题是。"智能合约的代码是如何创建的?"
为了理解这个概念,我们需要了解创建和运行时代码之间的关系。之前,我们看到,"创建代码是生成运行时代码的代码"。
因此,第一步是了解在创建代码中发生了什么。
我们将通过部署一个智能合约和调试部署交易来研究这个问题。但我们首先要看的是,在没有 constructor的情况下,创建代码与运行时代码之间的区别!
当我们部署一个不包含 constructor的合约时,创建代码仍然比运行时代码大。这意味着在部署合约时,除了 constructor逻辑外,仍有一些事情要做。
它们是什么?理解这些指令是理解EVM如何部署合约和回答上述问题的关键。"创建代码是如何从运行时代码中生成的"。
让我们再看看我们之前的 MyContract 例子的略微修改版的创建代码。但是这一次没有constructor,它用一个初始值初始化了状态变量myName。
Note: the creation and bytecode of this contract was compiled using solc
version 0.8.15 with the optimiser on and the number of runs set to 1,000.
// SPDX-License-Identifier: Apache-2.0
pragma solidity ^0.8.0;
contract MyContract {
string internal _myName;
function setName(string memory name) public {
_myName = name;
}
function getName() public view returns (string memory) {
return _myName;
}
}
Creation Code
0x 608060405234801561001057600080fd5b506103ab806100206000396000f3fe
608060405234801561001057600080fd5b50600436106100365760003560e01c806317d7de7c1461003b578063c47f002714610059575b600080fd5b61004361006e565b6040516100509190610110565b60405180910390f35b61006c61006736600461017b565b610100565b005b60606000805461007d9061022c565b80601f01602080910402602001604051908101604052809291908181526020018280546100a99061022c565b80156100f65780601f106100cb576101008083540402835291602001916100f6565b820191906000526020600020905b8154815290600101906020018083116100d957829003601f168201915b5050505050905090565b600061010c82826102b5565b5050565b600060208083528351808285015260005b8181101561013d57858101830151858201604001528201610121565b8181111561014f576000604083870101525b50601f01601f1916929092016040019392505050565b634e487b7160e01b600052604160045260246000fd5b60006020828403121561018d57600080fd5b813567ffffffffffffffff808211156101a557600080fd5b818401915084601f8301126101b957600080fd5b8135818111156101cb576101cb610165565b604051601f8201601f19908116603f011681019083821181831017156101f3576101f3610165565b8160405282815287602084870101111561020c57600080fd5b826020860160208301376000928101602001929092525095945050505050565b600181811c9082168061024057607f821691505b60208210810361026057634e487b7160e01b600052602260045260246000fd5b50919050565b601f8211156102b057600081815260208120601f850160051c8101602086101561028d5750805b601f850160051c820191505b818110156102ac57828155600101610299565b5050505b505050565b815167ffffffffffffffff8111156102cf576102cf610165565b6102e3816102dd845461022c565b84610266565b602080601f83116001811461031857600084156103005750858301515b600019600386901b1c1916600185901b1785556102ac565b600085815260208120601f198616915b8281101561034757888601518255948401946001909101908401610328565b50858210156103655787850151600019600388901b60f8161c191681555b5050505050600190811b0190555056fea2646970667358221220544b267a97e844606584e76ce3c83ab212d24fbb9597f62847f2213b26b2e3c064736f6c634300080f0033
Runtime Code
0x608060405234801561001057600080fd5b50600436106100365760003560e01c806317d7de7c1461003b578063c47f002714610059575b600080fd5b61004361006e565b6040516100509190610110565b60405180910390f35b61006c61006736600461017b565b610100565b005b60606000805461007d9061022c565b80601f01602080910402602001604051908101604052809291908181526020018280546100a99061022c565b80156100f65780601f106100cb576101008083540402835291602001916100f6565b820191906000526020600020905b8154815290600101906020018083116100d957829003601f168201915b5050505050905090565b600061010c82826102b5565b5050565b600060208083528351808285015260005b8181101561013d57858101830151858201604001528201610121565b8181111561014f576000604083870101525b50601f01601f1916929092016040019392505050565b634e487b7160e01b600052604160045260246000fd5b60006020828403121561018d57600080fd5b813567ffffffffffffffff808211156101a557600080fd5b818401915084601f8301126101b957600080fd5b8135818111156101cb576101cb610165565b604051601f8201601f19908116603f011681019083821181831017156101f3576101f3610165565b8160405282815287602084870101111561020c57600080fd5b826020860160208301376000928101602001929092525095945050505050565b600181811c9082168061024057607f821691505b60208210810361026057634e487b7160e01b600052602260045260246000fd5b50919050565b601f8211156102b057600081815260208120601f850160051c8101602086101561028d5750805b601f850160051c820191505b818110156102ac57828155600101610299565b5050505b505050565b815167ffffffffffffffff8111156102cf576102cf610165565b6102e3816102dd845461022c565b84610266565b602080601f83116001811461031857600084156103005750858301515b600019600386901b1c1916600185901b1785556102ac565b600085815260208120601f198616915b8281101561034757888601518255948401946001909101908401610328565b50858210156103655787850151600019600388901b60f8161c191681555b5050505050600190811b0190555056fea2646970667358221220544b267a97e844606584e76ce3c83ab212d24fbb9597f62847f2213b26b2e3c064736f6c634300080f0033
我们可以看到这次的创建代码比以前小。它只比运行时的代码多了几条指令,上面用加粗的黑体字标注。看到这种明显区别的一个好方法是如下:
- 用鼠标选择上面的运行时代码,前缀为0x。
- 在剪贴板中复制该运行时代码。ctrl/cmd+c。
- 使用快捷键CTRL/CMD+F在你的浏览器中打开搜索功能。
- 将运行时的代码粘贴到搜索输入区。
这就是应该出现的图片:

你可以看到,在创建代码的开头还有32个字节:
608060405234801561001057600080fd5b506103ab806100206000396000f3fe
那么,这些是什么?它们是做什么的?如果我们在evm.codes的Playground中粘贴这个字节码,我们会得到以下操作码的序列:
[00] PUSH1 80
[02] PUSH1 40
[04] MSTORE ; 空闲内存指针
[05] CALLVALUE ; 获取部署时的 msg.value
[06] DUP1 ; since the constructor is non-payable, check that
[07] ISZERO ; we did not send any value when deploying the contract
[08] PUSH2 0010 ; if we did not send any value, all good we continue
[0b] JUMPI ; deploying the contract jump at instruction nb 0x010
[0c] PUSH1 00 ; if we sent a value to the non payable constructor,
[0e] DUP1 ; this is invalid,
[0f] REVERT ; so we revert
[10] JUMPDEST ; <== this is the jump destination defined at instruction [05]
[11] POP ; start fresh with an empty stack
; -----------------------------------------------------------
[12] PUSH2 03ab ; the runtime code is 939 bytes long
; (0x03ab in hex = 939 in decimals)
[15] DUP1 ; param 1 = number of bytes in the contract's code to copy
; (939 bytes). Wee duplicate the previous number)
[16] PUSH2 0020 ; param 2 = offset in the contract code to start copying from
[19] PUSH1 00 ; param 3 = destination offset in memory
[1b] CODECOPY ; the opcode `CODECOPY` consumes the three parameters above
; in plain words, it will copy 939 bytes starting from
; offset 0 in the contract code (= the entire contract bytcode)
; and copy at the offset 0 in memory
[1c] PUSH1 00 ; push the starting offset in memory to return from (0)
[1e] RETURN ; return 939 bytes from memory
[1f] INVALID
isContract()和EXTCODESIZE的注意事项
函数 isContract() 是OpenZeppelin库中最受欢迎的函数之一。它的目的是检查作为参数传递的给定地址是否是EOA或合约。
该函数检查一些代码是否存储在这个地址下:
到OpenZeppelin库的4.4.2版本为止,isContract()使用extcodesize操作码来执行这个检查。
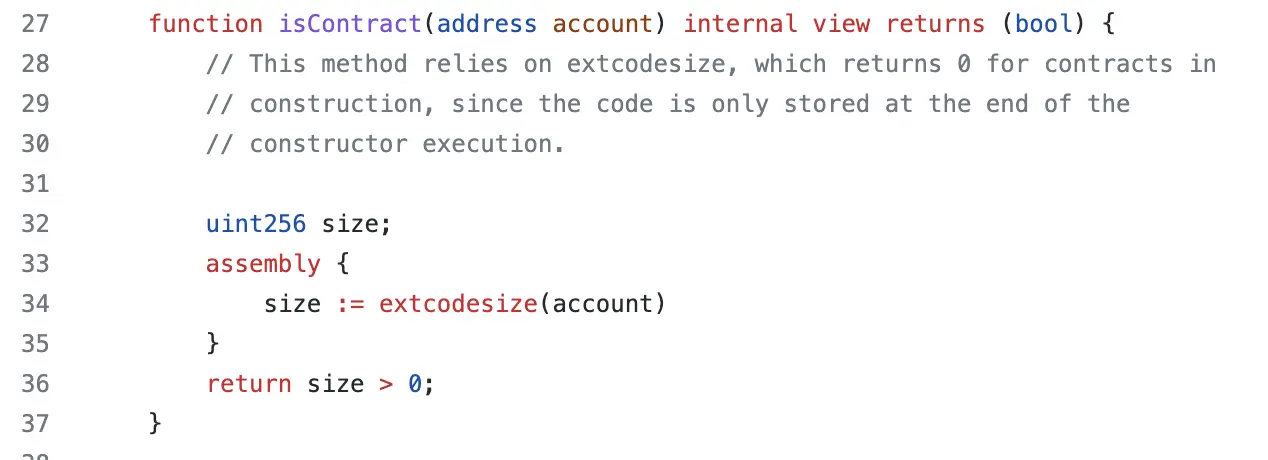
来源:Github OpenZeppelin/contracts version 4.4.2
从4.5.0版本开始,内置的Solidity方法address.code 已经取代了汇编块来执行同样的检查。

但是isContract()函数体内部的注释提供了提示,这个函数包含一些限制和漏洞。让我们来研究一下isContract提出的很多安全方面的考虑。
检查地址是否存在代码并不一定意味着它不是一个智能合约,因为有这样的情况:
- 该函数可能是从一个合约的 constructor中调用的
- 如果被检查的地址可能已经被预先确定,并且合约还没有被部署(使用create2)。
因此,isContract() 函数,总结起来,可以简单归结为:
- 可以假定,如果被检查的地址下有一些代码存储(code.length > 0),该地址是一个智能合约。
- 如果被检查的地址下没有存储任何代码,我们就不能做这个假设,并且可以肯定它不是一个智能合约
这是一个有点棘手的学习话题,但它对智能合约安全的基础知识至关重要。
在 Solidity 中访问合约代码
Solidity有多种方法来访问智能合约的字节码。
-
.codehash.
-
.code
- type(ContractName).creationCode(创建代码)
- type(ContractName).runtimeCode(运行时代码)
.code、.creationCode和.runtimeCode的共同点是它们都返回一个bytes memory值。
这些神奇的属性之间的主要区别是,它们是两种Solidity类型的成员:.code和.codehash是地址类型的成员,而.creationCode和.runtimeCode是合约类型的成员。
这些属性的区别在于,.code和.codehash是从区块链中读取的属性,而.creationCode和.runtimeCode实际上是返回一些bytes memory,在使用它的智能合约字节码中被内联代码。
参考
- Understanding Bytecode on Ethereum
- Don’t Use Openzeppelin’s Address.isContract() to Check Caller’s Address
转载:https://learnblockchain.cn/article/5445



{kind=link}